








这是加薪的第六篇推文,关于CDNow在线网站用户消费行为分析实战。时间匆忙来不及排版,还请见谅。项目完整代码见加薪的CSDN博客:https://blog.csdn.net/cjx_cqupt,或公众号后台回复CDNow获取。
目录
【文章约5200字,预计阅读时间32分钟】
1背景介绍
此次项目数据来自Kaggle,是CDNow网站的用户购买明细。数据为2010年12月1日至2011年12月9日在英国注册的非实体网上零售发生的所有交易数据,共包含541409行数据。各变量的具体描述如下:
| 字段名 | 字段含义 | 字段计数 | 字段类型 |
| Id | 用户ID | 69659 | Int64 |
| Date | 购买日期 | 69659 | Int64 |
| Quantity | 购买产品数 | 69659 | Int64 |
| TotalPrice | 购买金额 | 69659 | Float64 |
观察到日期是int64,需要将时间的数据类型转换。
关于数据的具体说明如下:
-
从消费频率角度考虑CD商品属性,设置时间窗口为1个月。
-
探究数据表明此数据是1-3月有过消费用户在未来18个月内的消费情况,因此假设该店是1月开业,至今运营了18个月,将首次消费用户定义为新客。
-
一个用户在一天内可能存在多笔订单。
2数据初探
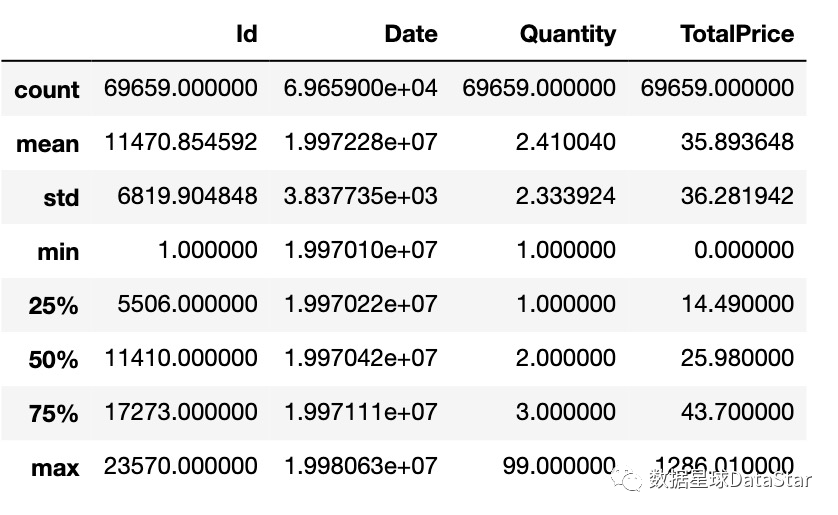
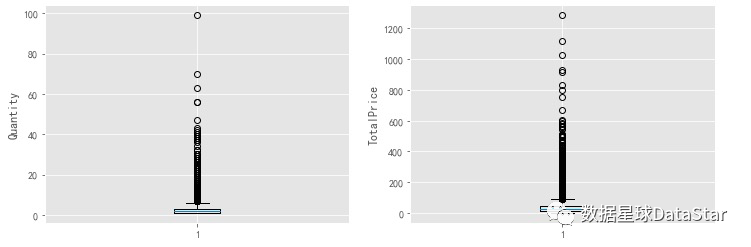
图1.购买产品数、购买金额箱线图
对于购买产品数量,大部分订单只购买了少量产品。每笔订单平均购买产品2.4,中位数2,数据左偏。最大值为99,有极值干扰;对于购买金额,大部分订单都集中在小额,每笔订单平均消费36,75分位数为43,最大值为1296,有极值干扰;从图1箱线图也能看出,样本数据中存在特别大的异常值。消费数据分布服从长尾形态,大部分用户都是小额,小部分用户贡献收入的大头,俗称二八。
3用户消费趋势分析(按月)
3.1 月消费总金额、消费次数、产品购买量、消费人数
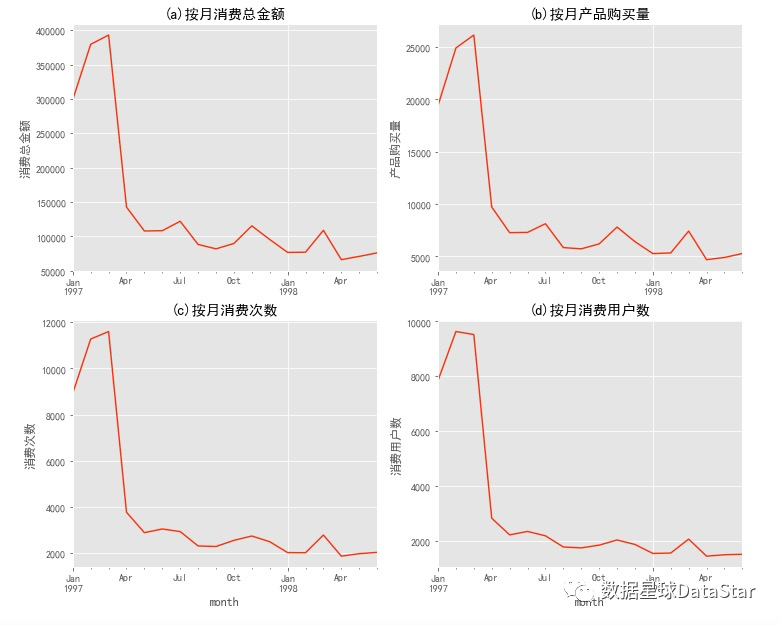
图2.月消费总金额、消费次数、产品购买量、月消费人数
由图2可知,月消费总金额、月消费次数、月产品购买量、月消费人数四者随时间变化趋势基本一致,均在前三月达到最高峰,后续较为稳定,有轻微下降趋势。其中,月消费人数在后期变化相对其他指标更为平稳,猜测是因为留存下来的用户忠诚度较高,具体要从老客回购率和复购率指标分析。
为什么会呈现这个原因呢?假设:
1. 早期时间段用户中有异常值,即存在大额消费用户;
2. 假设早期存在各类营销活动,但这里只有消费数据,所以无法判断。
3.2 月用户平均消费金额、消费次数趋势
图3.月用户平均消费额、消费次数折线图
前三个月每月用户平均消费金额在40元左右,呈上升趋势,后期月用户平均消费金额稳定在50元左右。前三个月用户平均消费次数在1.2次左右,呈上升趋势,后期月平均消费次数稳定在1.35次左右。综合月用户平均消费金额和月用户平均消费次数的时间序列分析,可看出其整体变化趋势一致,老客消费额、消费频次均高于新客。
4用户个体消费分析
4.1 用户消费金额、消费商品数、消费次数描述统计
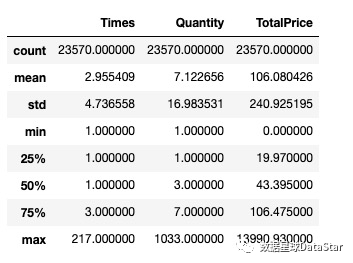
图4. 用户消费金额、消费商品数、消费次数描述统计
用户平均购买7张CD,但是中位值只有3,说明小部分用户购买了大量CD。数据右偏;用户平均消费金额(客单价)106元,标准差是240,结合分位数和最大值看,平均值和75分位接近,存在小部分的高额消费用户;用户平均每月购买3次,但中位值只有1,说明大部分用户平均每月只会购买1次CD,存在小部分高频购买用户。
4.2用户消费金额和消费商品数散点图
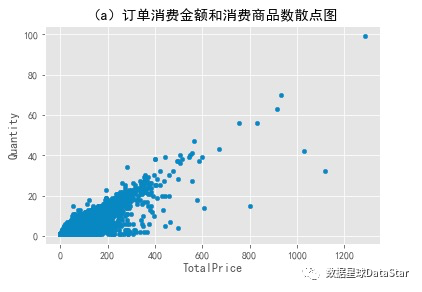
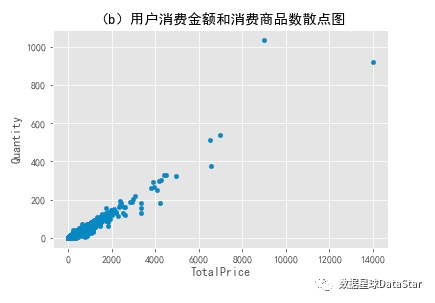
图5. 用户消费金额和消费商品数散点图
用户消费总金额和购买商品总数散点图反映的是客单价。从图中可以看出用户比较健康,且规律性强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系呈线性,没几个离群点。散点图容易受极值影响,少数离群点拉大了整张表,可以看出消费能力特别强的用户数量不多,为了更好的观察,用直方图查看用户消费情况分布。
4.3 用户消费金额和消费商品数
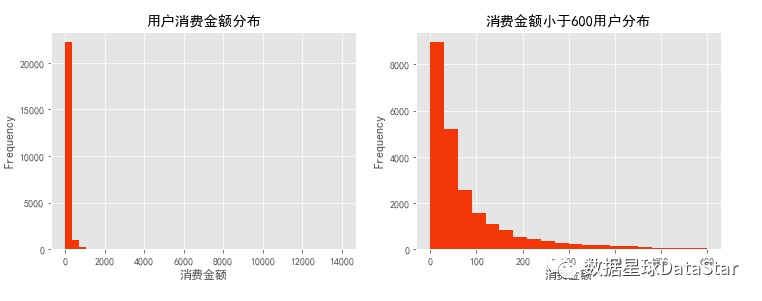
图6. 用户消费金额分布图
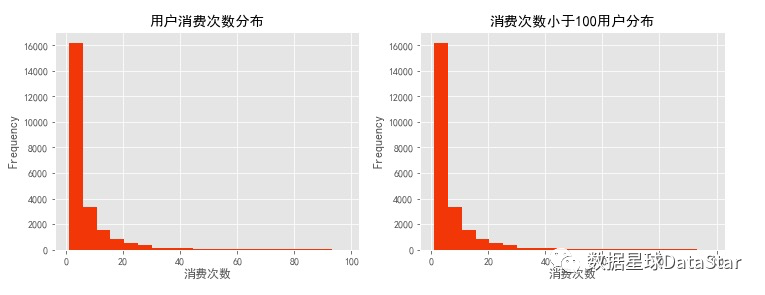
图7. 用户消费商品数分布图
由图7可以看出,大部分用户消费额都集中在1000以下,对消费额进行过滤(TotalPrice<1000)以更清楚的查看用户消费额分布情况。大部分用户消费额均低于200,数据在0轴旁聚集。进一步探索发现25.79%的用户消费均低于20。由图8可以看出大部分用户消费商品数低于20,数据在0轴旁聚集。进一步探索发现28.89%的用户消费仅购买一件商品。总体而言,用户消费金额和购买产品数量呈现集中趋势,大部分用户消费能力不高,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。消费行为有明显的二八倾向,需要知道高质量用户为消费贡献了多少份额。
4.4 用户累积消费金额、累积消费商品数占比
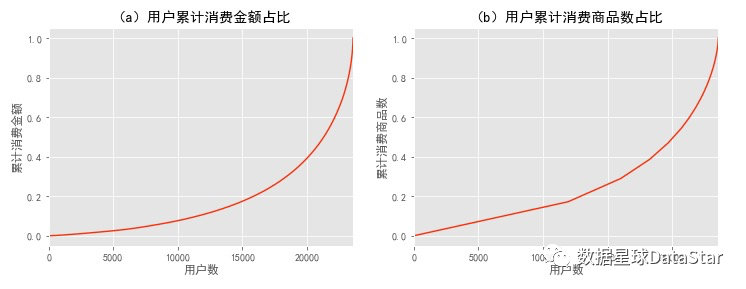
图9. 用户累计消费金额、累积消费消费商品数占比
