







图像分类
ResNet
1.介绍
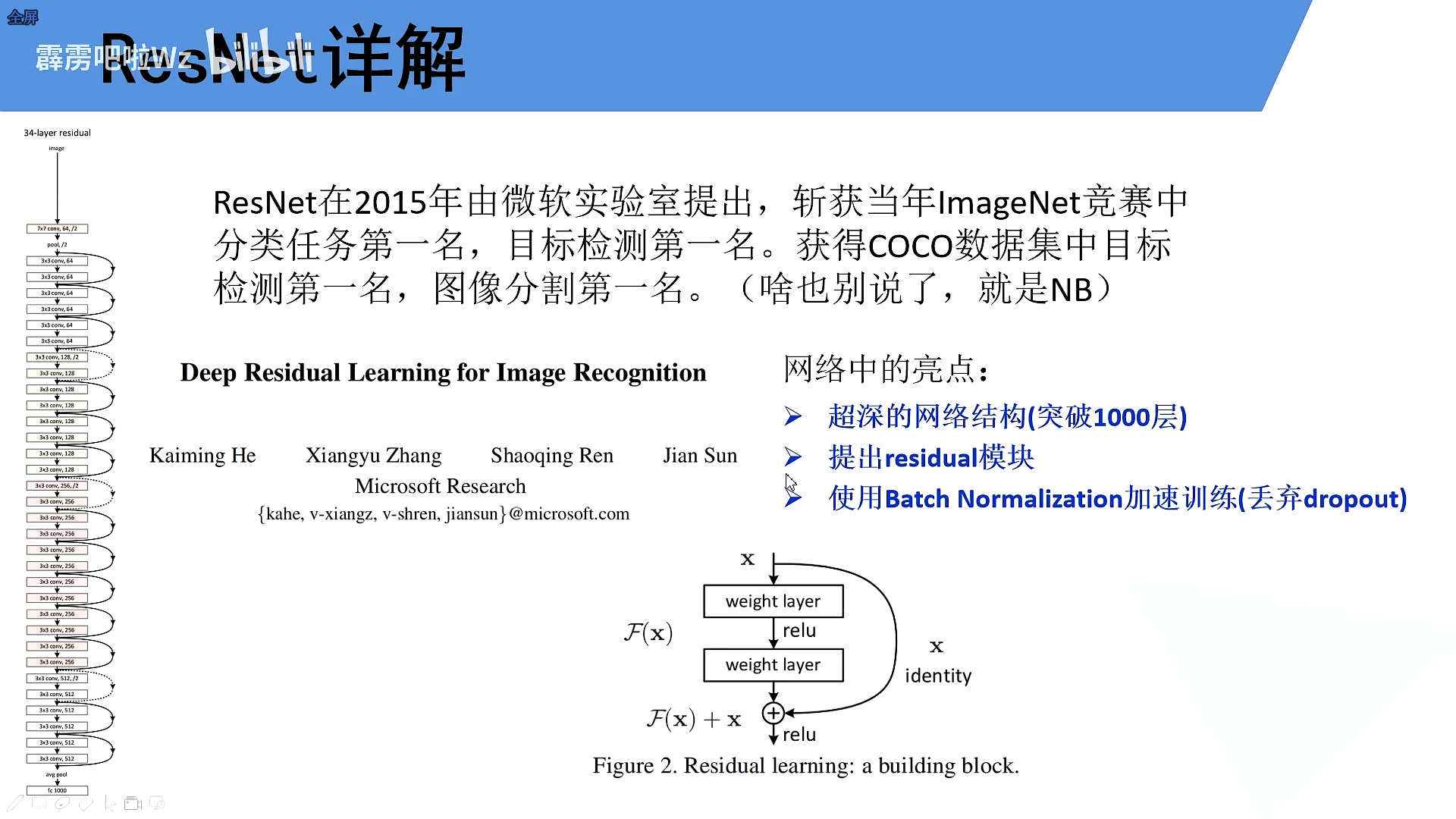
ResNet提出的亮点
- 超深的网络结构
- 提出residual模块
- 使用Batch Normalization加速训练
2.网络太深会出现的问题
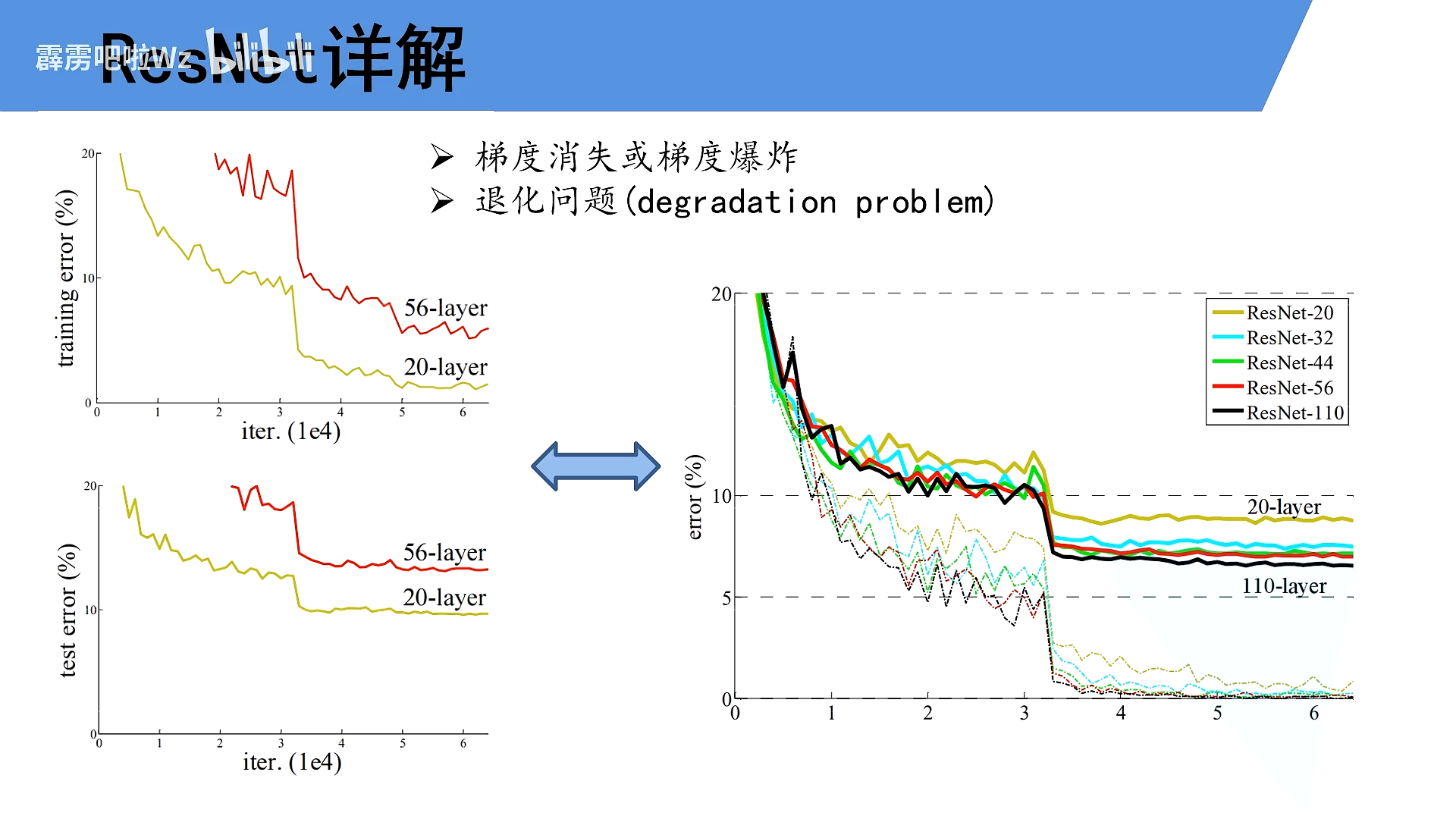
