







1)
对于fgets()函数
在打开一个文件时,用fgets函数去读取文件的每一行,fgets()函数会系统默认从上次读取的位置开始读取,也可以设置它的指针偏移量来控制每次要读取的哪一行。一般对于要读取一个文件的制定行可以通过判断要读取的字符串,就可以读取到你要取的那一行。
示例代码如下:
#include
#include
#include
int main()
{
FILE *fp;
fp = fopen ("/mnt/hgfs/Linux/dict/dict.txt","r");
while(fgets(RED_buf,MAXLEN_DATA,fp) != NULL){
if (strncmp(RED_buf,pXP->data,strlen(pXP->data)) == 0){
memset (buffer,0x00,sizeof(struct XProtocol));
pXP = (struct XProtocol *)buffer;
strcpy((char *)pXP->data,RED_buf);
write(connfd,buffer,sizeof(struct XProtocol));
}
}
return 0
}
【1】第一种情况:
当定义了一个字符串数组的buff大小,就限定了这个buff能够放几个字符在里面,但是要考虑到的是,
在fgets函数输入时系统会默认在字符串数组的最后一位添加一个'\n',这样一来,当你要放的字符串大小刚刚等于你自己设定的大小是,可能会觉得可以放完你的字符串,可是结果你会发现最后一个字符没有打印出来,这就是系统默认'\n'的原因。
如下图的情况:
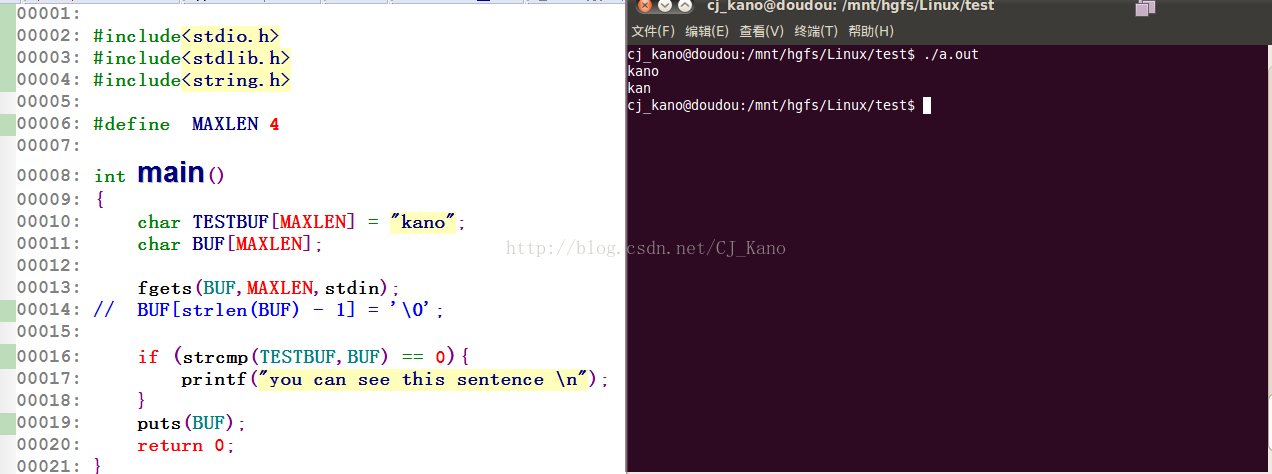
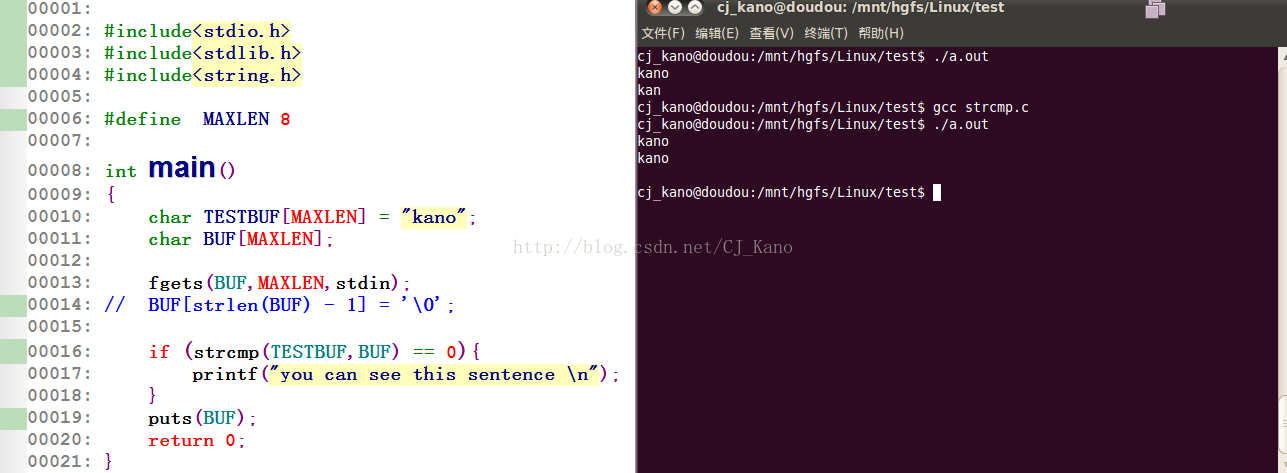
