







PTR: Prompt Tuning with Rules for Text Classification
提出背景
Prompt-oriented fine-tuning加速收敛,对少次学习很友好
Prompt-tuning收敛变慢,因为参数变少
Prompt痛点
Hard prompt设计麻烦
Auto prompt 效率太低
Soft prompt 需要大模型来保证效果
Verbalizer 设计也很复杂
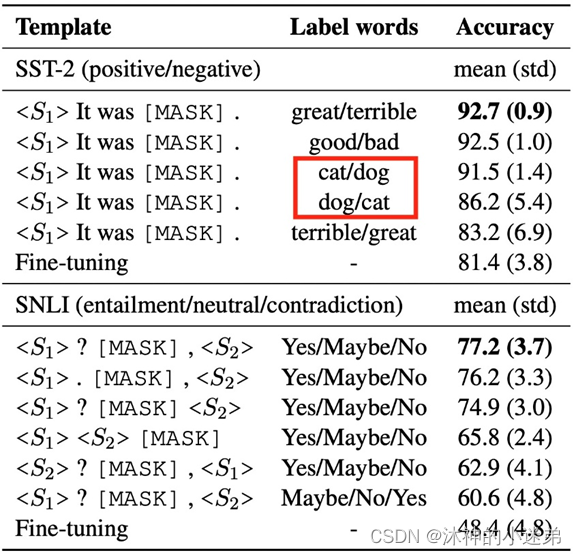
使用相同的[模板],不同的[标签词]会产生不一样的效果。例如 great/terrible 和 cat/dog 这两组标签词的效果不一样,而且即便是相同标签词,互换顺序也会导致最终效果有所变化,例如 cat/dog 和 dot/cat。使用相同[标签词],对[模板]进行改动(例如增删标点)也会呈现不同的结果。
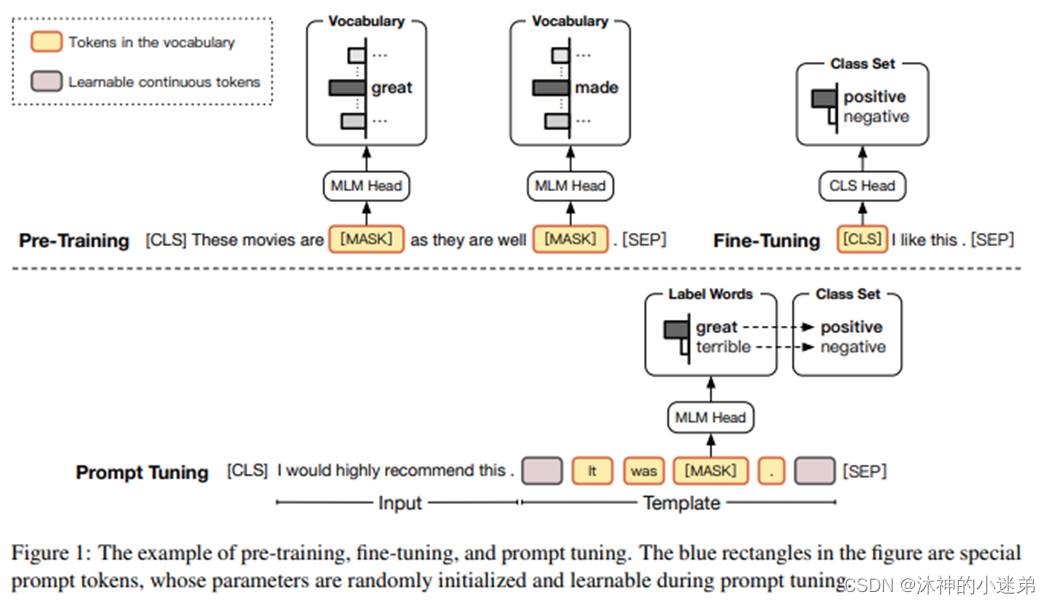
核心思想
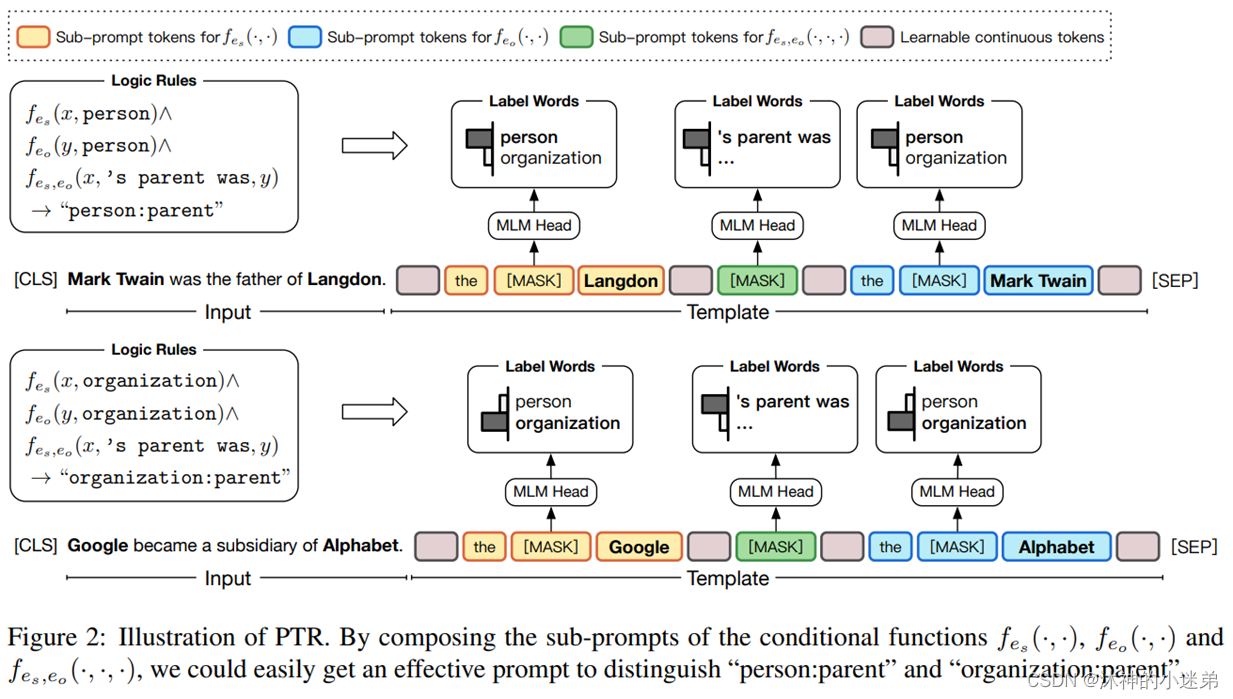
对于关系分类这样复杂的多分类任务(预测两个标记实体之间的语义关系),手动找到合适的模板、合适的标签词来区分不同的类很有挑战性。例如“person:parent”和“organization:parent”。
PTR核心思路
只设计简单的sub-prompt,利用逻辑规则来组装sub-prompt(兼容hard prompt、auto prompt、soft prompt),大量先验的规则可以用进来利用类别之间的关联信息,并且相比手工设计所有类的模板和单独的标签词,将子提示组合成针对任务的提示更高效。(为每个类都设计label会很复杂)
