






作用:
1.高可用,数据冗余。不能够提供读的能力,也不能有局部性原理;
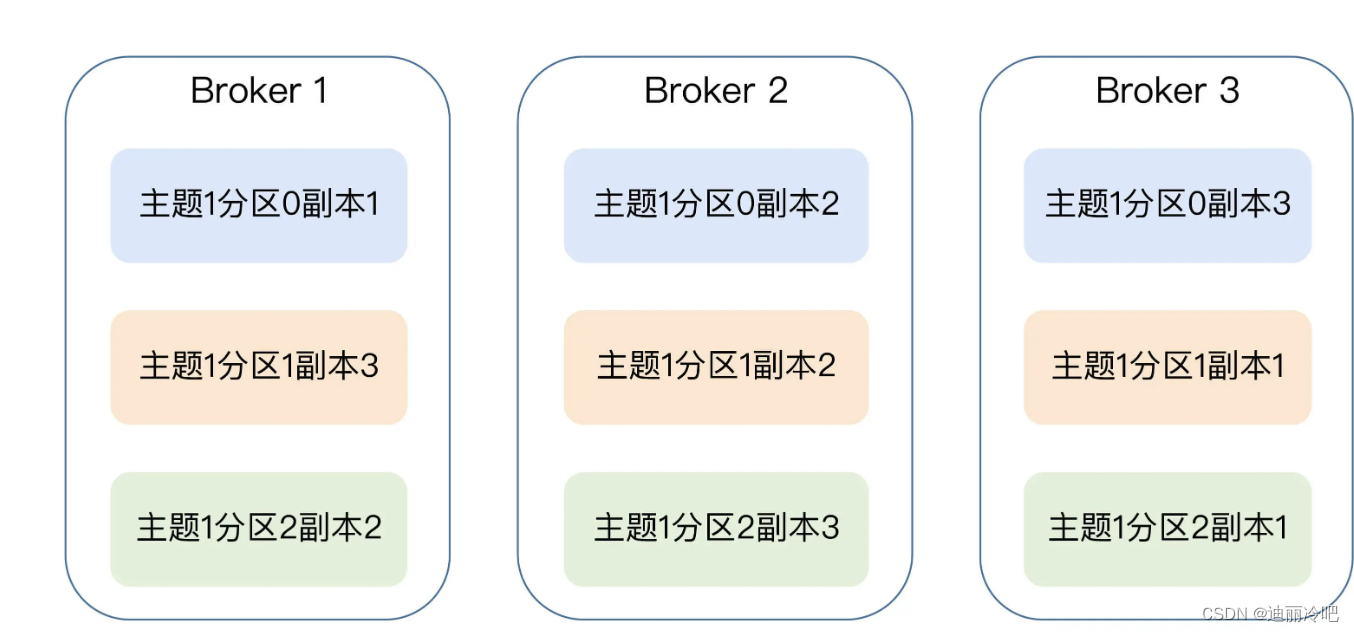 注:同一分区的副本会在不同broker上面;
注:同一分区的副本会在不同broker上面;
副本同步机制:
读写都在领导副本上面,副本通过主动pull的方式在leader副本里面去拿数据;
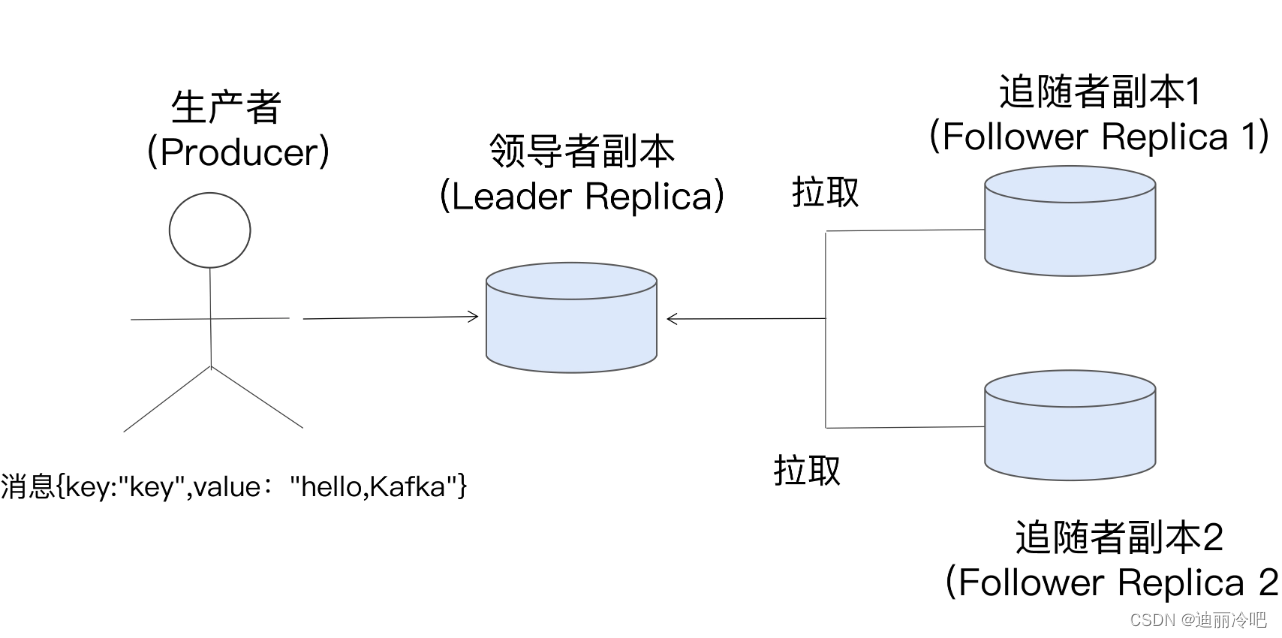
