







一、前言
UEBA(User Entity Behavior Analytics)作为一种异常行为分析的方法,在安全领域已经有了较为深入的应用,早在 2016 年Gartner 就已经将其作为当年十大信息安全技术之一。在SOC、SIEM等产品中集成UEBA能力已经成为时下热门的趋势。
国内主流的厂商的技术及方案不尽相同,但主要集中在企业安全这一方向,这或许是因为在企业安全的威胁场景中,UEBA的分析效果更明显。企业安全中有两个关键的要素:资产与人。在传统的解决方案(如SOC类)中更加关注资产面临的风险往往忽视了人的重要性,这在近年来不断出现的信息泄露事件中可见一斑。当然,概念再好也要在实际生产中能够落地,下面将从一个小的点切入,分享一下UEBA中典型的采用KDE算法对人员行为基线进行建模及分析的方法。
二、KDE
核密度估计(Kernel Density Estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出(百科)。我的理解是该算法需要找出点的**处于某个区间的概率。例如[7,8,9,14,15,22,23,24,25],设宽度(范围区间)为10,则采用直方图表示如下: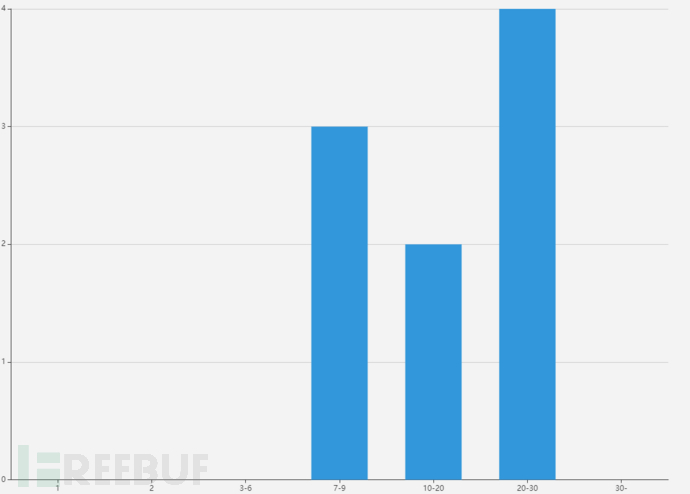
很显然,直方图不够平滑,受宽度影响很大,为了使分布更接近于真实,KDE采用相关的核函数计算点的密度分布,概率密度如下: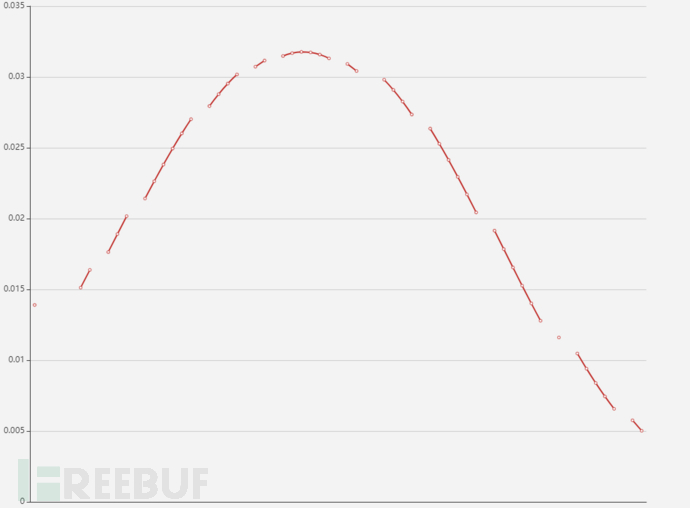
本质上KDE属于聚类算法的一种。对于核函数类型的选择则根据场景的不同而不同,这里采用Epanechnikov曲线。宽度的选择对结果有影响,一般结合经验设置宽度。
三、基线建模