模板定义
将输入x送入模板,得到T(x),再将T(x)送入roberta模型进行编码,取[mask] token的logits,预测gound truth关系对应的词。在代码实现时,图中绿色[mask]是用三个[mask] token来表示的,每个分别预测“‘s”、“parent”、"was"。
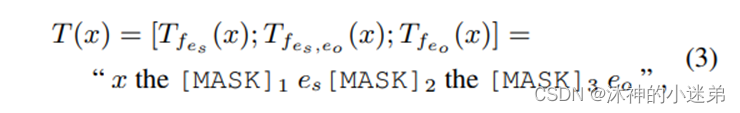
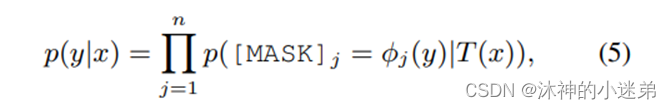
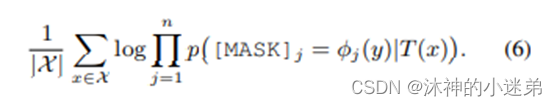
每一种关系y,都可以用五个token来表示。公式(5)表示,在输入x的条件下输出y的概率,五个mask分别预测y对应的五个token。其中φ表示y到手工模板的映射,如org: founded_by —> organization was founded by person。
作者根据给定的42种关系,手工构造了42个模板:

模型的损失函数
代码的loss为两部分MLM loss + sentence CE loss。
作者将五个mask分别用各自的list存放:
第一个mask对应3种可能的token: [person , organization , entity, …]
第二个mask对应3种可能的token: ['s , is , was]
第三个mask对应24种可能的token: [died , founded, ...]