按用户消费金额升序排列,计算用户累计金额占比情况。由图9左图可知50%的用户(约1.2万人)仅贡献了15%的消费额度,前20000个用户贡献了40%的消费,而排名前5000的用户贡献了60%的消费额。由图9右图可知,前两万个用户贡献了45%的订单量,而高消费的约五千名用户贡献了55%的销量。在消费领域中,狠抓高质量用户是万古不变的道理。
5用户消费行为
5.1 用户首次消费、最后一次消费时间节点分布
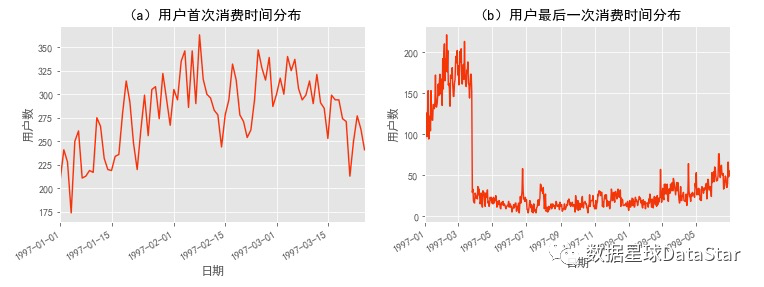
图10. 用户首次消费时间、最后一次消费时间节点分布
用户第一次购买分布,集中在前三个月,其中在2月15日左右有一次剧烈波动。可能是渠道、奖励机制、营销活动等发生了变化。从用户首次消费时间节点可以推断,案例中订单数据只选择了1997年1~3月左右消费用户截止98年6月的消费行为。用户最后一次购买时间分布比首次购买时间分布更广。大部分最后一次购买,集中在前3个月,说明很多用户购买一次后就不再进行购买(前面统计确实有28.89%用户仅有一次购买行为)。随着时间递增,最后一次购买数也在递增,消费呈现流失上升的状况。(只统计到6月,后面该客户可能再买)
5.2新老客消费比
通过判断用户最小生命周期与最大生命周期相等,找出只在一天内消费的用户,统计得出,有12054用户仅消费了一次,占用户总数的51.14%。通过判断用户订单数等于1,找出只消费过一笔订单的用户,统计得出11908用户仅下过一笔订单,占用户总数的50.52%。有146名用户在一天内下了两单并流失。
5.3用户分层
RFM用户分层
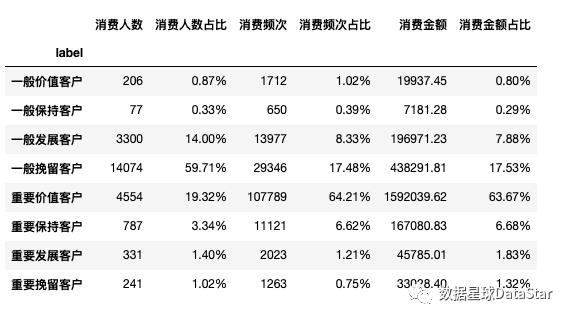
图11. RFM用户分层情况
从RFM分层结果可知,19.32%的重要价值客户贡献了64.21%的订单量以及63.67%的消费额,而59.71%的一般挽留客户仅贡献了17.48%的订单量以及17.53%的消费额。消费呈明显二八倾向。但此处仅根据RFM数值相对平均值大小对用户分层,受1-3月超50%用户仅消费一次流失极值的影响,划分结果准确度不高。具体RFM的划分标准应该以业务为准。
新、活跃、回流、流失/不活跃
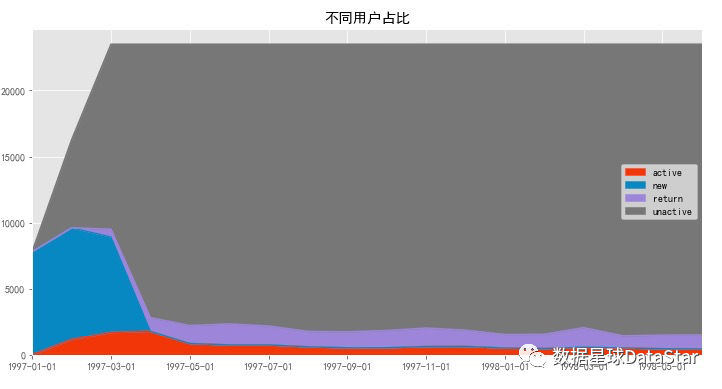
图12. 不同用户占比面积图
上图是某时间段消费过用户的后续行为,蓝色和灰色区域都可以不看(因为只有1-3月有新用户,后续没有新用户流入)。只看紫色回流和红色活跃这两个分层,用户数比较稳定。这两个分层相加,就是消费用户占比(后期没新客)。
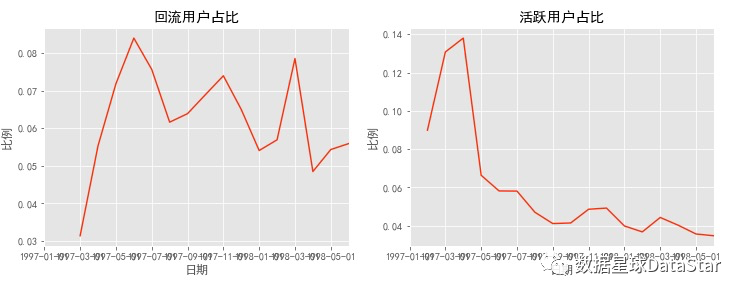
图13.回流/活跃用户占比
由上图可知,回流用户占比在5%~8%,有下降趋势。所谓回流占比,就是同一时间窗口下,回流用户在总用户中占比(回流率:指上个月多少不活跃/消费用户在本月活跃/消费)。活跃用户占比下降趋势明显,占比在3%~5%间。这里用户活跃可以看作连续消费用户,质量在一定程度上高于回流用户。结合回流用户和活跃用户看,在后期消费用户中,60%是回流用户,40%是活跃用户/连续消费用户,整体质量还好,但是针对这两个分层依旧有改进的空间,可以继续细化数据。
5.4用户购买周期
用户消费周期描述
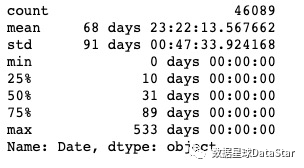
图14.用户消费周期描述
用户平均消费间隔是68天,中位值是31天,想要召回用户,在60天左右的消费间隔是比较好的。
用户消费周期分布
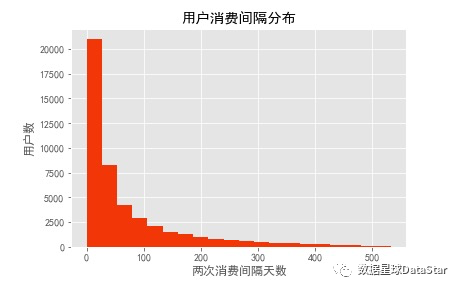
图15.用户消费周期分布回流占比
直方图呈典型长尾指数分布,绝大部分用户购买周期都低于100天,建议将时间召回点设为消费后立即赠送优惠券,消费后10天询问用户CD怎么样,消费后30天提醒优惠券到期,消费后60天短信推送。
5.5用户生命周期
用户生命周期描述

图16.用户生命周期描述
对用户第一次消费和最后一次消费的时间相减,得出每一位用户的生命周期。因为数据中的用户都是前三个月第一次消费,所以这里的生命周期代表的是1-3月用户的生命周期。随着后续消费,用户的平均生命周期可能会增长;用户平均消费周期是134天,但中位数仅0天,超过50%的用户仅消费一次。
用户生命周期分布
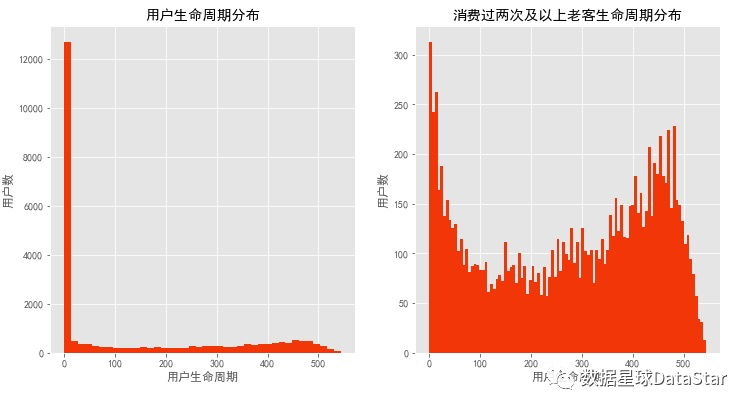
图17.用户生命周期分布
用户生命周期受只购买一次的用户影响比较厉害(可以排除),计算所有消费过两次以上老客的生命周期。这是双峰趋势图,仍旧有不少用户生命周期靠拢在0天。部分质量差的用户,虽然消费了两次,但是仍旧无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50天~300天,属于普通型的生命周期,高质量用户的生命周期,集中在400天以后,这已经属于忠诚用户了。400+用户占老客比31.70%、占总量比15.49%。对新客户采取更多激励措施,促使其成为老客,能够更大比例的创造忠诚客户。
6复购率和回购率分析
6.1复购率与回购率
自然月内,购买多次的用户占比,即复购率=(该月消费两次及以上用户数)/(该月总消费用户数)。
曾经购买的用户在某一时期内再次购买的占比,即回购率=(该月消费且下月消费用户数)/(该月消费总用户数)。
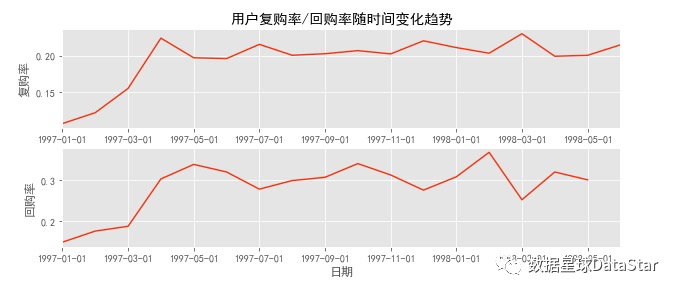
图18.用户复购率/回购率随时间变化趋势
用sum和count相除计算复购率。因为这两个函数都会忽略NaN,而NaN是没有消费的用户,count不论0还是1都会统计,所以是总的消费用户数,而sum求和计算了两次以上的消费用户。这里用了比较巧妙的替代法计算复购率,SQL中也可以用。