【2】第二种情况当你把buff的大小改为8的时候就可以存放kano的字符串了,你也看到会打印出来两个kano的字符,
可是你会发现没有打印出you can see this sentence 这句话。
对于这是因为strcmp比较两个字符串数组的时候会要求两个字符串完全相同才可以,
对于在定义的时候testbuff中就已经确定字符串的数组会在后面系统默认添加'\0'空字符,
这样表面看来打印在屏幕是两个相同的kano,可是是有很大区别的,只要你仔细看 ,也会发现对于puts函数的输出时会有个换行符造成的空格。这就是fgets函数在标准输入到buff中的所导致的原因。从而导致两个KANO看着相同,却没有打印判断条件里面的一句话。
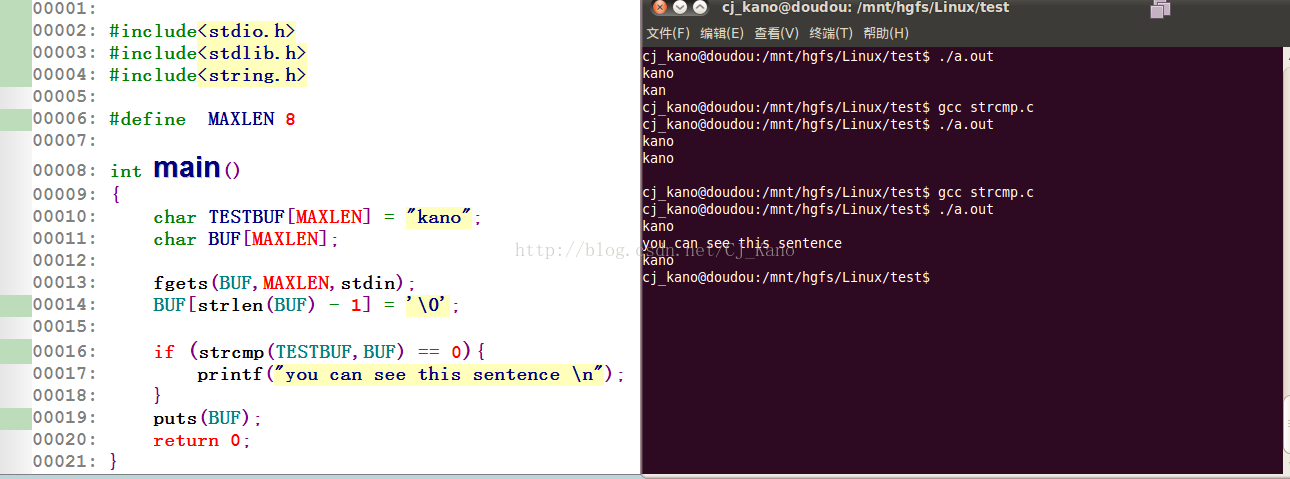
【3】对于这种情况,我们在标准输入之后,再在buf后面把系统添加的'\n'换成''\0'这样两个字符串数组就一样了,就这样打印出判断条件里面的一句话了。
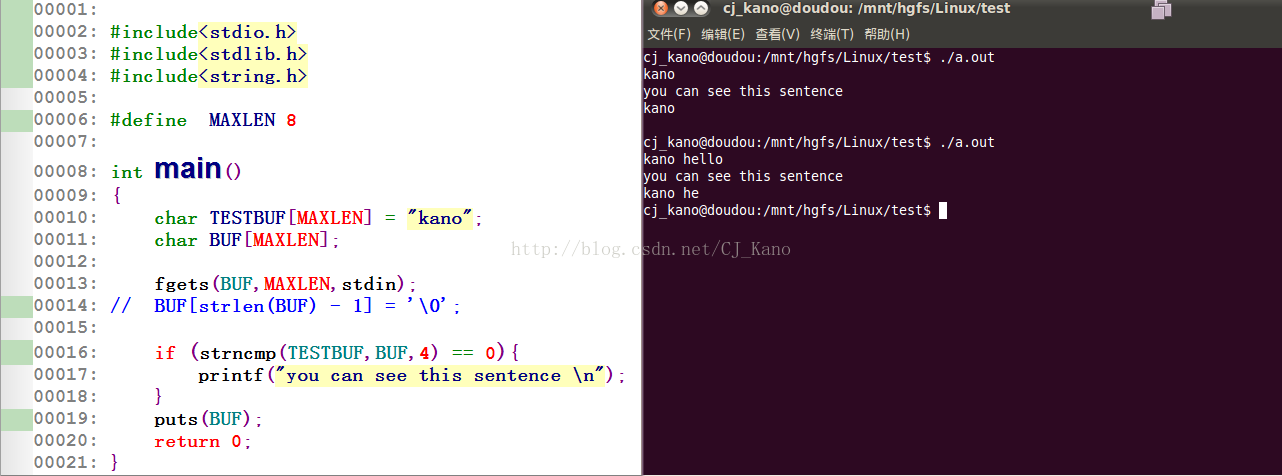
【4】对于strcnmp函数,又会发现一种特殊情况,当我输入kano hello这句话是,也会打印中间的一句话,这是因为strcmp和strcnmp函数的却别,就是strcnmp中间n的含义,表示只比较字符串数组有相同的4个字符一样就导致条件成立,就会打印出中间的一句话。不要求和strcmp函数必须要两个字符串数组完全相同才可以,你也会发现【1】第一种情况,这里只打印了 kano he 六个字符和一个空字符(空格)。















 153
153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