第四个mask对应9种可能的token: [of , by , in ...]
(关系用3个token来表示)
第五个mask对应12中可能的token: [state , person , ...]
对roberta输出的编码结果,取5个mask对应的logits, 计算交叉熵,得到各自的loss。再把这5个loss加和,得到MLM loss。
每个关系类别的logits的计算方式:在计算MLM loss时,已经算出了5组logits(每个mask处一组)。每个关系通过φ函数映射出五个token,每个token去各自的那组logits中,取出自己token所在位置的logits, 再将这5个logits加和,得到这组关系的relation logits。
整句话的ce loss计算方式为:先算出每个关系类别的logits(42个),再过softmax, 并计算跟ground truth的交叉熵。
实验结果-与采用其他方法的关系抽取模型做对比
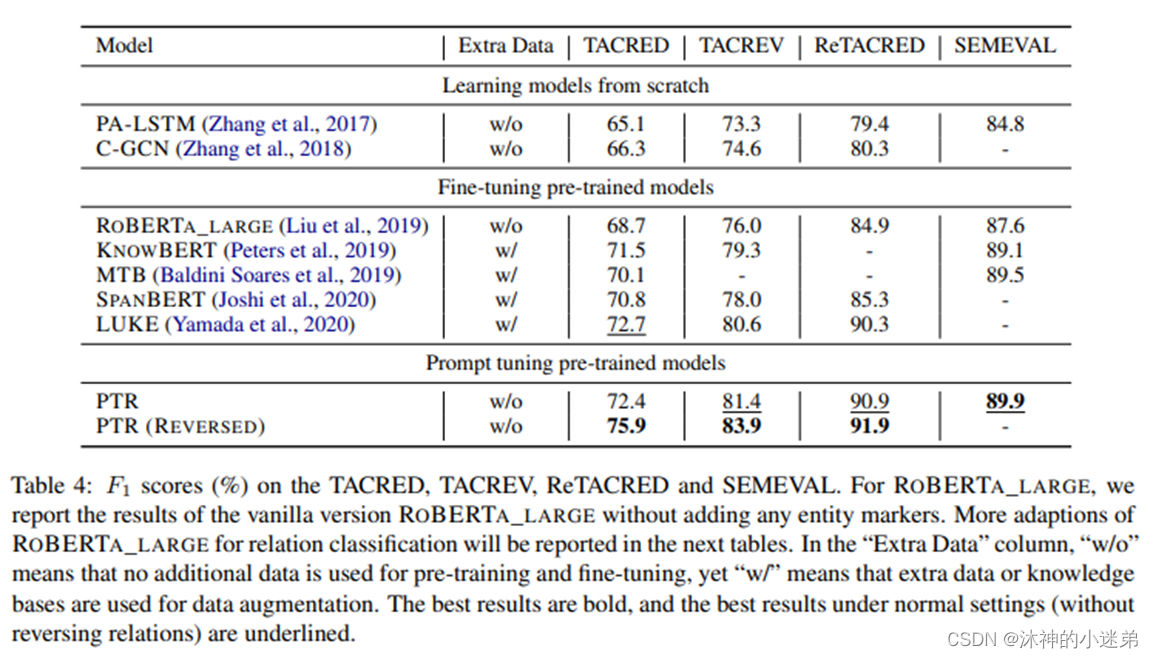