图上可以看出前三个月因为有大量新用户涌入,而这批用户只购买了一次,所以导致复购率降低,譬如1月复购率只有6%左右,而在后期,复购率稳定在20%左右;单看新客和老客,复购率有三倍左右的差距;用户回购率高于复购,约在30%左右,波动性也较强。新用户的回购率在15%左右,和老客差异不大;将回购率和复购率综合分析,可以得出,新客的整体质量低于老客,老客忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
6.2留存率
一天消费两单的用户没有被划分入0-3天,因为计算的是留存率,如果用户仅消费了一次,留存率应该是 0。此外,如果用户第一天内消费了多次,但是往后没有消费,也算作留存率 0。下图对曾经购买过用户在某一时期内再次购买的占比。
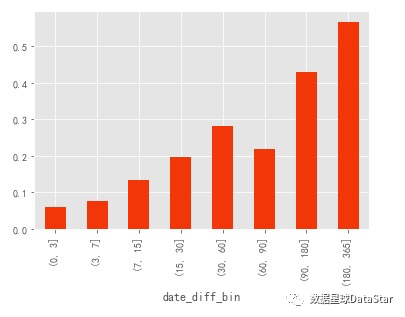
图19. 曾经购买过用户在某一时期内再次购买占比
7结论与复盘
该项目主要是通过分析网站在线消费数据以提高总GMV(销售额)。针对这项需求,从客单价和订单量两个角度出发。
从客单价出发,作出用户消费金额与消费产品数散点图,发现两者呈线性关系,客单价较为稳定,提出该电商网站销售产品单一,后期可丰富产品种类以提高客单价。
从订单量出发,考虑商品消费频率以月为时间窗口统计月订单量变化趋势发现其在前三个月出现异常高值然后急剧下降。对此假设异常是由少数用户高额消费引起,进一步探究用户消费金额和购买产品数量分布,发现其呈现集中趋势,大部分用户消费能力不高,高消费用户在图上几乎看不到,推翻了原假设。进一步对用户消费行为进行分析,探究用户首次消费与最后一次消费时间节点,发现超50%的用户仅在前三月消费一次就流失了,从而找到了数据在1-3月出现异常高值然后急剧下降的原因。更进一步,采用RFM模型对用户分层,发现 20%的重要价值客户贡献了60%的消费额,60%的一般挽留客户贡献了20%的消费额,消费呈现明显二八倾向。为更大程度提升一般挽留客户的消费能力,对用户消费周期进行分析,得出用户平均消费周期为68天,分布呈长尾分布,大部分用户消费间隔较短。对回购率和复购率进行计算,得出老客相对新客更忠诚。最终提出将时间召回点设为消费后立即赠送优惠券,降低新客流失,消费后30天提醒优惠券到期,消费后60天短信推送等,以提高网站订单量。
通过这个项目,提升了目标公式化拆解、逻辑分析思维以及Python数据分析的能力。但由于对市场背景缺乏了解没有给出切实有用的建议,在之后的项目中会更加注重市场背景和需求调查,做到以目标驱动分析。此外,RFM用户分层没有根据业务情况进行打分,而是直接根据RFM三者数值与平均值大小区分了高低,受极值影响严重。

Python:
1.浮点数转换成小数写法
2.Ndarray、DataFrame、Series切片,loc、iloc
3.map、apply、applymap
3.Df.plot.scatter()与plt.plot()区别,为何前者放在子图中不显示,后者显示?
项目完整代码:
#!/usr/bin/env python
# coding: utf-8
# # CD用户消费分析
# ## 1.数据加载与预处理
# In[1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
get_ipython().run_line_magic('matplotlib', 'inline')
#更改设计风格
plt.style.use('ggplot')
#指定默认字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family']='sans-serif'
#解决负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# In[2]:
columns = ['Id','Date','Quantity','TotalPrice']
df = pd.read_table('CDNOW_master.txt',names=columns,sep='\s+')
# - 加载包和数据,文件是txt,用read_table方法打开;
# - 因为原始数据不包含表头,所以需要赋予;
# - 字符串是空格分割,用\s+表示匹配任意空白符。
# <br><br>
# **pd.read_table(parse_dates=,date_parser=),参数parse_dates设置需要转换为日期的字段,参数date_parser设置日期格式**
# In[3]:
df.head()
# #### 字段含义
# * Id:用户ID
# * Date:购买日期(现在它只是年月日组合的数字,没有时间含义)
# * Quantity:购买产品数
# * TotalPrice:购买金额(小数)<br>
# **注意:一个用户在一天内可能购买多次,用户ID为2的用户就在1月12日购买了两次。**
# In[4]:
df.describe()
# * 从Quantity购买产品数量来看,大部分订单只消费了少量商品(平均2.4),标准差为2.3,稍稍具有波动性。中位数为2,75分位数为3,最大值为99,说明绝大部分订单购买量都不多,有一定极值干扰;
# * 从TotalPrice购买金额来看,每笔订单平均消费36元,75分位数为43,最大值为1296,说明大部分订单都集中在小额,有一定极值干扰。<br>
#
# **一般而言,消费类数据分布都服从长尾形态。大部分用户都是小额,然后小部分用户贡献收入的大头,俗称二八。**
# In[5]:
df.info()
# - 一共有69659行记录,没有空值,
# - 日期是int64,需要将时间的数据类型转换
# In[6]:
df['Date'] = pd.to_datetime(df.Date,format='%Y%m%d')