分布式的话出现的问题:
1.领导挂了咋办:
zk能够感知到对应的broker挂掉了,开始进行选主(从ISR,这个定义了和leader的数据可不可以看成同步的,比如落后多少秒没有发fetch操作的就是不同步的,
replica.lag.time.max.ms,是一个动态变化的集合,有人加入,有人跳出。(in SYC replication)里面选(没了的话需要从非ISR集合,也叫非同步副本。里面去选举,Unclean Leader Election));
unclean 选举的影响:
1.提高了可用性2.数据的不一致性;
重平衡:
涉及到的组件:. broker端的coordinator组件
过程:
1.joinGroup;每个消费者加入组,会向coordinator发送 join Group请求。目的收集到组里成员的订阅消息,coordinator选出消费者组的leader(通常是第一个发join Group的消费者),此时joinGroup响应信息会将消费者组的订阅消息发给leader,由leader制定具体的分区消费分配方案;
SyncGroup(领导者把分配方法发给协调者,其他的成员也会发
SyncGroup,只不过是空的,为了让协调者统一把分区分配方案发给所有成员);
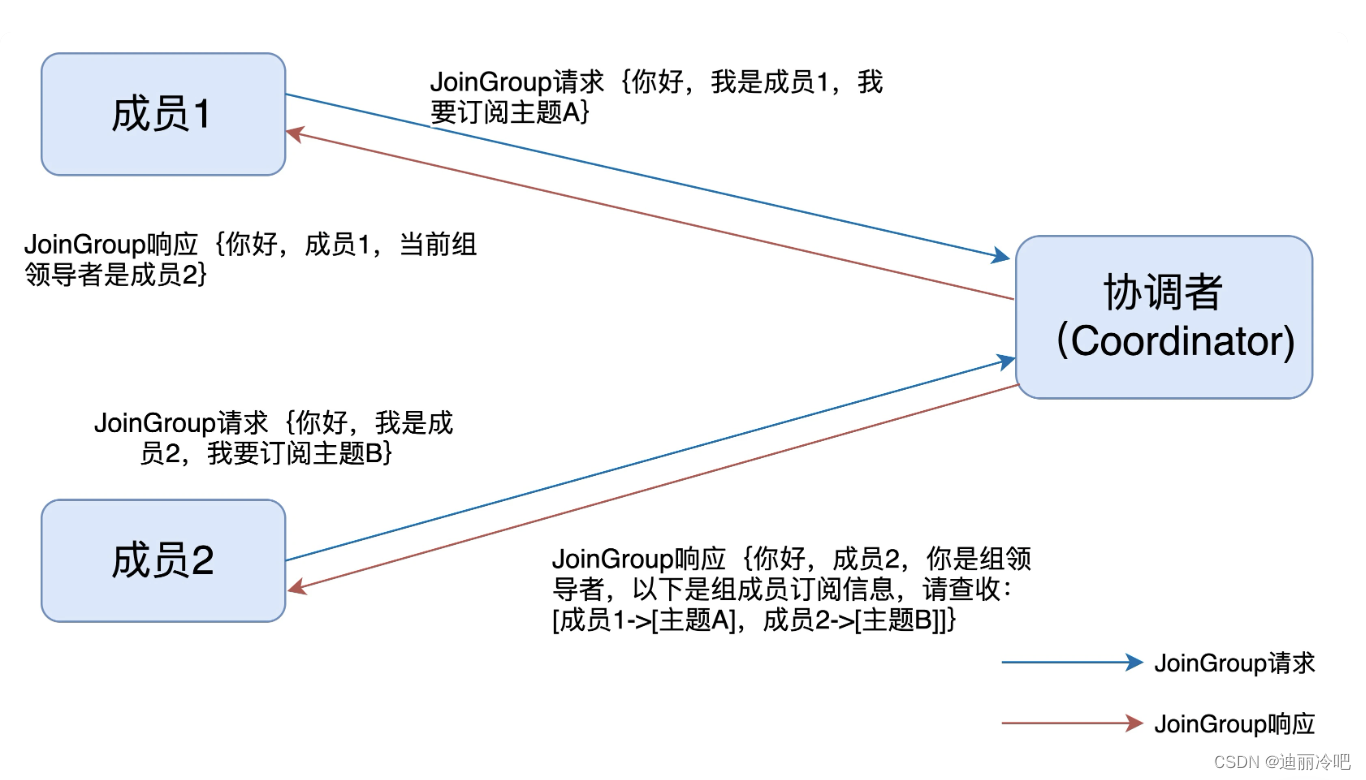
borker端新成员加入的流程:
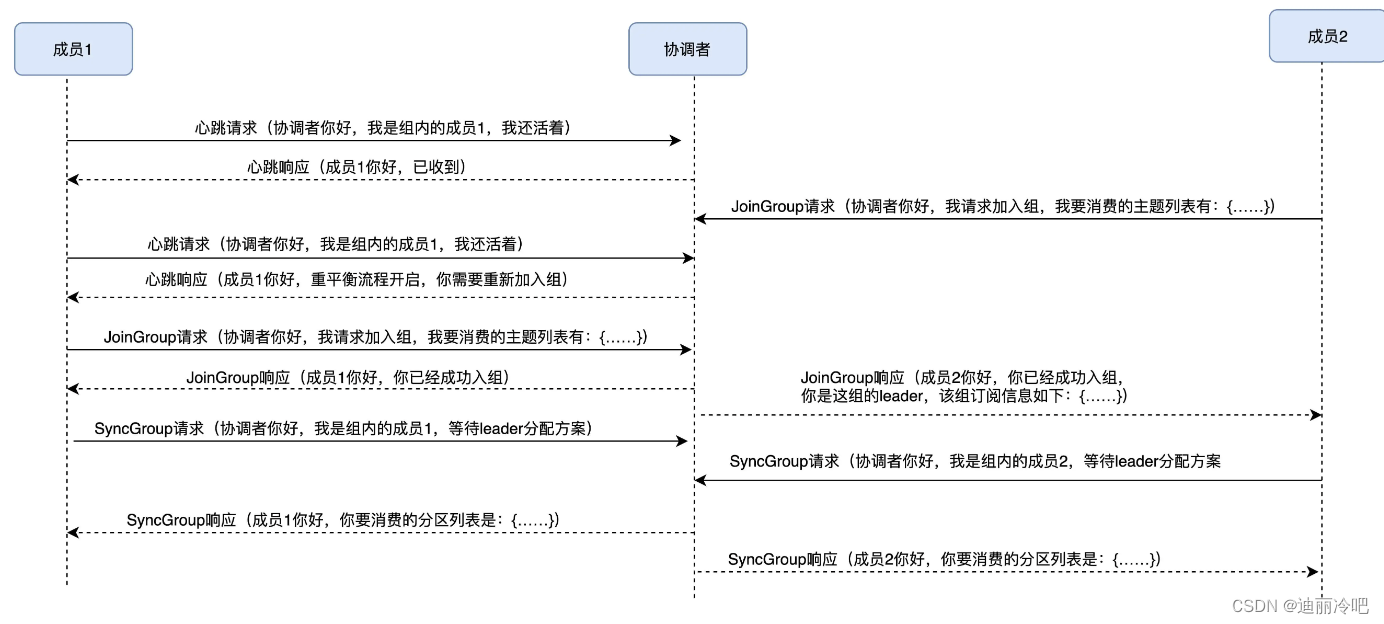
broker端主动退出的流程:
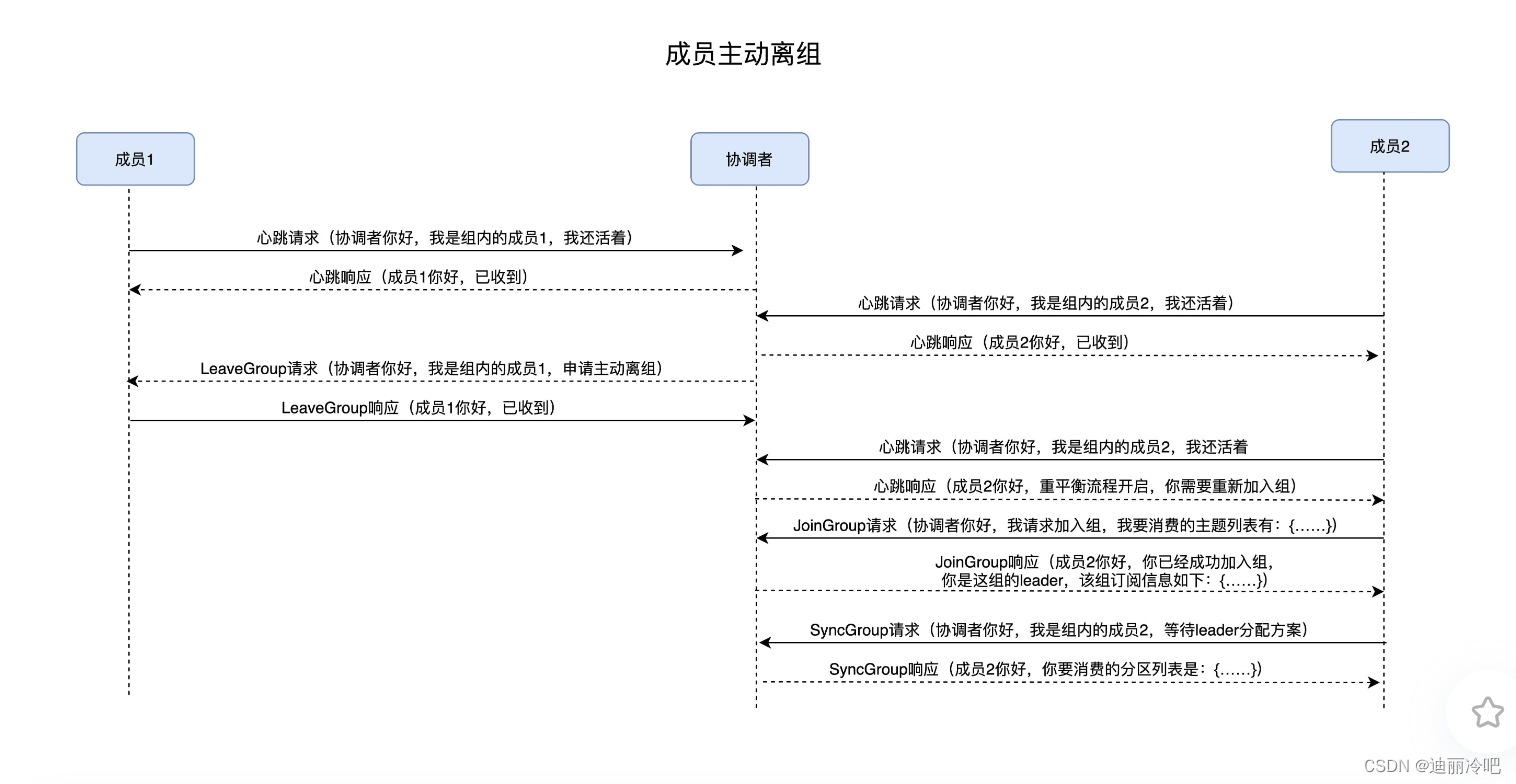 broker 崩溃离组:
broker 崩溃离组:
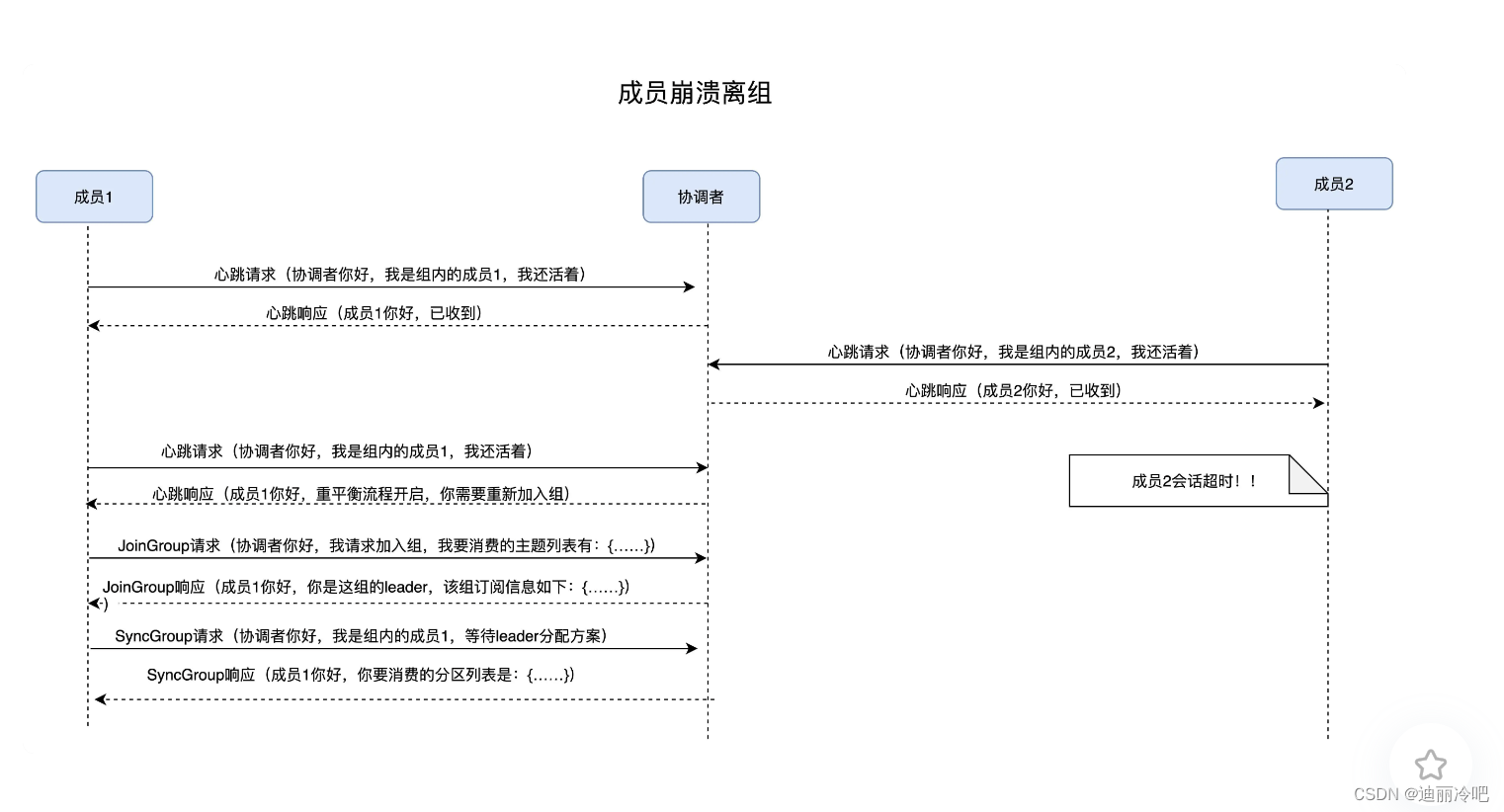
kafka 控制器:
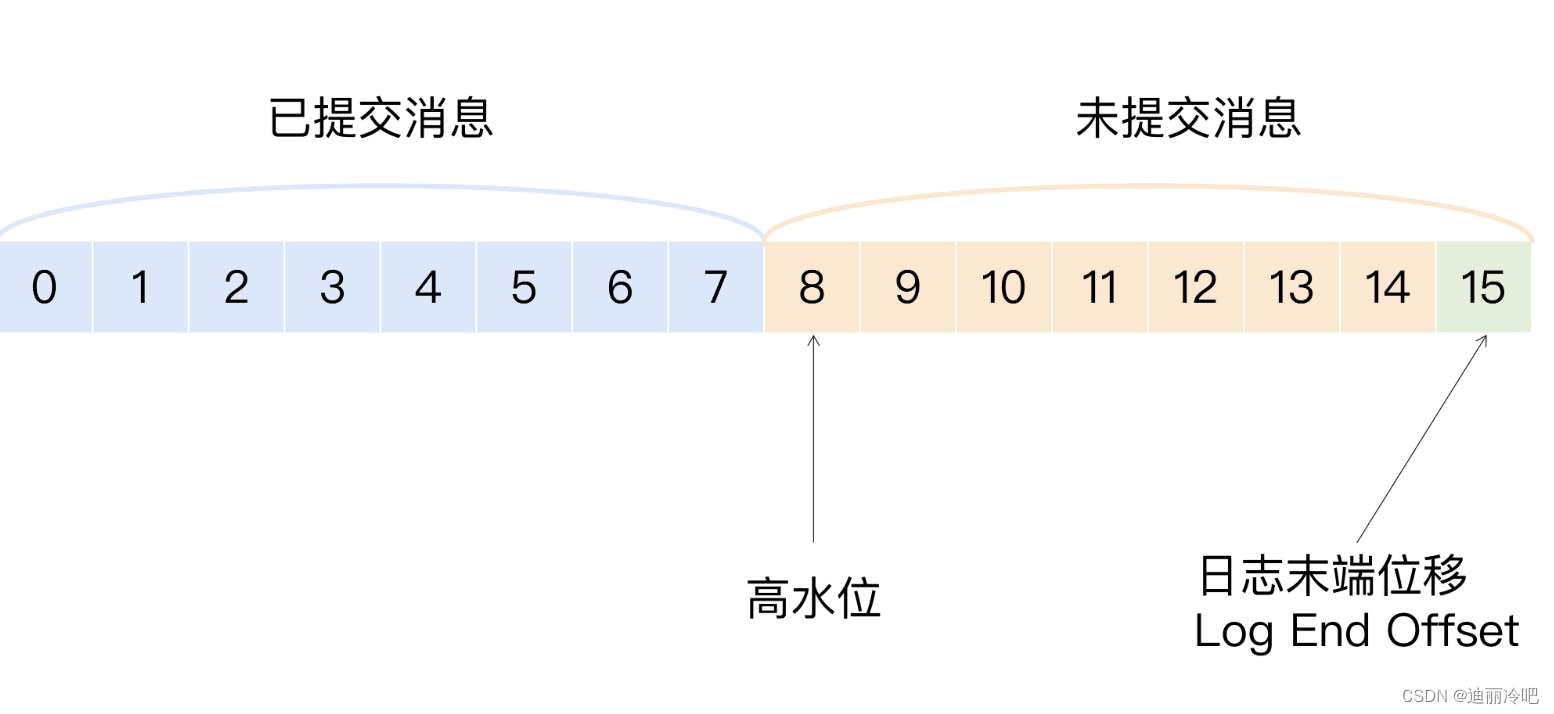
Kafka高水位、低水位
高水位作用:对消费位移节点的描述,定义分区当中哪些消息是可以消费的,位移值大于高水位的说明时未提交的,不能被消费。;帮助完成副本同步;
