







由西瓜的密度、含糖量推断西瓜的成熟度(0代表生,1代表熟)。
- 编程实现多变量线性回归,给出在西瓜数据集(见表1)上的结果(即 模型参数)。
- 在判断西瓜成熟度这个问题上,请解释密度跟含糖量哪个指标更重要
要求:提交代码(Python),请包含相关语句注释,以及执行结果截图。
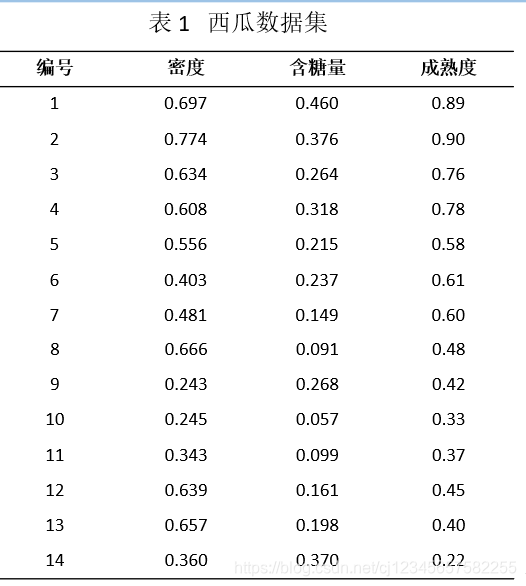
- 编程实现多变量回归,给出在西瓜数据集(表1)上的结果(模型参数)。
假如我们想通过色泽、根蒂和敲击声来判断一下西瓜的成熟度。学习任务变为多变量回归。将不同的指标量化得到上述数据集,过程如下图

因此可以对此数值化后的数据集进行线性回归:


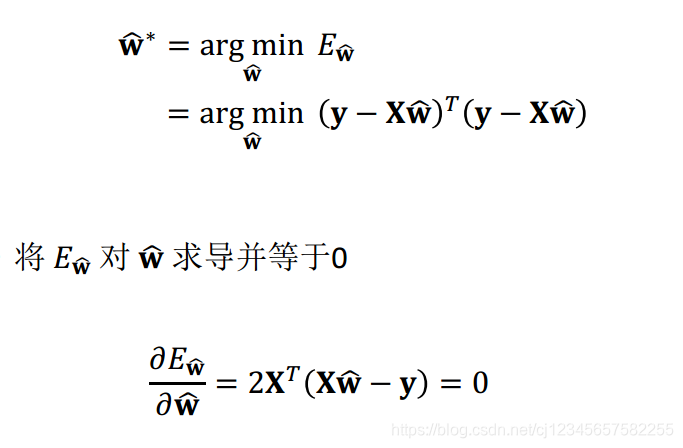
因此直接根据公式计算的代码如下:
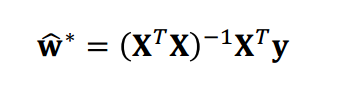
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
xlname=r"C:\Users\34780\Desktop\大二下\机器学习\作业\实验一\西瓜数据
集.xlsx"
data=pd.read_excel(xlname,sheet_name="Sh 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