# - pd.to_datetime() 可以将特定字符串或者数字转换成时间格式,其中format参数用于匹配。
# - 例如19970101,%Y匹配前四位数字1997,如果y小写只匹配两位数字97,%m匹配01,%d匹配01。另外,小时是%h,分钟是%M,注意和月的大小写不一致,秒是%s。若是1997-01-01这形式,则是%Y-%m-%d,以此类推。
# In[7]:
df.head()
# In[8]:
df['month'] = df.Date.values.astype('datetime64[M]')
# - df.Date取得Series,然后通过values得到数组形式的值,通过数组的astype方法可以将时间格式进行转换,比如[M]转化成月份。我们将月份作为消费行为的主要时间窗口,选择哪种时间窗口取决于消费频率。
# In[9]:
df.head()
# 上图是转化后的格式。月份依旧显示日,只是变为月初的形式。
# In[10]:
df.info()
# In[11]:
plt.figure(figsize=(12,4))
plt.subplot(121)
plt.boxplot(x=[df.Quantity]) #columns列索引,values所有数值
plt.ylabel('Quantity')
plt.subplot(122)
plt.boxplot(x=[df.TotalPrice]) #columns列索引,values所有数值
plt.ylabel('TotalPrice')
plt.show()
# ## 2. 用户消费趋势分析(按月)
# - 月消费总金额、月消费次数、月产品购买量、月消费人数
# In[12]:
#pivot_table做数据透视表,index:索引、columns:列、values:值、aggfunc:方法。
pivoted_month = df.pivot_table(index='month',
values=['TotalPrice','Quantity','Id'],
aggfunc={'TotalPrice':'sum',
'Quantity':'sum',
'Id':'count'})
pivoted_month.head()
# In[13]:
plt.figure(figsize=(12,10))
plt.subplot(221)
pivoted_month['TotalPrice'].plot(title='(a)按月消费总金额')
plt.ylabel('消费总金额')
plt.xlabel('')
plt.subplot(222)
pivoted_month['Quantity'].plot(title='(b)按月产品购买量')
plt.ylabel('产品购买量')
plt.xlabel('')
plt.subplot(223)
pivoted_month['Id'].plot(title='(c)按月消费次数')
plt.ylabel('消费次数')
plt.subplot(224)
#每月用户Id作为数组传入lambda函数,数组去重后长度作为每月消费人数
df.groupby('month').Id.apply(lambda x:len(x.drop_duplicates())).plot(title='(d)按月消费用户数')
plt.ylabel('消费用户数')
plt.show()
# - 由图(a)可知,前三月消费额达到最高峰,后续消费较为稳定,有轻微下降趋势。
# - 由图(b)可知,前三月产品销量达到最高峰,后期销量平稳,数据比较异常。
# - 由图(c)可知,前三月消费订单数在10000笔左右,后续月份平均消费订单数在2500笔左右。
# - 由图(d)可知,前三月消费人数在8000-10000之间,后续月份平均消费人数2000不到。
#
# **总结:**
# 总的来说,月消费总金额、月产品购买量、月消费次数、月消费用户数均呈现相同趋势的异常波动,针对数据异常,假设:
# 1. 早期时间段用户中有异常值,即存在大额消费用户;
# 2. 早期存在各类营销活动,但这里只有消费数据,无法判断。
# In[14]:
plt.figure(figsize=(12,4))
plt.subplot(121)
(df.groupby('month').TotalPrice.sum()/df.groupby('month').Id.apply(lambda x:len(x.drop_duplicates()))).plot()
plt.ylabel('用户平均消费金额')
plt.title('(a)月用户平均消费金额')
plt.subplot(122)
(df.groupby('month').Id.count()/df.groupby('month').Id.apply(lambda x:len(x.drop_duplicates()))).plot()
plt.ylabel('用户平均平均消费次数')
plt.title('(b)月用户平均平均消费次数')
plt.show()
# - 前三月每月用户平均消费金额40左右,呈上升趋势,后期月用户平均消费金额在50左右。
# - 前三月用户平均消费次数在1.2左右,呈上升趋势,后期月平均消费次数在1.35左右。
# - 综合月用户平均消费金额和月用户平均消费次数的时间序列分析,可看出其整体变化趋势一致。
# ## 3.用户个体消费分析
# - ### 3.1用户消费金额、消费商品数、消费次数描述统计
# - ### 3.2用户消费金额和消费商品数的散点图(探究两者关系)
# - ### 3.3用户消费金额的分布图(分档次看分布)
# - ### 3.4用户消费消费商品数的分布图(分档次看分布)
# - ### 3.5用户累积消费金额占比(百分之多少的用户占了百分之多少的消费额,明确头部用户消费多寡建立认知)
# ### 3.1用户消费金额、消费商品数、消费次数描述统计
# In[15]:
pivoted_user = df.pivot_table(index='Id',values=['Quantity','TotalPrice','Date'],