- 梯度消失、梯度爆炸
假设梯度为小于1的数,每向前传播一层,都要乘以一个小于1的误差梯度,越陈越小,几近于0
反过来>1,这爆炸
解决方法:标准化,权重初始化,BN
-
退化问题
解决:使用残差结构
3.Residual结构

使用了1x1卷积显著降低了参数,从100多万降低到7万左右。
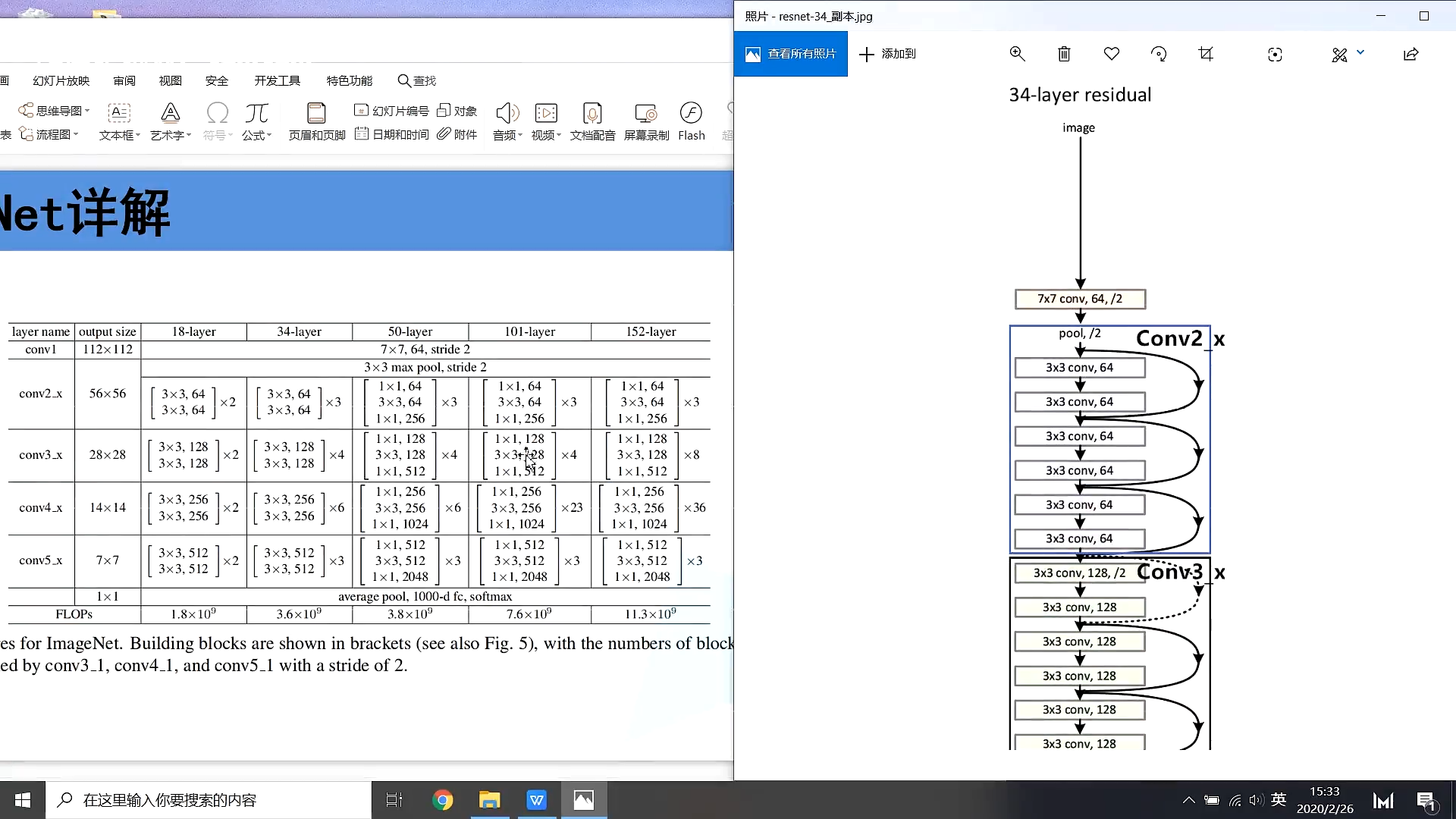