所用数据集:
TACRED(2017)
关系分类中规模最大、使用最广泛的数据集之一,包含42种关系类型。
TACREV(2020)
找出并纠正TACRED验证集和测试集中的错误,训练集保持完整。
ReTACRED(2021)
解决了原始TACRED数据集的一些缺点,重构了它的训练集、验证集和测试集,还修改了一些关系类型。
SemEval(2010)
关系分类传统数据集,具有10种关系类型。
较直接参数微调效果要优
与融入知识图谱的预训练语言模型效果相当
与其他使用prompt的模型对比,也有一定优势
Prompt能较好地激发模型内的结构化知识信息
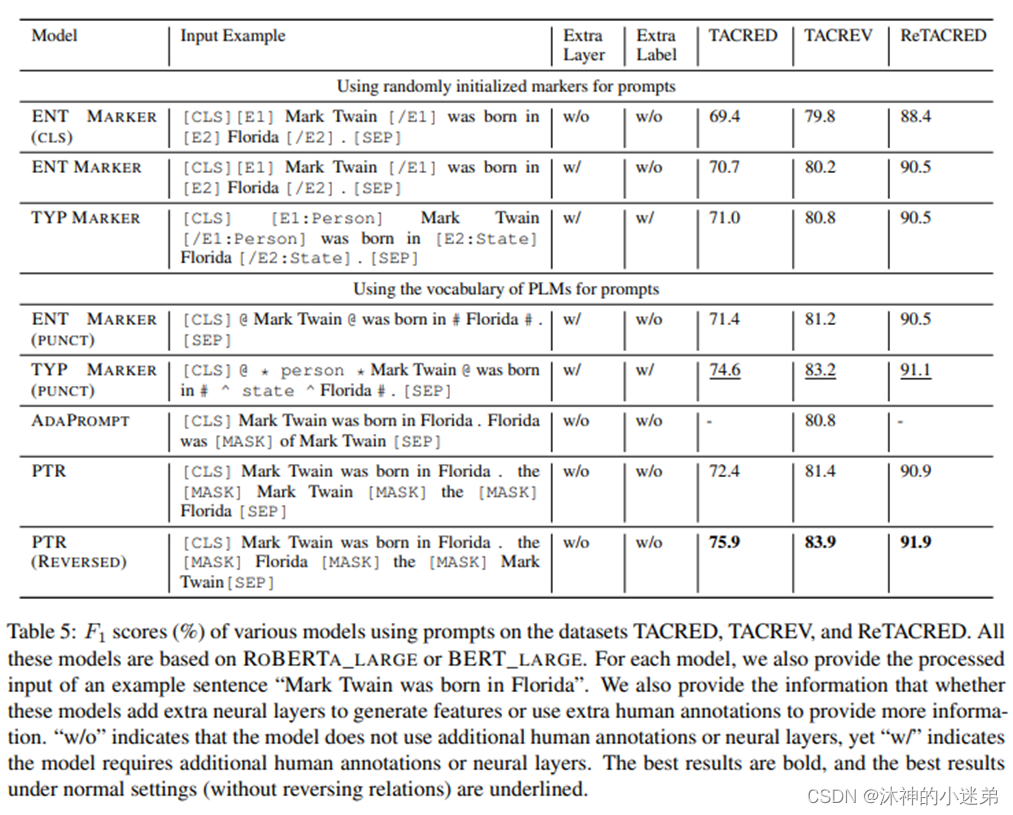
(Type marker给出了每个实体的类型,全量模型上效果会更好,但在少次学习上不如PTR)
预模型模型本身含有丰富的结构化信息,但是不容易激发出来。
融入知识图谱可以看作一种shortcut
Prompt能更好激发模型内在的结构化知识信息