aggfunc={'Quantity':'sum',
'TotalPrice':'sum',
'Date':'count'})
pivoted_user.rename(columns = {'Date':'Times'},inplace=True)
pivoted_user.describe()
# - 用户平均购买7张CD,但是中位值只有3,说明小部分用户购买了大量CD。数据右偏(中位数小于平均数)。
# - 用户平均消费金额(客单价)100元,标准差是240,结合分位数和最大值看,平均值和75分位接近,肯定存在小部分的高额消费用户。
# - 用户平均每月购买3次,但中位值只有1,说明大部分用户平均每月只会购买1次CD,存在小部分高频购买用户。
# ### 3.2用户消费金额和消费商品数的散点图(探究两者关系)
# In[16]:
df.plot.scatter(x='TotalPrice',y='Quantity',title='(a)订单消费金额和消费商品数散点图')
# - 从图中观察,订单消费金额和订单商品量呈规律性,每个商品十元左右。订单的极值较少,超出1000的就几个,显然不存在大额消费的订单,假设一不成立。
# In[17]:
user_grouped = df.groupby('Id').sum()
# In[18]:
user_grouped.plot.scatter(x='TotalPrice',y='Quantity',title='(b)用户消费金额和消费商品数散点图')
# - 绘制用户消费总金额和购买商品总数散点图,其实反映的是客单价。从图中可以看出用户比较健康,且规律性比订单更强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点。
# - 散点图容易受极值影响,少数离群点拉大了整张表,可以直接使用query对数据框进行过滤。
# In[19]:
user_grouped.query('TotalPrice < 6000').plot.scatter(x='TotalPrice',y='Quantity')
# - 消费能力特别强的用户数量不多,为了更好的观察,用直方图查看用户消费情况分布。
# ### 3.3用户消费金额的分布图(分档次看分布,二八法则应用)
# In[20]:
plt.figure(figsize=(12,4))
plt.subplot(121)
user_grouped.TotalPrice.plot.hist(bins=40,title='用户消费金额分布')
plt.xlabel('消费金额')
plt.subplot(122)
user_grouped.query('TotalPrice<600').TotalPrice.plot.hist(bins=20,title='消费金额小于600用户分布')
plt.xlabel('消费金额')
# - 由用户消费情况分布图可以看出,大部分用户的消费额都集中在600以下,对消费额进行过滤以更清楚的查看用户消费额分布情况。
# ### 3.4用户消费次数的分布图(分档次看分布,二八法则应用)
# In[21]:
plt.figure(figsize=(12,4))
plt.subplot(121)
user_grouped.query('Quantity<100').Quantity.plot.hist(bins=20,title='用户消费次数分布')
plt.xlabel('消费次数')
plt.subplot(122)
user_grouped.query('Quantity<100').Quantity.plot.hist(bins=20,title='消费次数小于100用户分布')
plt.xlabel('消费次数')
# - 从直方图可知,用户消费金额和购买产品数量,绝大部分呈现集中趋势,小部分异常值干扰判断,可以使用过滤操作排除异常。
# - 使用切比雪夫定理过滤异常值,计算95%的数据的分布情况。(在绝大多数分布中,95%的数据都聚集在距离平均数5个标准差之内),此处给出的100就基本等于mean+5*std
# - 从直方图看,大部分用户的消费能力确实不高,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。消费行为有明显的二八倾向,需要知道高质量用户为消费贡献了多少份额。
# ### 3.5用户累积消费金额占比(百分之多少的用户占了百分之多少的消费额,明确头部用户消费多寡建立认知)
# In[22]:
user_price = df.groupby('Id').TotalPrice.sum().sort_values().reset_index()
user_price['price_cumsum'] = user_price.TotalPrice.cumsum()
price_total = user_price.price_cumsum.max()
user_price['prop'] = user_price.apply(lambda x:x.price_cumsum/price_total,axis=1)
user_price.tail()
# - 新建对象,按用户的消费金额升序。使用cumsum,逐行计算累计的金额;然后每个金额处以累计金额最大值(即总消费额)得到累计金额占比prop。
# In[23]:
#需要reset_index()否则会把id作为横坐标,作图失败!
