







原文:http://blog.csdn.net/book_mmicky/article/details/25714445
Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对不同场景而已:
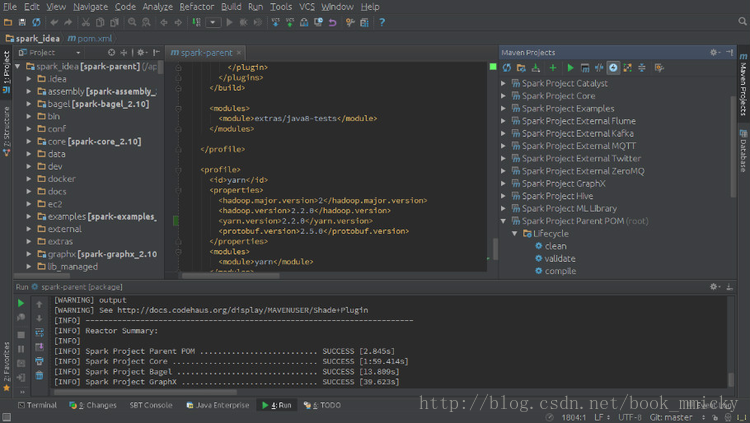
在maven projects视图选择Spark Project Parent POM(root),然后选中工具栏倒数第四个按钮(ship Tests mode)按下,这时Liftcycle中test是灰色的。
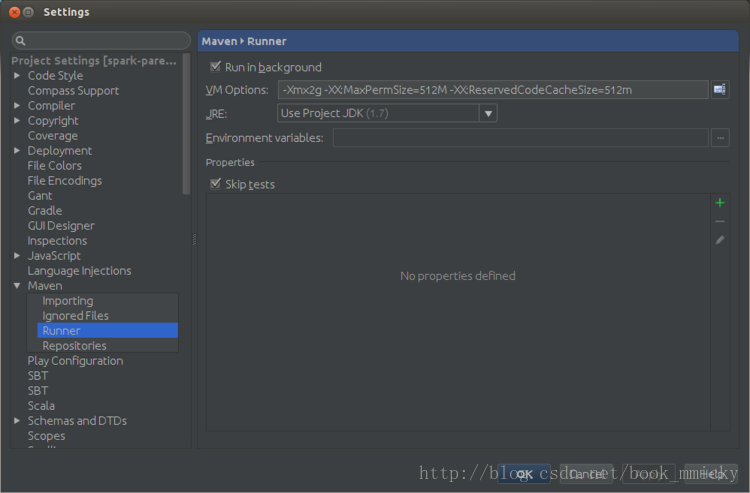
按OK 保存。
回到maven projects视图,点中Liftcycle中package,然后按第5个按钮(Run Maven Build按钮),开始编译。其编译结果和Maven编译是一样的。
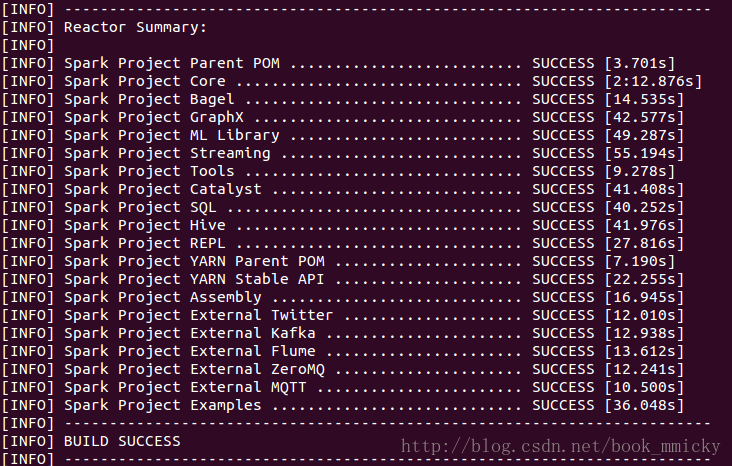
- Maven编译
- SBT编译
- IntelliJ IDEA编译(可以采用Maven或SBT插件编译),适用于开发人员
- 部署包生成(内嵌Maven编译),适用于维护人员
编译的目的是生成指定环境下运行Spark本身或开发Spark Application的JAR包,本次编译的目的生成运行在hadoop2.2.0上的Spark JAR包。缺省编译所支持的hadoop环境是hadoop1.0.4。
1:获取Spark1.0.0 源码
官网下载地址
2:SBT编译
将源代码复制到指定目录,然后进入该目录,运行:
SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true sbt/sbt assembly
3:Maven编译
事先安装好maven3.04或maven3.05,并设置要环境变量MAVEN_HOME,将$MAVEN_HOME/bin加入PATH变量。然后将源代码复制到指定目录,然后进入该目录,先设置Maven参数:
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"再运行:
mvn -Pyarn -Dhadoop.version=2.2.0 -Dyarn.version=2.2.0 -DskipTests clean package
4:IntelliJ IDEA编译
IntelliJ IDEA是个优秀的scala开发IDE,所以顺便就提一下IntelliJ IDEA里的spark编译。
首先将源代码复制到指定目录,然后启动IDEA -> import project -> import project from external model -> Maven编译目录中的pom.xml -> 在选择profile时选择hadoop2.2 -> 直到导入项目。
接着按倒数第一个按钮进入Maven设置,在runner项设置VM option:
-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m
附:执行脚本
生成在部署包位于根目录下,文件名类似于spark-1.0.0-bin-2.2.0.tgz。
TIPS:
#! /bin/bash
SPARK_JAR=assembly/target/scala-2.10/spark-assembly_2.10-1.0.0-SNAPSHOT-hadoop2.2.0.jar
./bin/spark-class org.apache.spark.deploy.yarn.Client \
--jar /root/spark/sh.jar \
--class sh.HdfsWordCount \
--args yarn-standalone \
--args hdfs://master:9101/user/root/hsd.txt \
--args hdfs://master:9101/user/root/outs \
