







李宏毅深度强化学习- Proximal Policy Optimization
李宏毅深度强化学习课程 https://www.bilibili.com/video/av24724071
李宏毅深度强化学习笔记(一)Outline
李宏毅深度强化学习笔记(三)Q-Learning
李宏毅深度强化学习笔记(四)Actor-Critic
李宏毅深度强化学习笔记(五)Sparse Reward
李宏毅深度强化学习笔记(六)Imitation Learning
李宏毅深度强化学习课件
Policy Gradient
术语和基本思想
基本组成:
- actor (即policy gradient要学习的对象, 是我们可以控制的部分)
- 环境 environment (给定的,无法控制)
- 回报函数 reward function (无法控制)
Policy of actor π \pi π:
如下图所示,Policy 可以理解为一个包含参数 θ \theta θ的神经网络,该网络将观察到的变量作为模型的输入,基于概率输出对应的行动action
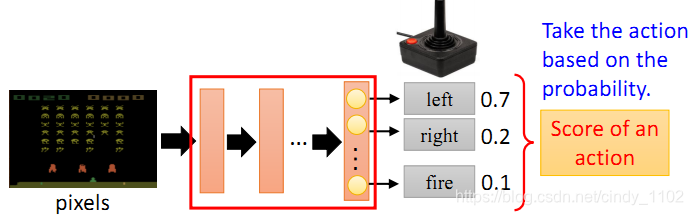
Episode:
游戏从开始到结束的一个完整的回合
actor的目标:
最大化总收益reward
Trajectory τ \tau τ:
行动action和状态state的序列
给定神经网络参数 θ \theta θ的情况下,出现行动状态序列 τ \tau τ的概率:
以下概率的乘积:初始状态出现的概率;给定当前状态,采取某一个行动的概率;以及采取该行动之后,基于该行动以及当前状态返回下一个状态的概率,用公式表示为:
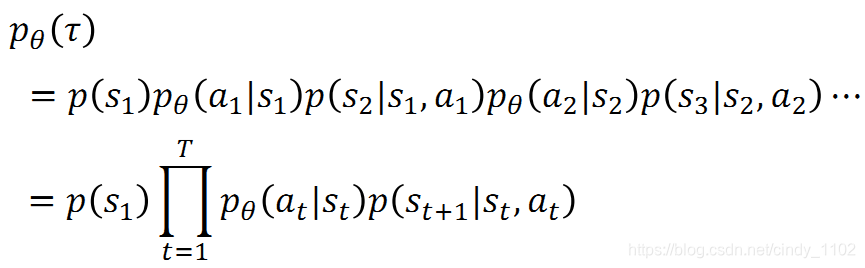
给定一个行动状态序列 τ \tau τ, 我们可以得到它对应的收益reward,通过控制actor,我们可以得到不同的收益。由于actor采取的行动以及给定环境下出现某一个状态state是随机的,最终的目标是找到一个具有最大期望收益(即下述公式)的actor。
累积期望收益:采取某一个行动状态序列 τ \tau τ的概率, 以及该行动状态序列对应的收益reward的乘积之和。
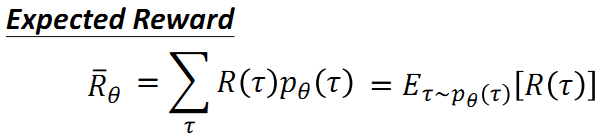
Policy Gradient
得出目标函数之后,就需要根据目标函数求解目标函数最大值以及最大值对应的policy的参数 θ \theta
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