user_counts = df.groupby('Id').Date.count().sort_values().reset_index()
user_counts['counts_cumsum'] = user_counts.Date.cumsum()
counts_total = user_counts.counts_cumsum.max()
user_counts['prop'] = user_counts.apply(lambda x:x.counts_cumsum/counts_total,axis=1)
plt.figure(figsize=(12,4))
plt.subplot(121)
user_price.prop.plot(title='(a)用户累计消费金额占比')
plt.xlabel('用户数')
plt.ylabel('累计消费金额')
plt.subplot(122)
user_counts.prop.plot(title='(b)用户累计消费商品数占比')
plt.xlabel('用户数')
plt.ylabel('累计消费商品数')
plt.show()
# - 按用户消费金额升序排列,由图可知50%的用户仅贡献了15%的消费额度,前20000个用户贡献了40%的消费。而排名前5000的用户贡献了60%的消费额。
# * 统计销量,前两万个用户贡献了45%的订单量,而高消费的约五千名用户贡献了55%的销量。在消费领域中,狠抓高质量用户是万古不变的道理。
# # 4.用户消费行为
# - ### 4.1用户首次消费、最后一次消费时间节点
# - ### 4.2新老客消费比
# - 多少用户仅消费了一次?
# - 每月新客占比?
# - ### 4.3用户分层
# - RFM
# - 新、活跃、回流、流失/不活跃
# - ### 4.4用户购买周期(按订单)
# - 用户消费周期描述
# - 用户消费周期分布
# - ### 4.5用户生命周期(按第一次&最后一次消费)
# - 用户生命周期描述
# - 用户生命周期分布
# ### 4.1用户首次消费
# - 与渠道相关,尤其是一些客单价较高,留存较低的行业,会非常重视首购的分析。
# In[24]:
plt.figure(figsize=(12,4))
plt.subplot(121)
df.groupby('Id').Date.min().value_counts().plot(title='(a)用户首次消费时间分布')
plt.xlabel('日期')
plt.ylabel('用户数')
plt.subplot(122)
df.groupby('Id').Date.max().value_counts().plot(title='(b)用户最后一次消费时间分布')
plt.xlabel('日期')
plt.ylabel('用户数')
plt.show()
# - 用groupby函数将用户分组,并求月份最小值,最小值即用户消费行为中第一次消费时间。
# - 用户第一次购买分布,集中在前三个月,其中在2月15日左右有一次剧烈波动。可能是渠道、奖励机制、营销活动等发生了变化。
#
# - 案例中订单数据,只选择了1997年1~3月左右消费用户截止98年6月的消费行为。
# - 用户最后一次购买时间的分布比首次购买时间分布更广
# - 大部分最后一次购买,集中在前3个月,说明很多用户购买了一次后就不再进行购买
# - 随着时间递增,最后一次购买数也在递增,消费呈现流失上升的状况。(这结论有问题吧,毕竟只统计到了6月,后面该客户也可能再买)
# ### 4.2新老客消费比
# - 多少用户仅消费了一次?
# - 每月新客占比?
# In[25]:
life_time = df.groupby('Id').Date.agg(['min','max'])
life_time.head()
# In[26]:
(life_time['min'] == life_time['max']).value_counts()
# 有一半用户,就消费了一次
# In[27]:
12054/(12054+11516)*100
# ### 4.4用户分层
# - RFM
# - 新、活跃、回流、流失/不活跃
# In[28]:
rfm = df.pivot_table(index='Id',
values=['Quantity','TotalPrice','Date'],
aggfunc={'Date':'max',
'TotalPrice':'sum',
'Quantity':'sum'})
rfm.head()
# In[29]:
#543天/天=543 将日期转换为数值进行计算
rfm['R'] = ((rfm.Date-rfm.Date.max()))/np.timedelta64(1,'D') #负数,值越大,距离现在越近
rfm.rename(columns={'Quantity':'F','TotalPrice':'M'},inplace=True)
# In[30]:
def rfm_func(x):
level = x.apply(lambda x:'1' if x>=0 else '0')
label = level.R + level.F + level.M #字符串拼接
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'010':'一般保持客户',
'111':'重要价值客户',
'100':'一般发展客户',
'000':'一般挽留客户'
}
result = d[label]
return result
rfm['label']=rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
# In[31]:
pivoted_rfm = rfm.pivot_table(index='label',
values=['R','F','M'],
aggfunc={'R':'count',
'F':'sum',
'M':'sum'}).rename(
columns={'R':'消费人数','F':'消费频次','M':'消费金额'})
pivoted_rfm['消费频次占比'] = (pivoted_rfm['消费频次']/pivoted_rfm['消费频次'].sum()*100).apply(lambda x:'%.2f%%' %x)
pivoted_rfm['消费金额占比'] = (pivoted_rfm['消费金额']/pivoted_rfm['消费金额'].sum()*100).apply(lambda x:'%.2f%%' %x)
pivoted_rfm['消费人数占比'] = (pivoted_rfm['消费人数']/pivoted_rfm['消费人数'].sum()*100).apply(lambda x:'%.2f%%' %x)
pivoted_rfm[['消费人数','消费人数占比','消费频次','消费频次占比','消费金额','消费金额占比']]
# - 从RFM分层结果可知,19.32%的重要价值客户贡献了64.21%的订单量以及63.67%的消费额,而59.71%的一般挽留客户仅贡献了17.48%的订单量以及17.53%的消费额。消费呈明显二八倾向。但这其中部分原因是由于1-3月超50%用户仅消费一次就流失情况的影响,具体来看,RFM的划分标准应该以业务为准。
# In[32]:
rfm
# In[33]:
plt.figure(figsize=(12,4))
plt.subplot(241)
rfm.loc[rfm.label == '一般价值客户'].plot.scatter(x='F',y='R',c='b')
plt.subplot(242)
rfm.loc[rfm.label == '一般保持客户'].plot.scatter(x='F',y='R',c='g')
plt.subplot(243)
rfm.loc[rfm.label == '一般发展客户'].plot.scatter(x='F',y='R',c='r')
plt.subplot(244)
rfm.loc[rfm.label == '一般挽留客户'].plot.scatter(x='F',y='R',c='c')
plt.subplot(245)
rfm.loc[rfm.label == '重要价值客户'].plot.scatter(x='F',y='R',c='m')
plt.subplot(246)
rfm.loc[rfm.label == '重要保持客户'].plot.scatter(x='F',y='R',c='y')
plt.subplot(247)
rfm.loc[rfm.label == '重要发展客户'].plot.scatter(x='F',y='R',c='k')
plt.subplot(248)
rfm.loc[rfm.label == '重要挽留客户'].plot.scatter(x='F',y='R',c='w')
plt.show()
# #### 新、活跃、回流、流失/不活跃
# * 按照用户消费行为,简单划分成:新用户、活跃用户、不活跃用户、回流用户。
# * 新用户:上一个时间窗口未注册或没有上一个时间窗口且这个时间窗口消费的用户;
# 活跃用户:上一个时间窗口不是未注册,这个时间窗口活跃;
# 不活跃用户:上一个时间窗口活跃,这个时间窗口不活跃
# 的定义是第一次消费;活跃用户是时间窗口内消费过的老客;不活跃用户是时间窗口内没有消费过的老客;回流用户是在上一个时间窗口没有消费,而在当前时间窗口有过消费。(以上的时间窗口都是按月统计)。比如某用户在1月第一次消费,那么他在1月的分层就是新用户;他在2月消费过,则是活跃用户;3月没有消费,此时是不活跃用户;4月再次消费,此时是回流用户,5月还是消费,是活跃用户。
# #### 主要分两部分判断,以本月是否消费为界:
#
# 若本月没有消费
# - 若之前是未注册,则依旧为未注册
# - 若之前有消费,则为流失/不活跃
# - 其他情况,为未注册
#
# 若本月有消费
# - 若是第一次消费,则为新用户
# - 如果之前有过消费,且上个月为不活跃,则为回流
# - 如果上个月未注册,则为新用户
# - 除此之外,为活跃
# In[34]:
pivoted_amount = df.pivot_table(index='Id',