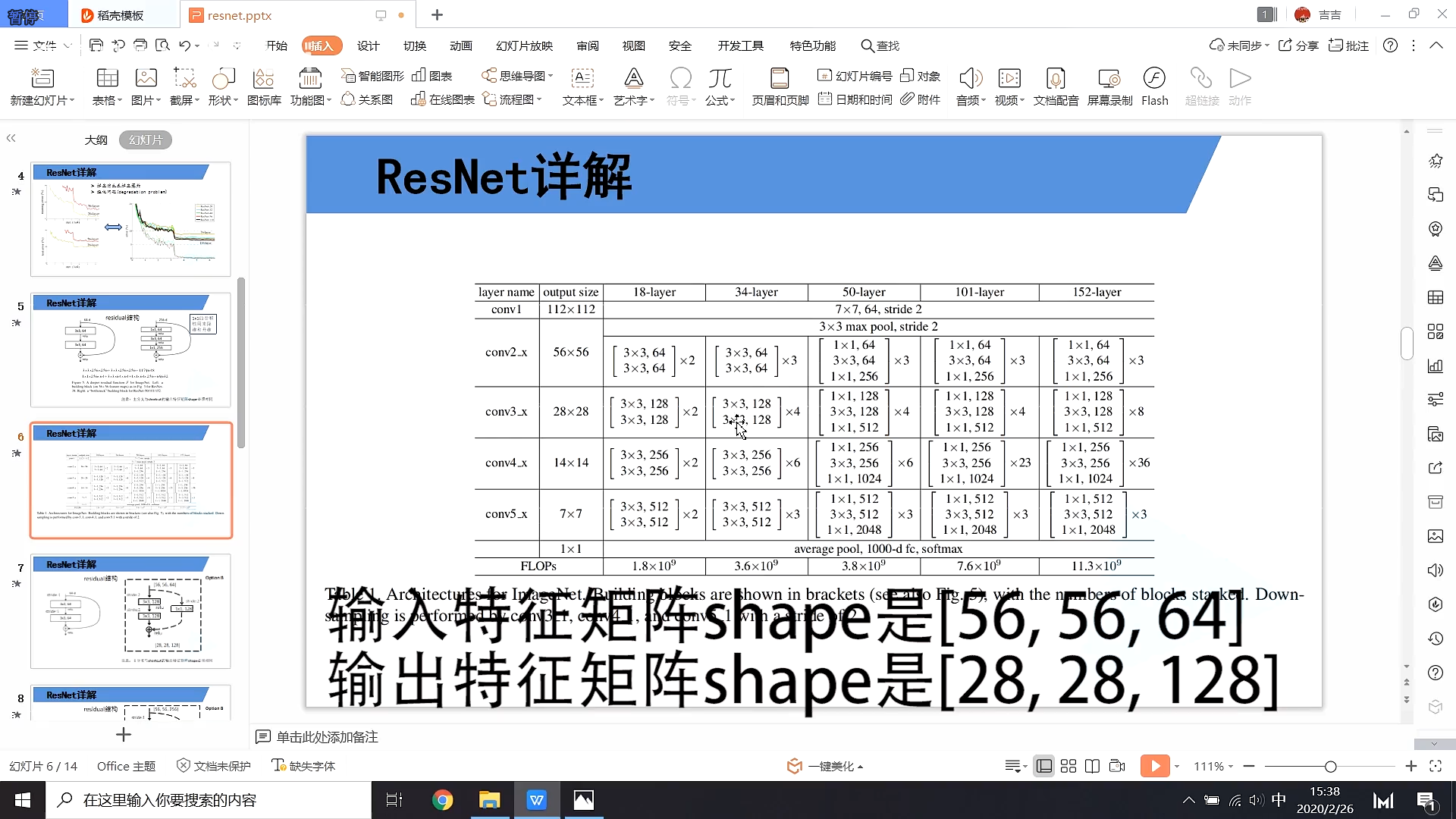
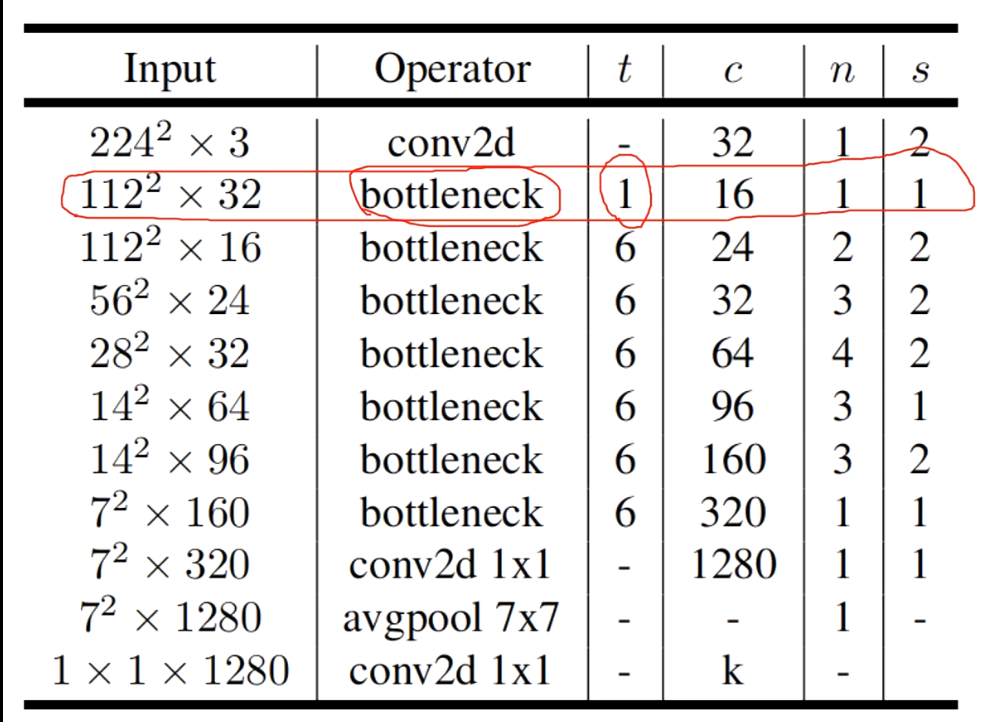
4.模型架构
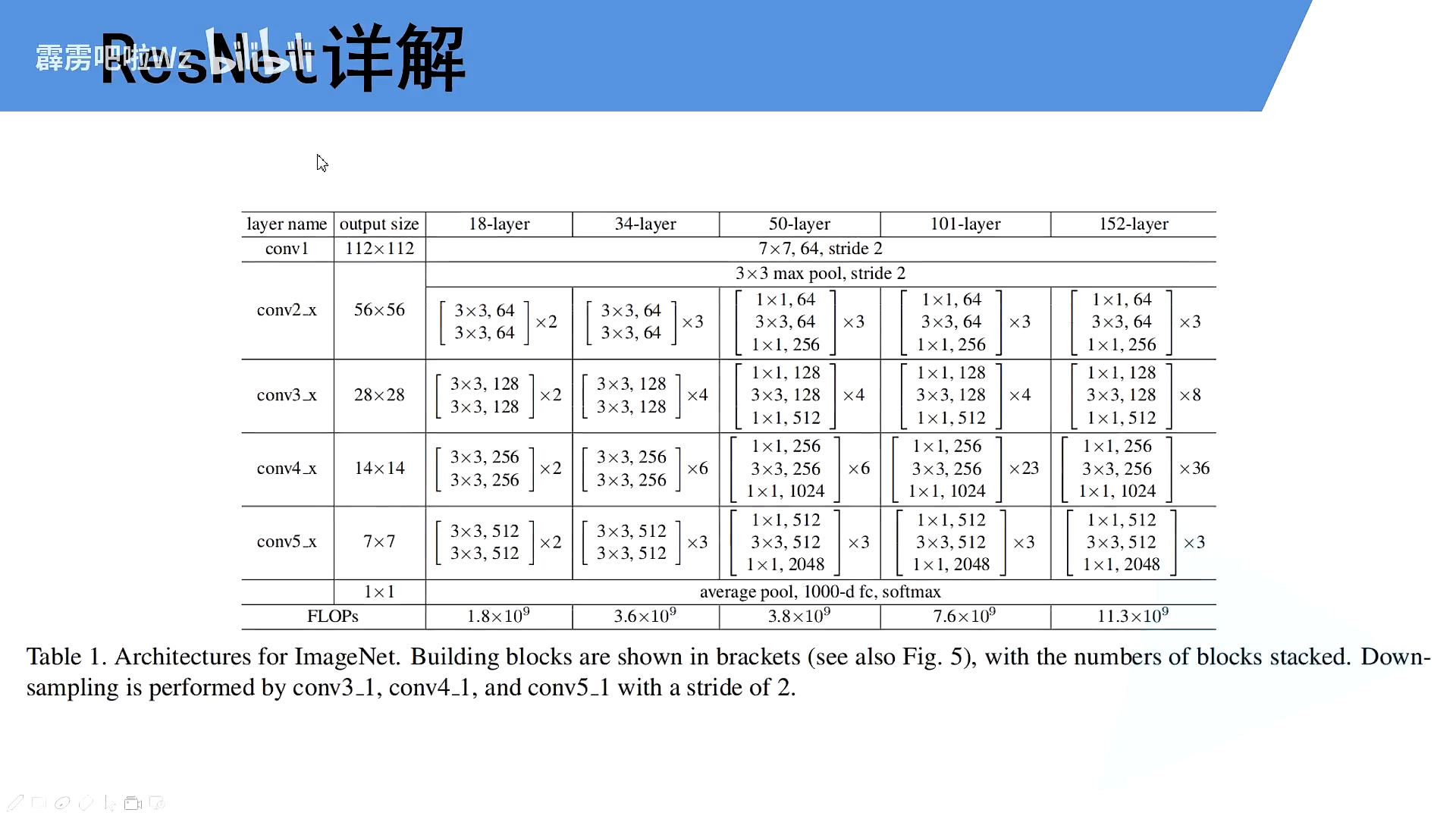
ResNet代码解读
看着结构图,读代码
