







1 利用scrapy框架爬取某招聘网站数据分析岗位数据(pycharm+MYSQL)
1.1 scrapy框架基础
1.1.1 scrapy 框架安装

1.1.2 scrapy基本构成
- crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道):负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):类似一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):一个可以自定扩展、操作引擎和Spider中间通信的功能组件。
1.1.3 scrapy项目简单创建
- 打开cmd,输入scrapy startproject job
- cd job 进入文件夹
- scrapy genspider main zhaopinwangzhan.com
- 在与settings同级的文件夹下增加run.py文件,方便在pycharm的控制台显示爬虫
run.py文件内容
from scrapy import cmdline
cmdline.execute('scrapy crawl main'.split())
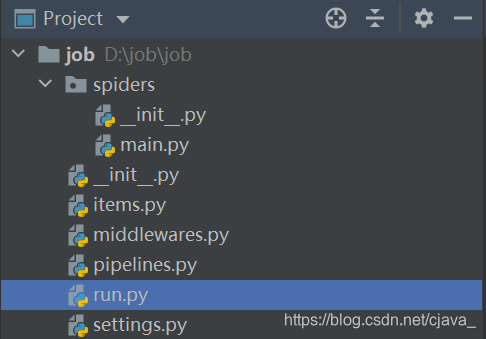
最后文件构成大致如图
1.2 分析本次爬虫爬取需求
1.2.1 爬取内容
某招聘网站数据分析岗位详情页以下信息
职位名 positionName
公司名 companyName
公司类型 companyType
公司规模 companySize
行业 companyind
薪资 salary
城市 city
经验 experience
学历 academic
招聘人数 people_num
福利 jobwelf
任职信息 duty
1.2.2 分析目标网页
1.2.2.1 实现翻页
输入数据分析后搜索的第一页网址:
https://zhaopinwangzhan.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
?后面的内容可以不要,即
https://zhaopinwangzhan.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html?
输入数据分析后搜索的第2页网址:
https://zhaopinwangzhan.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,2.html?
从第一页到第二页,只是变化了一个数字,在代码编写时可以采用拼接的方式实现翻页。
1.2.2.2 获取详情页地址,方便打开网址获取页面信息
我之前用的谷歌浏览器,后来查看网页源代码发现谷歌浏览器的少了一部分,于是我就用360浏览器了,我是戴尔电脑,快捷键fn+F12,也可以右键,然后选择审查元素,点击小箭头,点击后看到详情页链接地址,这里我是使用xpath定位大法,获取每页50个详情链接,再遍历获取
找到链接后右键,复制——xpath,我一般习惯写完整的xpath,也可以不用写完整的
接着按ctrl+F,粘贴刚刚复制的xpath
简单修改一下,可以看到右边显示1/50,说明这个xpath对应的是50条详情页的链接

但是,真正运行后,发现不行,于是查看网页源代码,其实最简便的方法是每一页扒下来然后解析完事,这里还是取xpath
//script[contains(@type,“text/javascript”) and not(@src)]
1.2.2.3 获取详情页自己想要的信息
根据自己想要获取的信息不断获取,这里复制粘贴xpath后要注意,还要加一个text来获取文字内容
1.3 爬虫准备
1.3.1 配置文件
-
items.py 容器,一般根据需求设置数据存储模板,用于结构化数据