假设一个企业安全场景:公司内部系统如企业邮箱、OA、文件服务器等访问需要先登陆VPN,各地分公司也需要VPN接入企业内网。现在需要根据VPN相关的日志来分析可能存在的风险或违规操作。对用户登陆VPN系统的时间基线进行建模,可以有效的发现用户当前是否有偏离以往操作习惯的行为,以便通过专家方法进行更深入的分析。主要步骤如下:
1、获取具体用户某段时间范围内VPN操作时间日志
2、以此为训练样本,训练用户行为基线,绘制概率密度分布曲线
3、当前操作密度分布与基线进行对比,发现偏离基线,考虑操作存在风险
以用户A为例,一个月当中每天的VPN使用记录如下(横轴为距离0:00点的时间戳,纵轴为记录次数):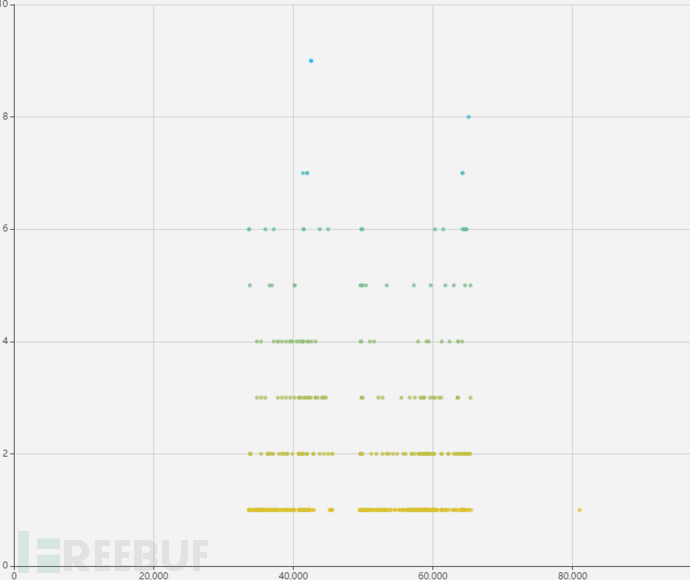
使用KDE算法进行训练,宽度选择1800(半个小时),训练结果如下: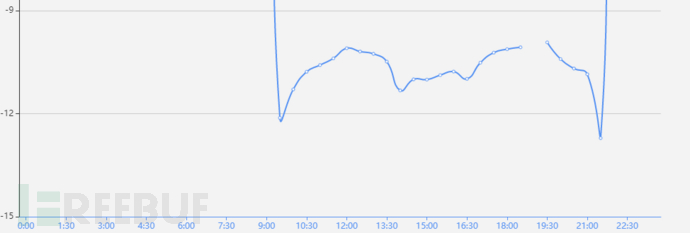
换算到概率密度分布: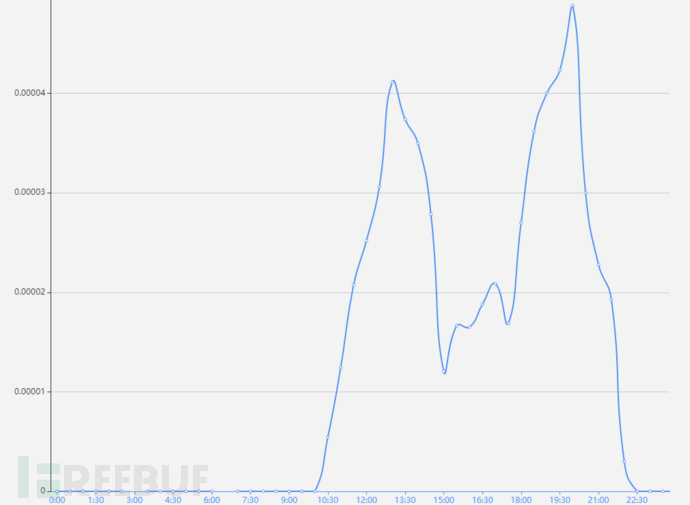
使用使用sklearn库,代码:
a = np.array(l).reshape(-1, 1)
kde = KernelDensity(kernel='tophat', bandwidth=1800).fit(a)
e = kde.score_samples(s.reshape(-1, 1))
plt.plot(s, np.exp(e))
取A用户当前使用数据(红色线),计算后与基线进行对比:
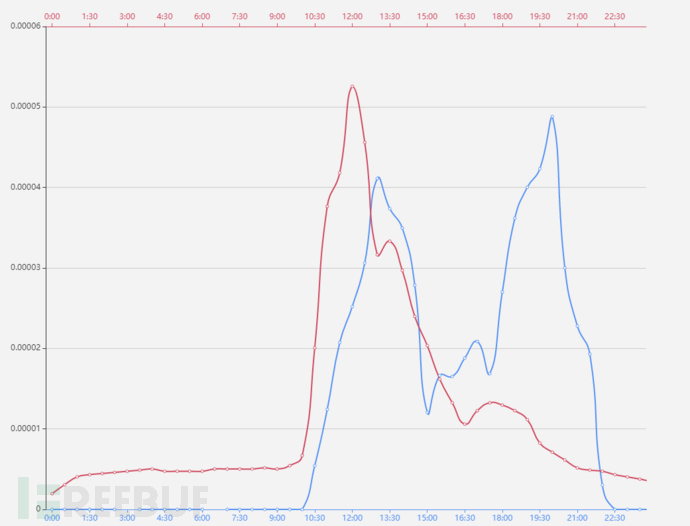
对比发现10:00之前操作偏离基线,提示用户行为异常。以上是对时间序列的分析,实际上,基线还包括访问记录、访问源等。根据企业的安全风险场景,结合UEBA的分析方法发掘潜在威胁,降低风险发生概率。
Life is short,You need UEBA!















 2267
2267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