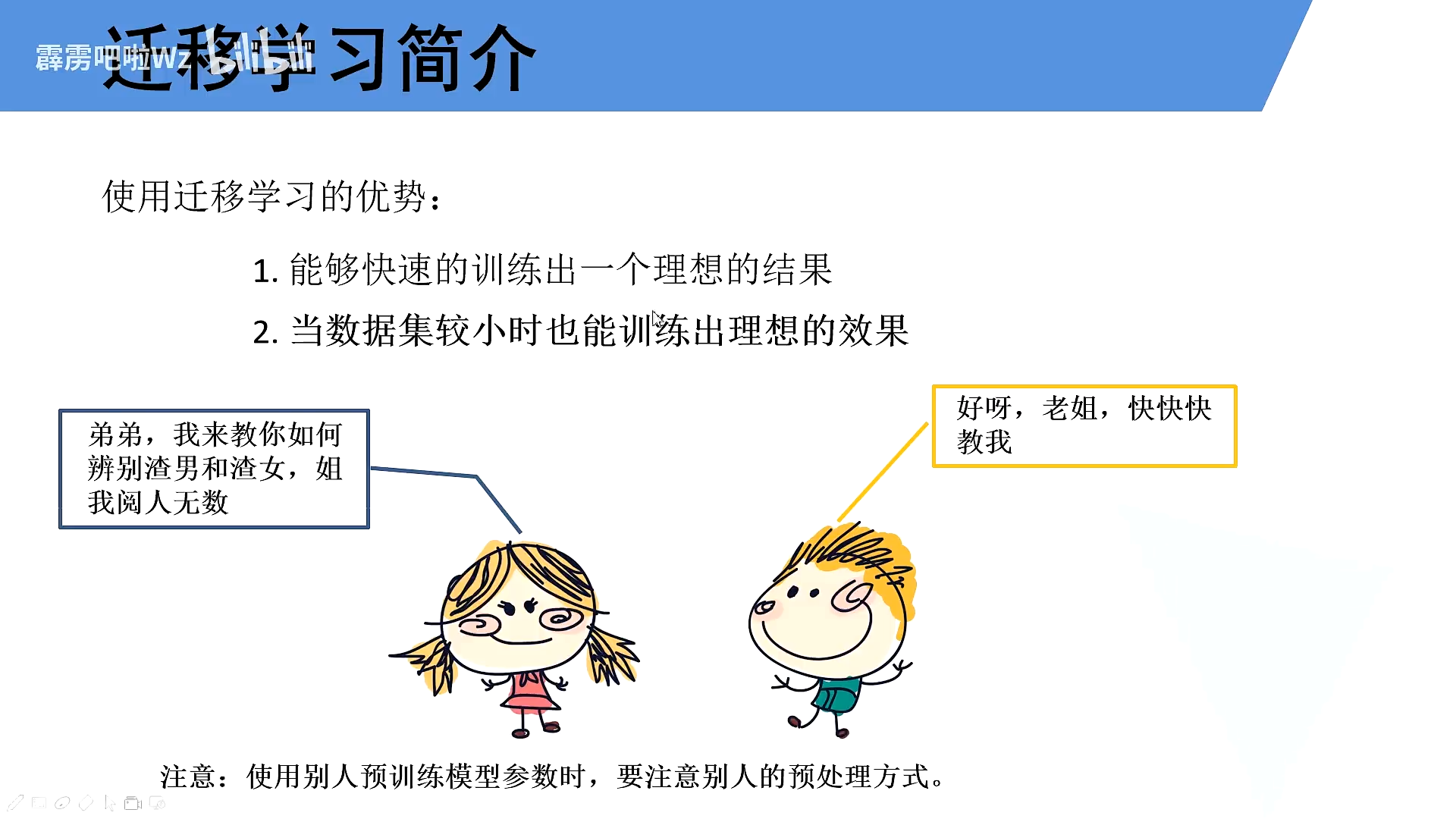
基于迁移学习训练可以更快的收敛
Tips
padding same:卷积后的输出与输入size保持一致

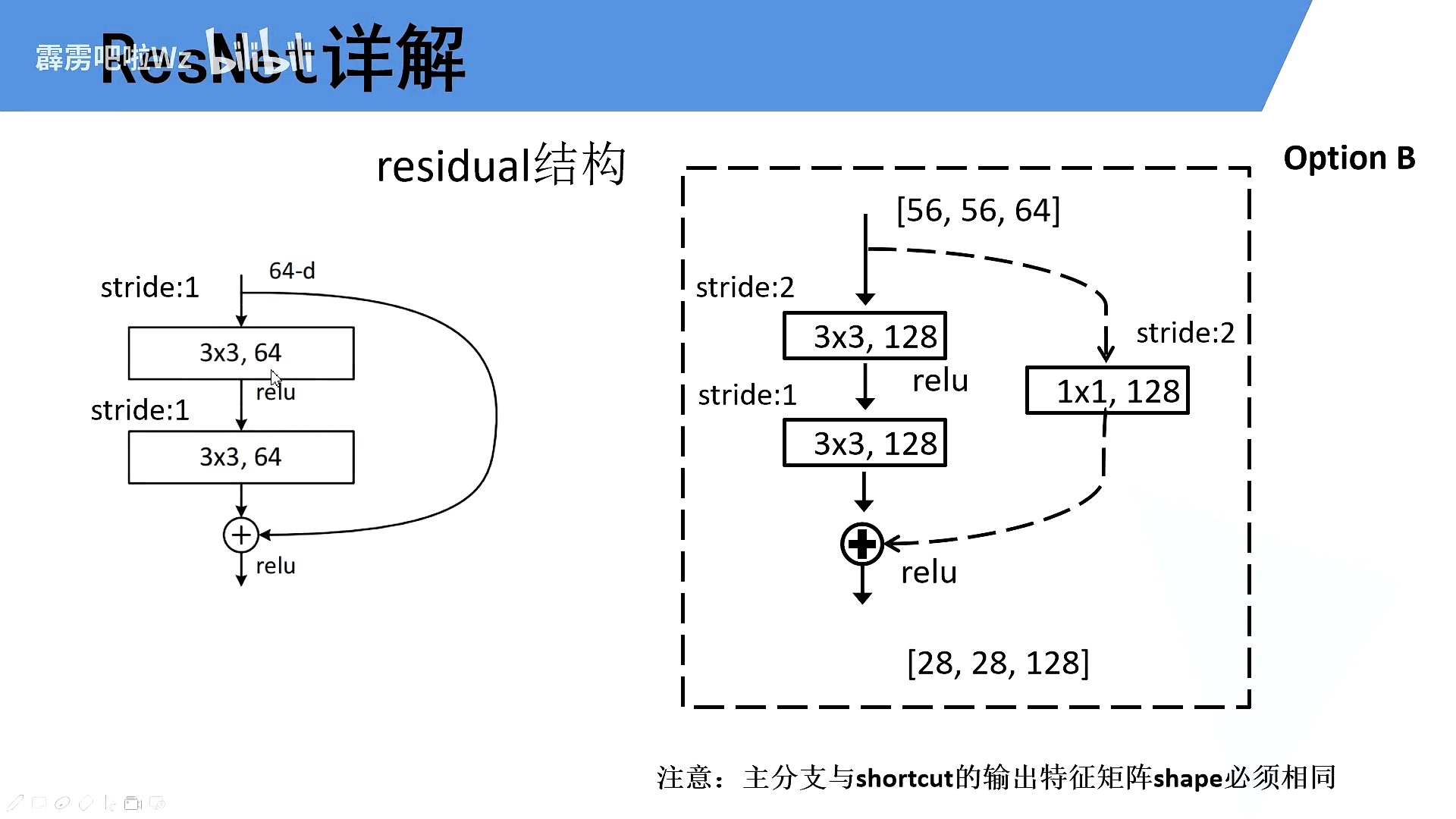
5.Residual中的虚线
实线和虚线有何不同
将主干分支和shortcut的feature map的shape统一
