






数据
数据data内容如下:
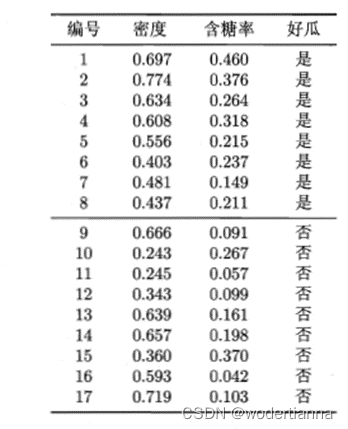
读取数据:
import numpy as np
import pandas as pd
data = pd.read_excel('D:/files/data.xlsx')将汉字转化为01变量:
label = []
for i in data['好瓜']:
l = np.where(i == '是',1,0)
label.append(int(l))
data['label'] = label区分数据集,70%训练集和30%测试集:
from sklearn.model_selection import train_test_split
data_train,data_test = train_test_split(data,test_size=0.3,random_state=0) # random_state是为了保留种子,保证每次跑出来的数都一样
trainx,trainy = data_train[['密度','含糖率']],data_train['label']
testx, testy = data_test[['密度','含糖率']],data_test['label']逻辑回归
逻辑回归主要解决二分类问题,通常称为正向类和负向类(1/0),被解释变量使用逻辑函数(又被称为Sigmoid函数)建模,形成一个特征变量的线性组合函数,逻辑函数总是返回一个0~1之间的概率值,如果该概率等于或大于一个用来区分的阈值(通常是0.5),则被预测为正向类,否则被预测为负向类。逻辑回归(也称对率回归)代码如下:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(trainx,trainy)
model.predict(testx)
model.score(testx,testy) #预测准确度判别分析
判别分析就是一种分类方法,即判断样本所属类别的一种统计方法,判别分析是在已知研究对象分成若干类并已取得各类的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类的方法。判别分析代码实现如下:
#线性判别分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
model = LinearDiscriminantAnalysis()
model.fit(trainx,trainy)
model.score(testx,testy) #预测准确度















 4030
4030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