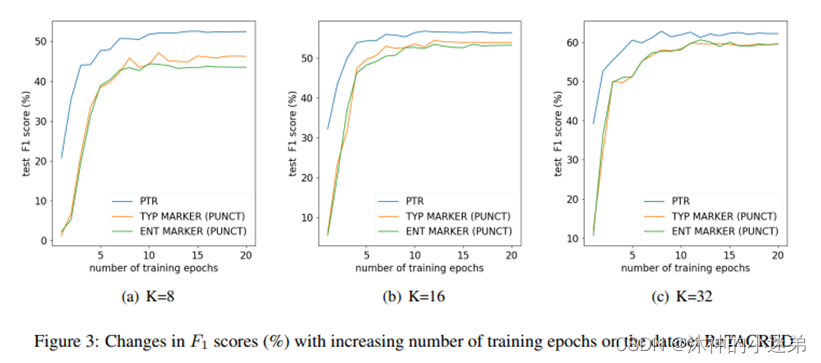
与之前浙大的一篇工作的对比:
两篇文章看得都比较早,这个比较意义已经不大了,现在两个团队都有了新的模型和更好的结果。
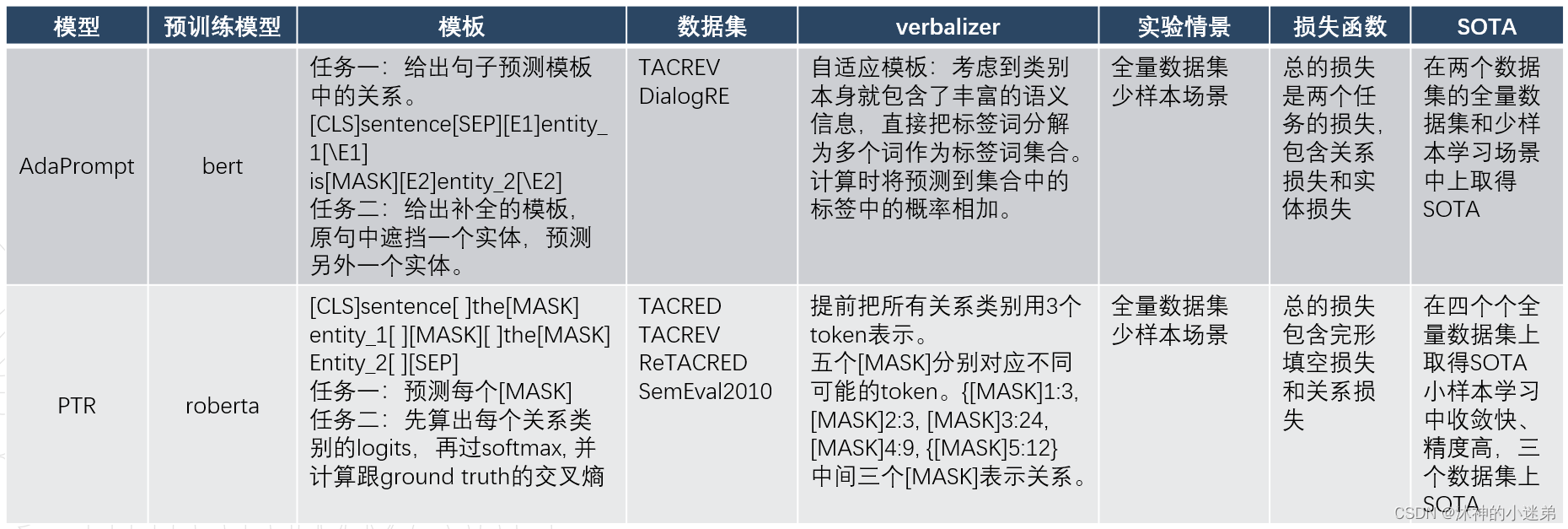
AdaPrompt: Adaptive Prompt-based Finetuning for Relation Extraction
PTR优势:
Sub-prompt设计简单
Sub-prompt的verbalizer设计也简单
未来工作:
大规模prompt tuning上进行尝试
Soft prompt、 auto prompt 与规则结合
总结
这篇文章可以说是基于prompt做关系抽取的开山之作,解释性好,效果也好。但是可能规则的加入限制了模型的效果,后面已经有了一系列工作取得了更好的性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