实线:输入和输出的shape相同
虚线:输入和输出的shape不相同
普通残差
更深的残差


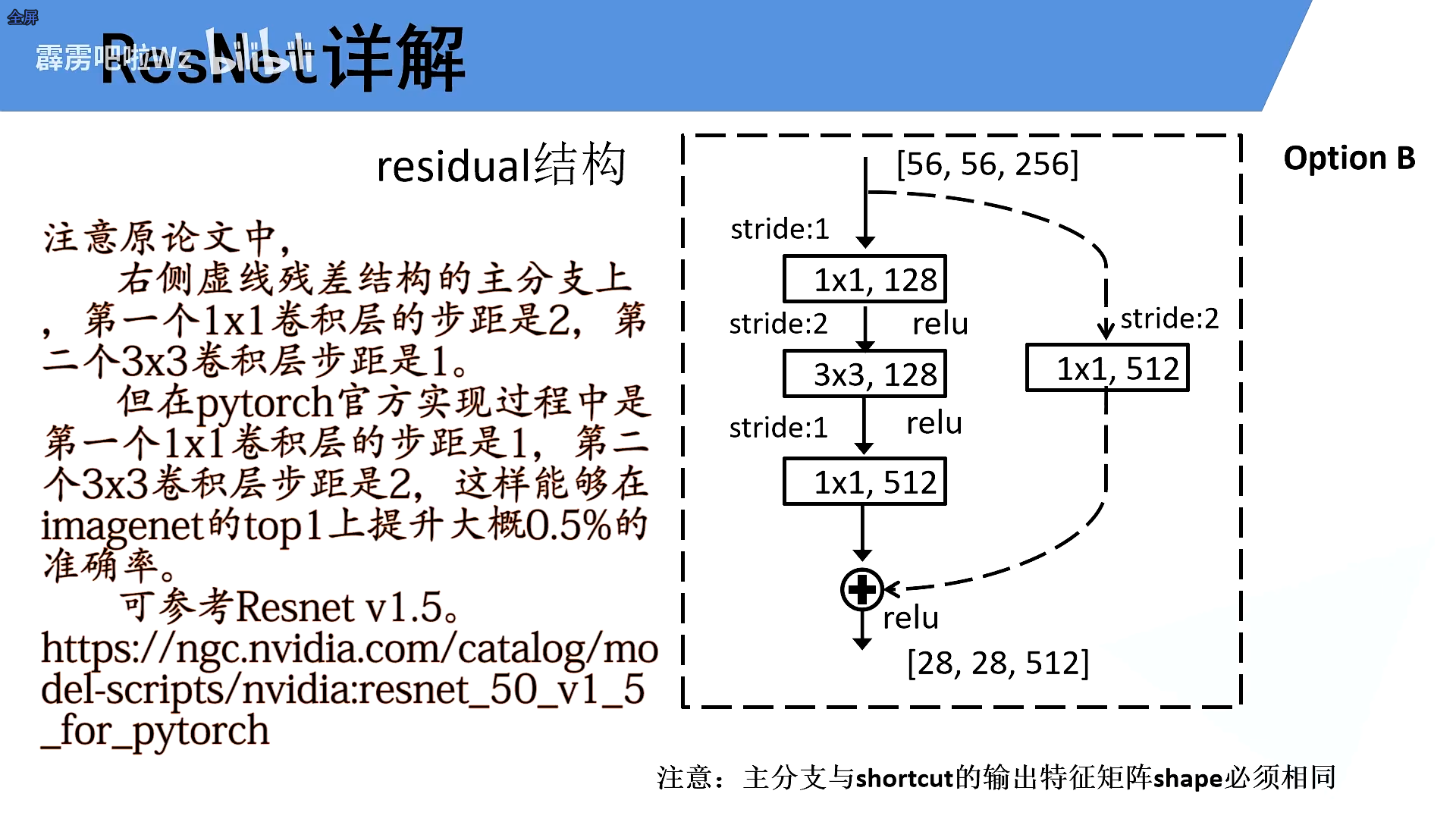
虚线也有不同
18,34层
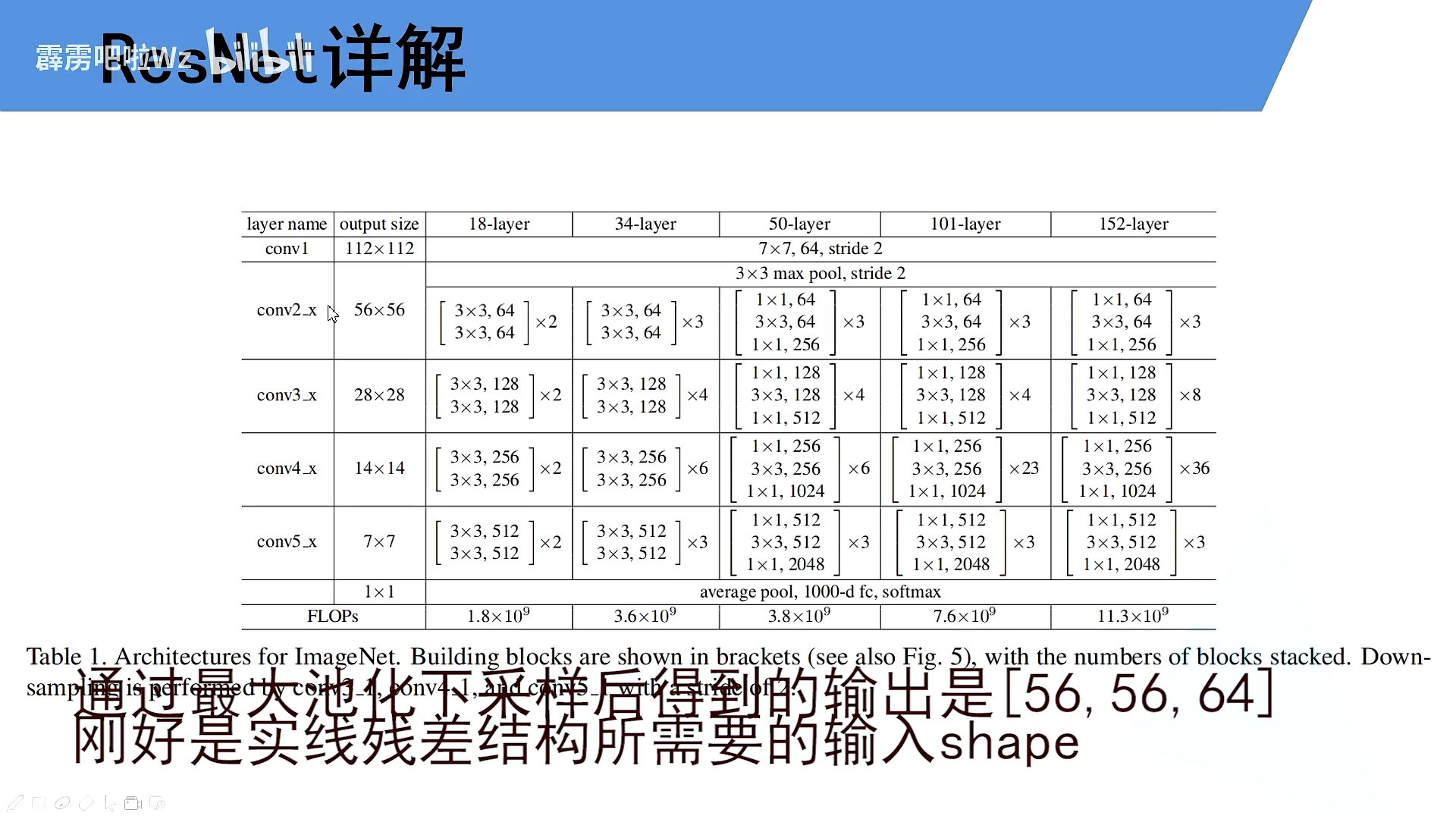
50,101层