--num-executors 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1
5:生成spark部署包
编译完源代码后,虽然直接用编译后的目录再加以配置就可以运行spark,但是这时目录很庞大,又3G多吧,部署起来很不方便,所以需要生成部署包。
spark源码根目录下带有一个脚本文件make-distribution.sh可以生成部署包,其参数有:
- --hadoop VERSION:打包时所用的Hadoop版本号,不加此参数时hadoop版本为1.0.4。
- --with-yarn:是否支持Hadoop YARN,不加参数时为不支持yarn。
- --with-hive:是否在Spark SQL 中支持hive,不加此参数时为不支持hive。
- --skip-java-test:是否在编译的过程中略过java测试,不加此参数时为略过。
- --with-tachyon:是否支持内存文件系统Tachyon,不加此参数时不支持tachyon。
- --tgz:在根目录下生成 spark-$VERSION-bin.tgz,不加此参数时不生成tgz文件,只生成/dist目录。
- --name NAME:和--tgz结合可以生成spark-$VERSION-bin-$NAME.tgz的部署包,不加此参数时NAME为hadoop的版本号。
如果要生成spark支持yarn、hadoop2.2.0的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
./make-distribution.sh --hadoop 2.2.0 --with-yarn --tgz
如果要生成spark支持yarn、hive的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
./make-distribution.sh --hadoop 2.2.0 --with-yarn --with-hive --tgz
如果要生成spark支持yarn、hadoop2.2.0、techyon的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
./make-distribution.sh --hadoop 2.2.0 --with-yarn --with-tachyon --tgz
值得注意的是:make-distribution.sh已经带有Maven编译过程,所以不需要先编译再打包。
笔者在百度云盘pan.baidu.com/s/1dDmqK4h#dir/path=%2Fdeploy上
6:后记
解压部署包后或者直接在编译过的目录,通过配置conf下的文件,就可以使用spark了。
Spark有下列几种部署方式:
- Standalone
- YARN
- Mesos
- Amazon EC2
其实说部署,还不如说运行方式,Spark只是利用不同的资源管理器来申请计算资源。其中Standalone方式是使用Spark本身提供的资源管理器,可以直接运行;而在YARN运行,需要提供运行Spark Application的jar包(或者直接在NM节点上部署Spark):
maven编译的jar包为:./assembly/target/scala-2.10/spark-assembly-1.0.0-hadoop2.2.0.jar
SBT编译的jar包为:./assembly/target/scala-2.10/spark-assembly-1.0.0-hadoop2.2.0.jar
具体使用参见:
Spark1.0.0 YARN模式部署
众所周知的网络问题,编译的时候经常会发生卡死的现象,对于maven编译,只需要安ctrl+z结束进程重新编译就可以了;而对于sbt编译,由于有时候会有文件锁定的问题,在按ctrl+z结束进程后,最好退出终端后再开启一个新的终端进行编译。















 8230
8230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