columns='month',
values='TotalPrice',
aggfunc='mean').fillna(0)
columns_month = df.month.sort_values().astype('str').unique()
pivoted_amount.columns = columns_month
pivoted_amount.head()
# In[35]:
pivoted_purchase = pivoted_amount.applymap(lambda x:1 if x>0 else 0)
pivoted_purchase.head()
# In[36]:
def active_status(data):
status = []
for i in range(18):
#若本月没有消费(unreg表示未注册)
if data[i] == 0:
if len(status)>0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
#若本月消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return pd.Series(status,index=columns_month)
pivoted_purchase_status = pivoted_purchase.apply(lambda x:active_status(x),axis=1)
pivoted_purchase_status.head()
# 从结果看,用户每个月的分层状态以及变化已经被我们计算出来。我是根据透视出的宽表计算,其实还有一种另外一种写法,只提取时间窗口内的数据和上个窗口对比判断,封装成函数做循环,它适合ETL的增量更新。计算相邻两个时间窗口的用户行为,通过表连接对用户分层,并循环。(主流)
# In[37]:
purchase_status_counts = pivoted_purchase_status.replace('unreg',np.nan).apply(lambda x:pd.value_counts(x))
purchase_status_counts
# unreg状态排除掉,它是「未来」才作为新客。换算成不同分层每月的统计量。
# - 从周期来看,不活跃用户在逐渐增多,回流用户在逐渐减少,活跃用户也在逐渐减少,说明运营不利。
# In[38]:
purchase_status_counts.fillna(0).T.head()
# In[39]:
purchase_status_counts.fillna(0).T.plot.area(figsize=(12,6),title='不同用户占比')
# - 生成面积图,它是某时间段消费过用户的后续行为,蓝色和灰色区域都可以不看。只看紫色回流和红色活跃这两个分层,用户数比较稳定。这两个分层相加,就是消费用户占比(后期没新客)。
# - 正常情况新用户蓝色区域应该是比较稳定的
# # 回流率
# In[40]:
return_rate = purchase_status_counts.apply(lambda x:x/x.sum(),axis=1)
plt.figure(figsize=(12,4))
plt.subplot(121)
return_rate.loc['return'].plot(title='回流用户占比')
plt.xlabel('日期')
plt.ylabel('比例')
plt.subplot(122)
return_rate.loc['active'].plot(title='活跃用户占比')
plt.xlabel('日期')
plt.ylabel('比例')
plt.show()
# * 回流占比=同一时间窗口回流用户/总用户
# * 回流率,指上个月多少不活跃/消费用户在本月活跃/消费。
# ---
# 由上图可知,每月用户消费状态变化
# * 回流用户占比在5%~8%,有下降趋势。
# * 活跃用户下降趋势明显,占比在3%~5%间。这里用户活跃可以看作连续消费用户,质量在一定程度上高于回流用户。
# * 结合回流用户和活跃用户看,在后期消费用户中,60%是回流用户,40%是活跃用户/连续消费用户。
# ### 4.5用户购买周期(按订单)
# - 用户消费周期描述
# - 用户消费周期分布
# In[41]:
#每个用户多笔订单间隔
order_diff = df.groupby('Id').apply(lambda x:x.Date-x.Date.shift())
order_diff.head(10)
# - shift函数是一个偏移函数,和excel上的offset差不多。x.shift(1)是往下偏移一个位置,x.shift(-1)是往上偏移一个位置,加参数axis=1则是左右偏移。
# - 当想求用户下一次距本次消费的时间间隔,用shift(-1)减当前值即可。
# In[42]:
order_diff.describe()
# - 可以看出用户平均消费间隔是68天,中位值是31天,想要召回用户,在60天左右的消费间隔是比较好的。
# In[43]:
(order_diff/np.timedelta64(1,'D')).hist(bins=20)
plt.title('用户消费间隔分布')
plt.xlabel('两次消费间隔天数')
plt.ylabel('用户数')
plt.show()
# - 直方图呈典型长尾指数分布,绝大部分用户购买周期都低于100天,建议将时间召回点设为消费后立即赠送优惠券,消费后10天询问用户CD怎么样,消费后30天提醒优惠券到期,消费后60天短信推送。
# ### 4.6用户生命周期(按第一次&最后一次消费)
# - 用户生命周期描述
# - 用户生命周期分布
# In[44]:
#max-min数据类型是timedelta时间,无法作直方图,通过除timedelta函数换算成数值。
#np.timedelta64(1, 'D'),表示1天,作为单位使用。两者相除就是周期的天数float型。
life_time['life_time']=(life_time['max']-life_time['min'])/np.timedelta64(1,'D')
# In[45]:
life_time['life_time'].describe()
# - 对用户第一次消费和最后一次消费的时间相减,得出每一位用户的生命周期。因为数据中的用户都是前三个月第一次消费,所以这里的生命周期代表的是1-3月用户的生命周期。随着后续消费,用户的平均生命周期可能会增长。
# - 用户平均消费周期是134天,但中位数仅0天,超过50%的用户仅消费一次。
# In[66]:
plt.figure(figsize=(16,4))
plt.subplot(121)
life_time['life_time'].hist(bins=40)
plt.title('用户生命周期分布')
plt.xlabel('用户生命周期')
plt.ylabel('用户数')
plt.subplot(122)
life_time[life_time.life_time>0].life_time.hist(bins=100,figsize=(12,6))
plt.title('消费过两次及以上老客生命周期分布')
plt.xlabel('用户生命周期')
plt.ylabel('用户数')
plt.show()
# - 用户的生命周期受只购买一次的用户影响比较厉害(可以排除),计算所有消费过两次以上老客的生命周期。
# - 筛选出lifetime>0,排除仅消费一次的用户,做直方图。
#
# 这是双峰趋势图,仍旧有不少用户生命周期靠拢在0天。部分质量差的用户,虽然消费了两次,但是仍旧无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50天~300天,属于普通型的生命周期,高质量用户的生命周期,集中在400天以后,这已经属于忠诚用户了
# In[70]:
# 400天+的用户占老客比
(life_time[life_time.life_time>400].size)/(life_time[life_time.life_time>0].size)*100
# In[71]:
#400天+的用户占总量比
(life_time[life_time.life_time>400].size)/(life_time.size)*100
# - 忠实用户占老客比31.70%、占总量比15.49%。
# - 对新客户采取更多激励措施,促使其成为老客,能够更大比例的创造忠诚客户。
# ## 5.复购率和回购率分析
# - ### 5.1复购率
# - 购买多次的用户占比
# - 自然月内,购买多次的用户占比
# - ### 5.2回购率
# - 留存率(仅计算新客,多少用户第一次消费后仍旧消费)
# - 曾经购买过的用户在某一时期内再次购买的占比
# ### 5.1复购率
#
# 定义:在某时间窗口内消费两次及以上用户在总消费用户中占比。这里时间窗口是月,如果一个用户在同一天下了两笔订单,也将他算作复购用户。
# 数据转换:消费两次及以上记为1,消费一次记为0,没有消费记为NaN。
# In[49]:
pivoted_counts = df.pivot_table(index='Id',
columns='month',
values='Date',
aggfunc='count').fillna(0)
columns_month = df.month.sort_values().astype('str').unique()
pivoted_counts.columns = columns_month
pivoted_counts.head()