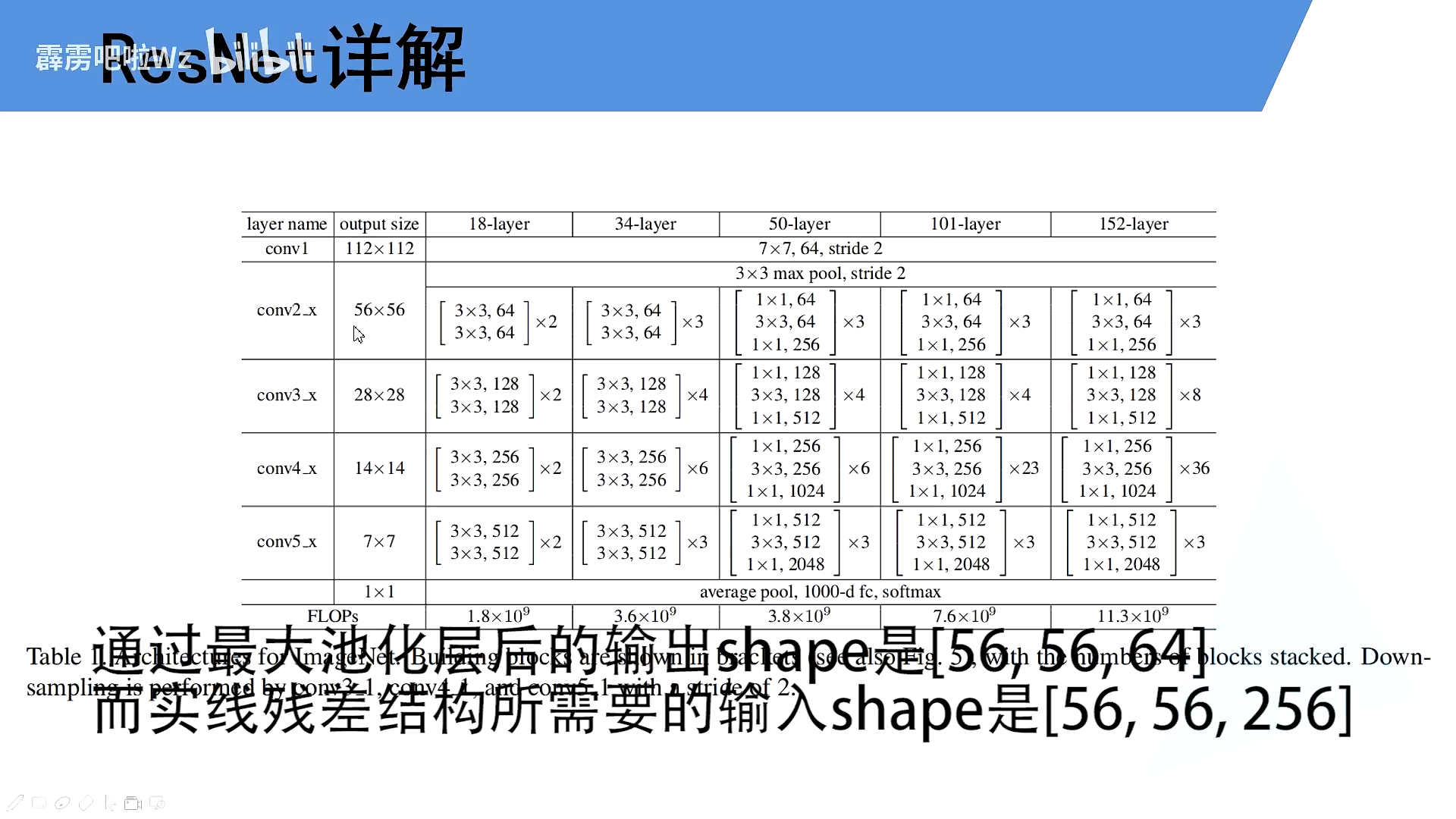
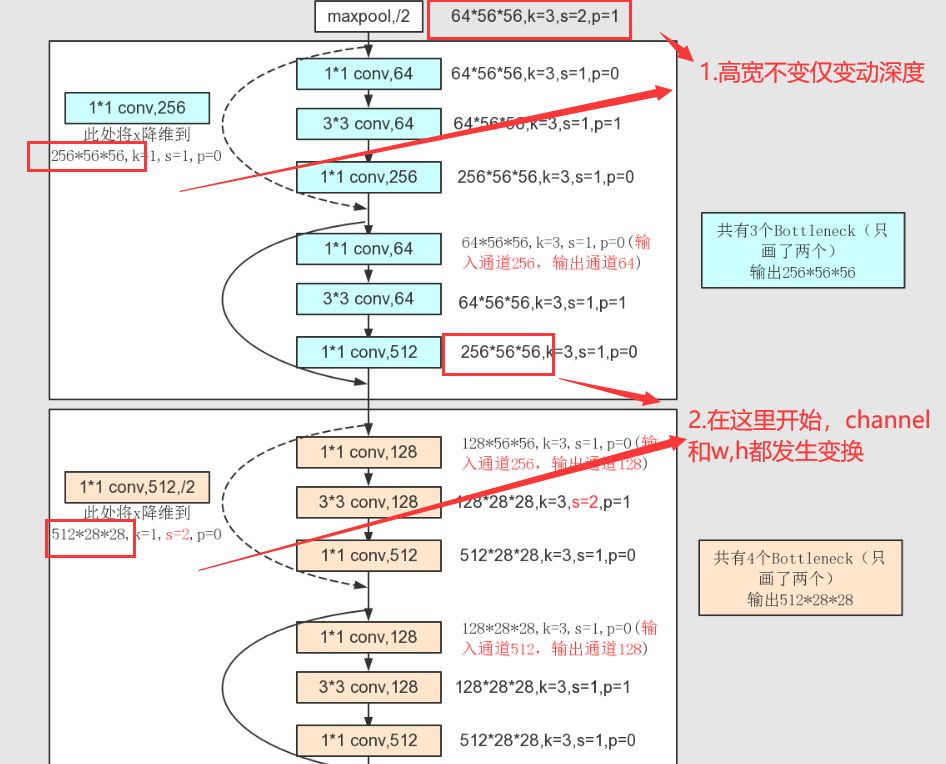
这里的conv2对应的第一个虚线残差层仅调整特征矩阵的深度,高和宽不变
conv3、4不仅的第一个虚线残差层仅调整特征矩阵的深度,高和宽也变化
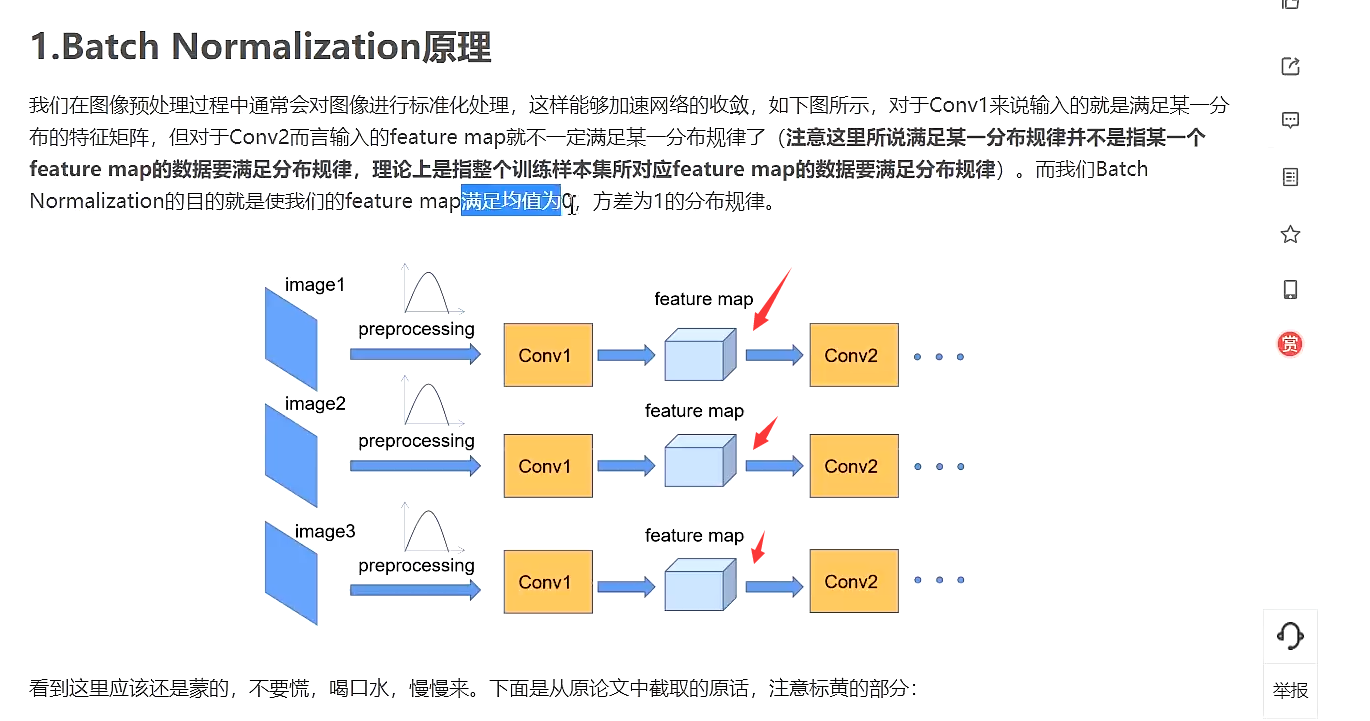