注:
第一个核心要素是“已提交的消息”。什么是已提交的消息?当 Kafka 的若干个 Broker 成功地接收到一条消息并写入到日志文件后,它们会告诉生产者程序这条消息已成功提交。此时,这条消息在 Kafka 看来就正式变为“已提交”消息了。那为什么是若干个 Broker 呢?这取决于你对“已提交”的定义。你可以选择只要有一个 Broker 成功保存该消息就算是已提交,也可以是令所有 Broker 都成功保存该消息才算是已提交。不论哪种情况,Kafka 只对已提交的消息做持久化保证这件事情是不变的。
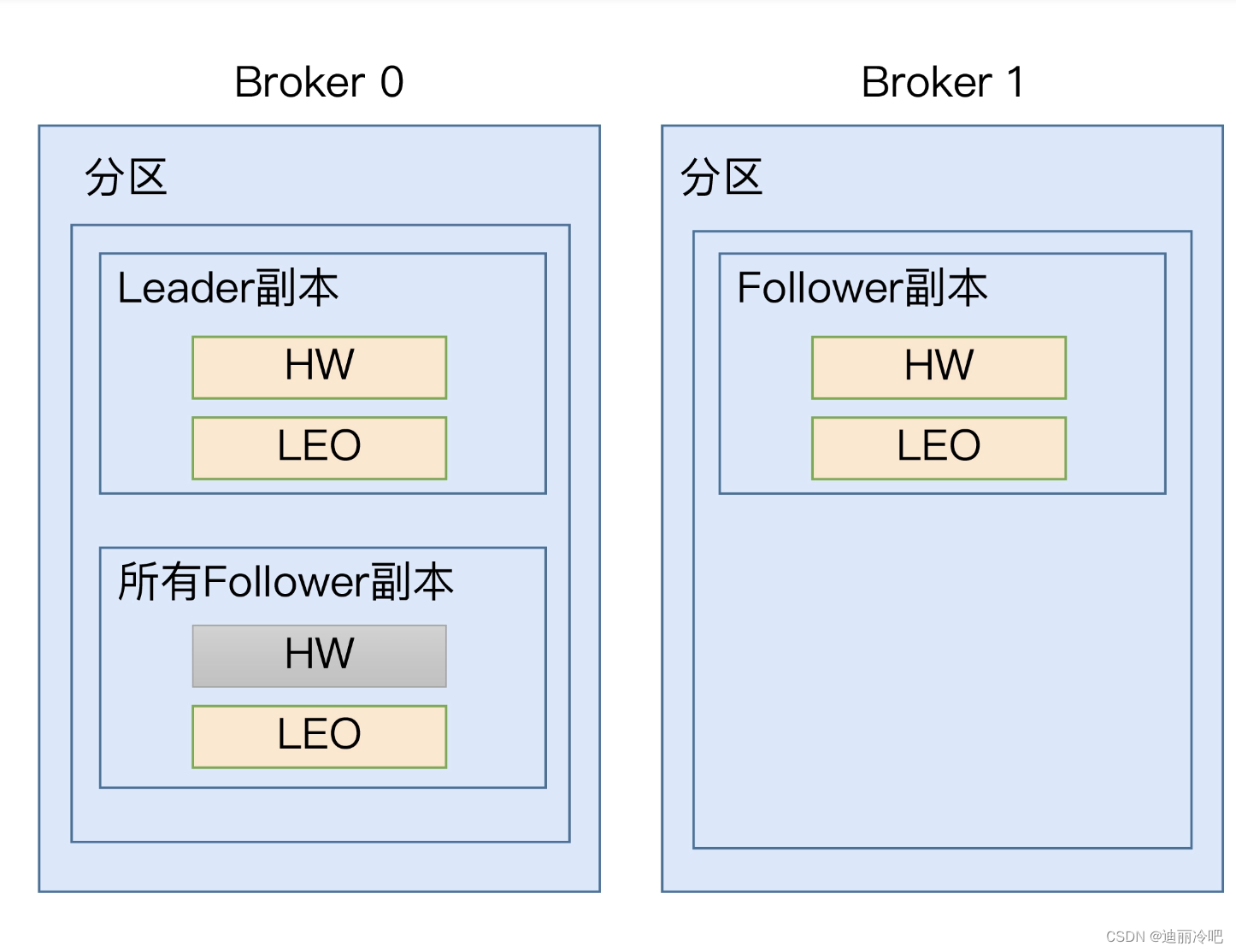
所有副本都会有有高水位和log End,分区的的高水位就是leader副本的高水位。
高水位的更新:
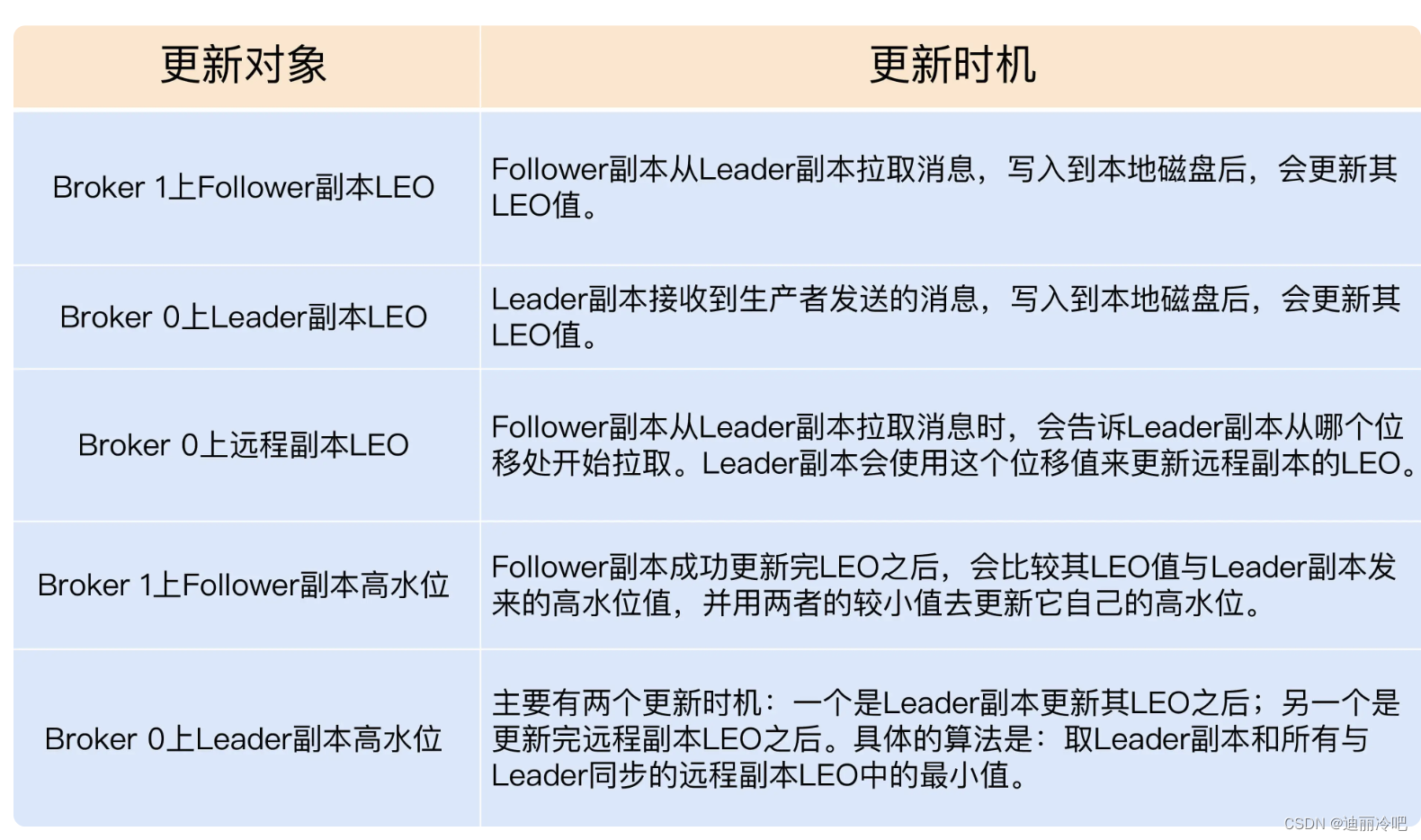
leader epoch:防止数据丢失;
epoch:领导本本更新的话会增加一个一个版本号;
开始位移:leader副本在该epoch上面写入的首条消息的唯一;
broker会在内存里面缓存 leader epoch的信息,定期会把这些信息保存到checkpoint文件中,主要原因,避免数据丢失;每当leader副本写入新的数据,会跟信这个缓存,假如是新的leader,会增加一个条目,并且吧之前的起始位移找出;














 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