-
settings.py 全局配置





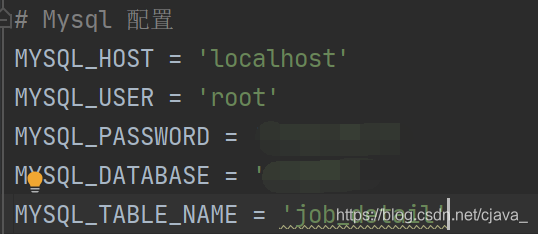
-
pipelines.py 数据持久化处理
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
from itemadapter import ItemAdapter
# 在 pipeline.py 文件中写一个中间件把数据保存在MySQL中
class MysqlPipeline(object):
# from_crawler 中的参数crawler表示这个项目本身
# 通过crawler.settings.get可以读取settings.py文件中的配置信息
@classmethod
def from_crawler(cls, crawler):
cls.host = crawler.settings.get('MYSQL_HOST')
cls.user = crawler.settings.get('MYSQL_USER')
cls.password = crawler.settings.get('MYSQL_PASSWORD')
cls.database = crawler.settings.get('MYSQL_DATABASE')
cls.table_name = crawler.settings.get('MYSQL_TABLE_NAME')
return cls()
# open_spider表示在爬虫开启的时候调用此方法(如开启数据库)
def open_spider(self, spider):
try:
self.db = pymysql.connect(host=self.host, user=self.user, passwd=self.password, database=self.database,
charset='utf8')
self.cursor = self.db.cursor()
print("已连接数据库:", self.db)
except pymysql.err.OperationalError as oe:
print("mysql连接失败:", oe)
print("结束程序!")
sys.exit()
# 连接数据库
# process_item表示在爬虫的过程中,传入item,并对item作出处理
def process_item(self, item, spider):
# 向表中插入爬取的数据 先转化成字典
data = dict(item)
table_name = self.table_name
keys = ','.join(data.keys())
values = ','.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (table_name, keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
# close_spider表示在爬虫结束的时候调用此方法(如关闭数据库)
def close_spider(self, spider):
self.db.close()
# 清洗空格和空行等
class StripPipeline(object):
def process_item(self, item, job_detail):
item['positionName'] = ''.join(item['positionName']).strip()
item['companyName'] = ''.join(item['companyName']).strip()
item['companyType'] = '|'.join(item['companyType']).strip()
item['companySize'] = ''.join(item['companySize']).strip()
item['companyind'] = ''.join(item['companyind']).strip()
item['salary'] = ''.join(item['salary']).strip()
item['city'] = ''.join(item['city']).strip('\xa0\xa0')
item['experience'] = ''.join(item['experience']).strip('\xa0\xa0')
item['academic'] = ''.join(item['academic']).strip('\xa0\xa0')
item['people_num'] = ''.join(item['people_num']).strip('\xa0\xa0')
item['jobwelf'] = ''.join(item['jobwelf']).strip()
item['duty'] = ''.join(item['duty']).strip()
return item
pymysql如果不存在记得安装
1.3.2 配置一下mysql,新建数据库和表
- 登录MySQL
用管理员身份运行cmd或者直接从MySQL的cmd进
- 根据需要创建数据库,我创建的数据库名为data01,然后use
create database 数据库名字 charset = utf-8;
- 根据自己设置的items创建表,我的表的名字是job_detail
CREATE TABLE job_detail(
positionName text COMMENT "职位名",
companyName text COMMENT " 公司名",
companyType text COMMENT " 公司类型",
companySize text COMMENT " 公司规模",
companyind text COMMENT " 薪资",
salary text COMMENT " 薪资",
city text COMMENT "城市",
experience text COMMENT "经验要求",
academic text COMMENT "学历",
people_num text COMMENT "招聘人数",
jobwelf text COMMENT " 福利",
duty text COMMENT " 任职信息"
) ;
4.查看表
select * from job_detail;
但是这个不建议使用,因为数据量很大,很容易玩脱的,后面我下了个navicat,方便多了
1.3.3 编写主要爬虫代码
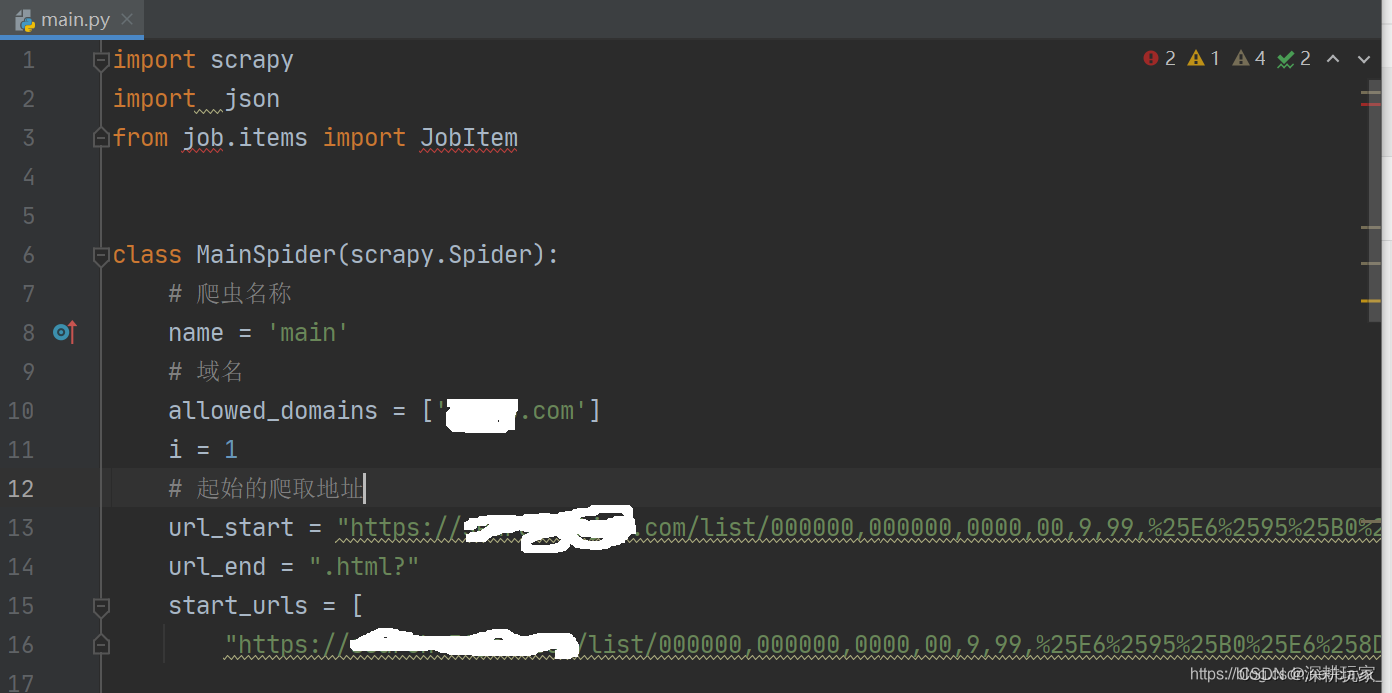
有个地方报错但是无视就好了
1.3.4 运行爬虫
运行run.py文件,就可以看到很多数据被爬取下来啦,我这张图片是已经结束了,最后共爬取100000条数据,但是考虑要和19,20的一些博主的数据比较一下发生的变化,所以没有考虑数据运营、数据录入等等岗位,对数据分析进行模糊匹配,最终有4006条数据待清洗。

2、数据清洗
2.1 工具
Jupyter Notebook



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