BN
使得一批feature map满足均值为0,方差为1的分布规律

https://blog.csdn.net/qq_37541097/article/details/104434557
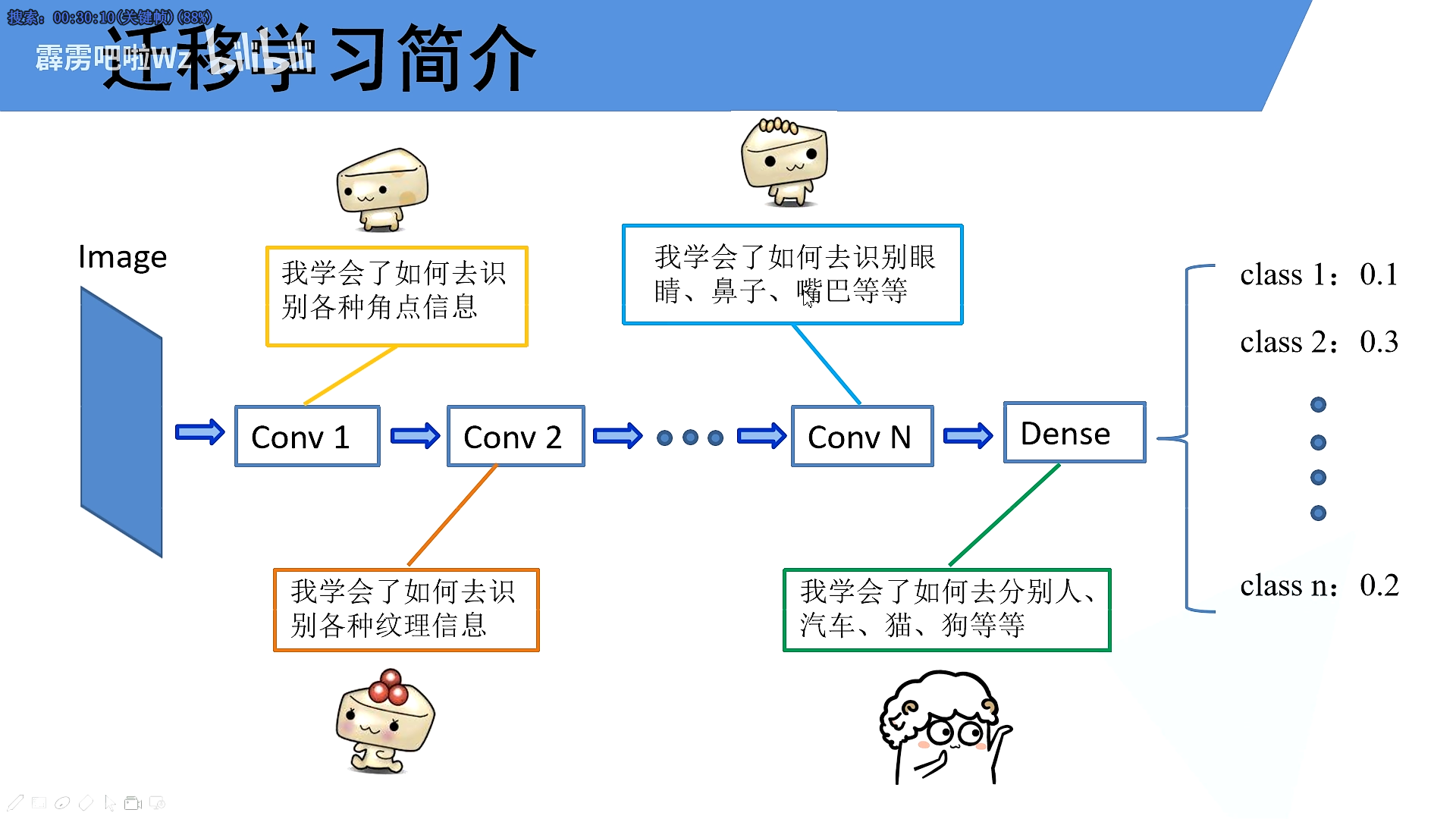
迁移学习

MbileNetv1、v2
1.1.为什么会出现mobileNet呢?