# In[50]:
pivoted_counts_transf = pivoted_counts.applymap(lambda x:1 if x>1 else (np.NaN if x == 0 else 0))
pivoted_counts_transf.head()
# applymap针对DataFrame里的所有数据。用lambda进行判断,因为这里涉及了多个结果,所以要两个if else,记住,lambda没有elif的用法。
#
# ### 5.2回购率
# 回购率是某时间窗口内消费的用户,在下一时间窗口仍旧消费的占比。
# 1月消费用户1000,他们中有300个2月依然消费,回购率是30%。
# 再次用applymap+lambda转换数据,只要有过购买,记为1,反之为0。
# In[52]:
def purchase_return(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status,index=columns_month)
pivoted_purchase_return = pivoted_purchase.apply(purchase_return,axis=1)
pivoted_purchase_return.head()
# * 新建判断函数purchase_return()。data是输入数据,即用户在18个月内是否消费的记录,status是空列表,后续用来保存用户是否回购的字段。
# * 因为有18个月,所以每个月都要进行一次判断,需要用到循环。if的主要逻辑是,如果用户本月进行过消费,且下月消费过,记为1,没有消费过是0。本月若没有进行过消费,为NaN,后续的统计中进行排除。
# * 用apply函数应用在所有行上,获得想要的结果。
# In[80]:
plt.figure(figsize=(16,8))
plt.subplot(211)
(pivoted_counts_transf.sum()/pivoted_counts_transf.count()).plot(figsize=(10,4))
plt.title('用户复购率/回购率随时间变化趋势')
plt.ylabel('复购率')
plt.subplot(212)
(pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot(figsize=(10,4))
plt.xlabel('日期')
plt.ylabel('回购率')
plt.show()
# * 用sum和count相除计算出复购率。因为这两个函数都会忽略NaN,而NaN是没有消费的用户,count不论0还是1都会统计,所以是总的消费用户数,而sum求和计算了两次以上的消费用户。这里用了比较巧妙的替代法计算复购率,SQL中也可以用。
# ---
# * 前三个月因为有大量新用户涌入,而这批用户只购买了一次,所以导致复购率降低,譬如1月复购率只有6%左右。而在后期,复购率稳定在20%左右。
# * 单看新客和老客,复购率有三倍左右的差距。
# * 用户回购率高于复购,约在30%左右,波动性也较强。新用户的回购率在15%左右,和老客差异不大。
# * 将回购率和复购率综合分析,可以得出,新客的整体质量低于老客,老客忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
# # 留存率
# - 指用户在第一次消费后,有多少比率进行第二次消费。和回流率的区别是留存倾向于计算第一次消费,并且有多个时间窗口。
# In[54]:
#将user_purchase按照user_id拼接上用户第一次消费的时间
user_purchase = df[['Id','Quantity','TotalPrice','Date']]
Date_min = user_purchase.groupby('Id').Date.min()
Date_max = user_purchase.groupby('Id').Date.max()
user_purchase_retention = pd.merge(left=user_purchase,right=Date_min.reset_index(),
how='inner',on='Id',suffixes=('','_min'))
user_purchase_retention.head(5)
# 这里用到merge函数,它和SQL中的join差不多,用来将两个DataFrame进行合并。我们选择了inner 的方式,对标inner join。即只合并能对应得上的数据。这里以on=user_id为对应标准。这里merge的目的是将用户消费行为和第一次消费时间对应上,形成一个新的DataFrame。suffxes参数是如果合并的内容中有重名column,加上后缀。
#
# 除了merge,还有join,concat,用法接近,查看文档即可。
# In[55]:
user_purchase_retention['date_diff']=(user_purchase_retention.Date-user_purchase_retention.Date_min)/np.timedelta64(1,'D')
user_purchase_retention.head()
# 这里将order_date和order_date_min相减。获得一个新的列,为用户每一次消费距第一次消费的时间差值。
# In[56]:
bin=[0,3,7,15,30,60,90,180,365]
user_purchase_retention['date_diff_bin'] = pd.cut(user_purchase_retention.date_diff,bins=bin)
# In[57]:
user_purchase_retention.head(20)
# - 将时间差值分桶。
# - 分成0~3天内,3~7天内等,代表用户当前消费时间距第一次消费属于哪个时间段。
# - date_diff=0没有被划分入0~3天,因为计算的是留存率,如果用户仅消费了一次,留存率应该是0;另外一方面,如果用户第一天内消费多次,但是往后没有消费,留存率也算作0。
# In[58]:
#用户在第一次消费之后,在后续各时间段内的消费总额。
pivoted_retention = user_purchase_retention.pivot_table(index='Id',columns='date_diff_bin',
values='TotalPrice',aggfunc=sum)
pivoted_retention.head(10)
# In[59]:
pivoted_retention.mean()
# - 计算用户在后续各时间段平均消费额,这里只统计有消费的平均值。虽然后面时间段金额高,但它时间范围也宽广。从平均效果看,用户第一次消费后的0~3天内,更可能消费更多。
# - 但消费更多是一个相对的概念,还要看整体中有多少用户在0~3天消费。
# In[60]:
pivoted_retention_trans = pivoted_retention.fillna(0).applymap(lambda x:1 if x>0 else 0)
pivoted_retention_trans.head()
# 依旧将数据转换成是否,1代表在该时间段内有后续消费,0代表没有。
# In[61]:
(pivoted_retention_trans.sum()/pivoted_retention_trans.count()).plot.bar()
# 只有5%的用户在第一次消费的次日至3天内有过消费,7%的用户在3~7天内有过消费。数字并不好看,CD购买确实不是高频消费行为。时间范围放宽后数字好看了不少,有43%的用户在第一次消费后的三个月到半年之间有过购买,57%的用户在半年后至1年内有过购买。从运营角度看,CD机营销在拉取新用户的同时,应该注重用户忠诚度的培养,放长线掉大鱼,在一定时间内召回用户购买。
# 怎么算放长线掉大鱼呢?我们计算出用户的平均购买周期。
# In[62]:
grouped = user_purchase_retention.groupby('Id')
i = 0
for user,group in grouped:
print(group)
i+=1
if i == 2:
break
# 我们将用户分组,groupby分组后的数据,也是能用for进行循环和迭代的。第一个循环对象user,是分组的对象,即Id;第二个循环对象group,是分组聚合后的结果。整个输出是一组切割后的DataFrame。不建议用for循环,它的效率非常慢。要计算用户的消费间隔,确实需要用户分组,但是用apply效率更快。
# In[63]:
def diff(group):
d = group.date_diff-group.date_diff.shift(-1)
return d
last_diff = user_purchase_retention.groupby('Id').apply(diff)
last_diff.head(10)
# In[64]:
last_diff.mean()
# In[65]:
last_diff.hist(bins=20)
# - 从直方图可以看出,典型的长尾分布,大部分用户消费间隔确实比较短。
# - 不妨将时间召回点设为消费后立即赠送优惠券,消费后10天询问用户CD怎么样,消费后30天提醒优惠券到期,消费后60天短信推送。这便是数据的应用了。
# ## 6.未来思考与结论
#
# 1. 1月、2月、3月的新用户在留存率有没有差异?
# 2. 不同生命周期的用户,他们的消费累加图是什么样的?
# 3. 消费留存,划分其他时间段怎么样?
# 4. 用户生命周期,用户购买频次,留存率、复购率、回购率等等。

END

"脚下有路,前方有光"
扫码关注更多精彩


















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