传统卷积神经网络,内存需求大、运算量大导致无法在移动设备以及嵌入式设备上运行

网络中的优点:
- Depthwise Convolution(深度可分离卷积):大大提高运算速度
- 增加超参数α,β
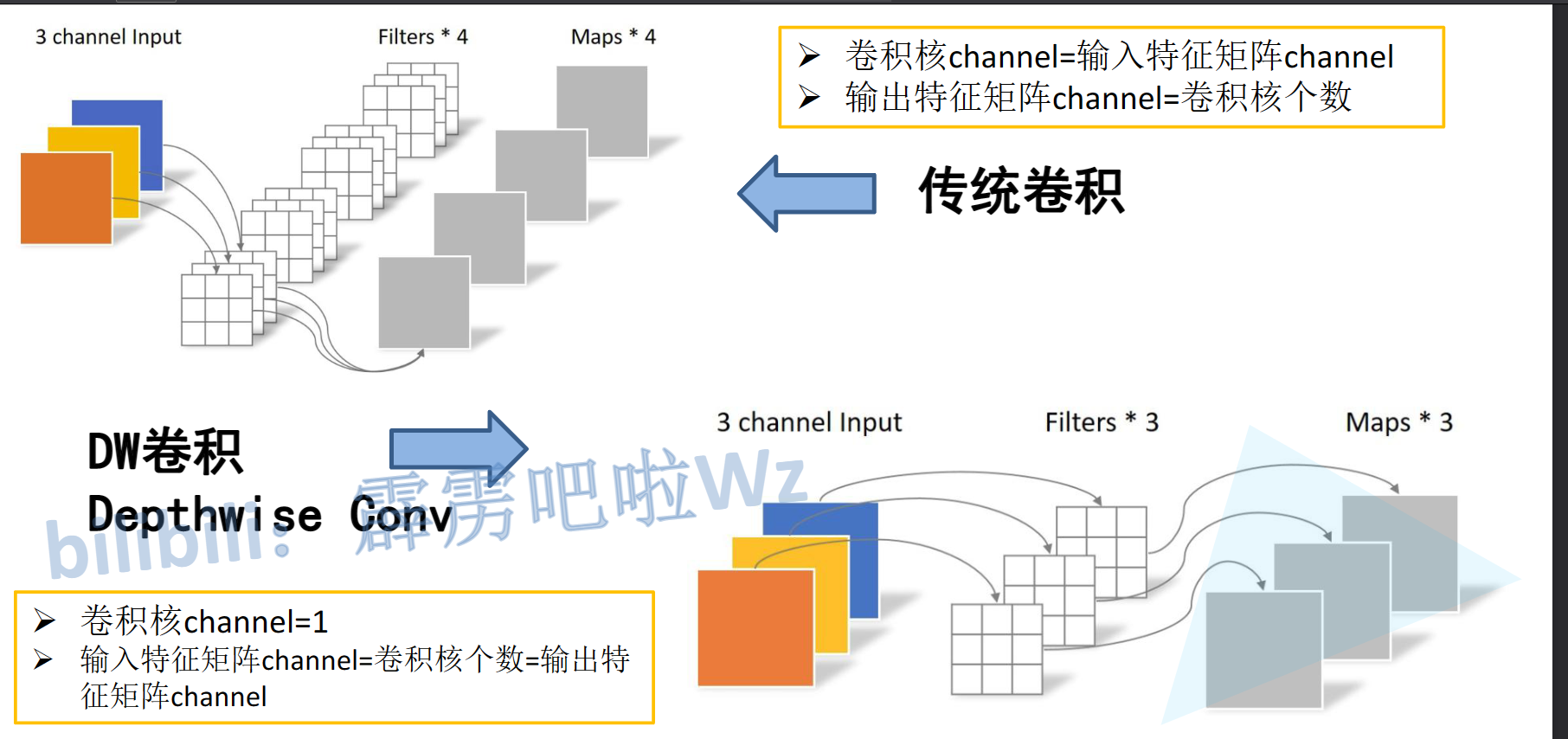
1.2.DW卷积
- 传统卷积
卷积核channel=输入特征矩阵channel
输出特征矩阵channel的卷积核个数
- DW卷积
卷积核channel=1
输入特征矩阵channel=卷积核个数=输出特征矩阵channel
PW卷积
- 本质是1x1卷积核,改变输出深度罢了
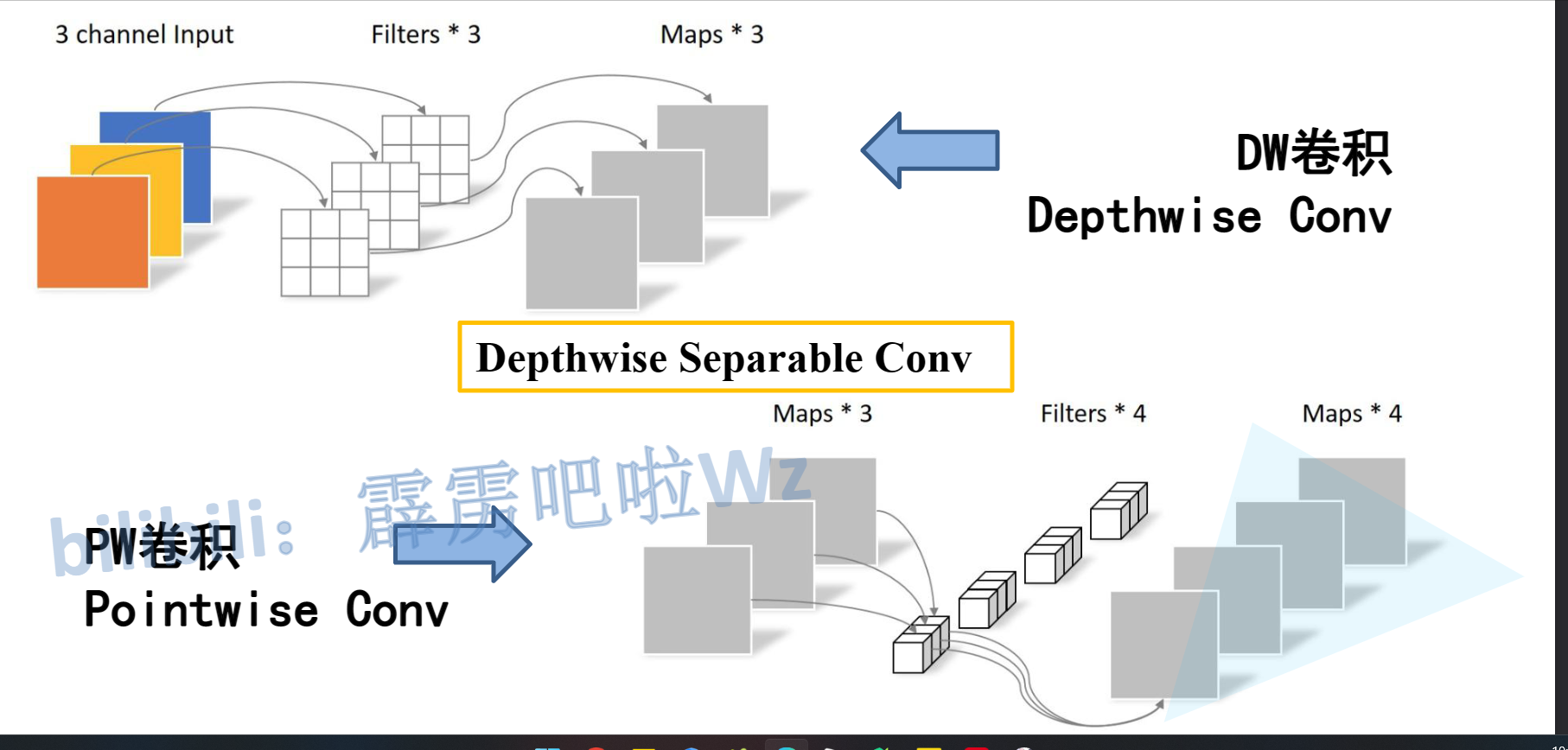
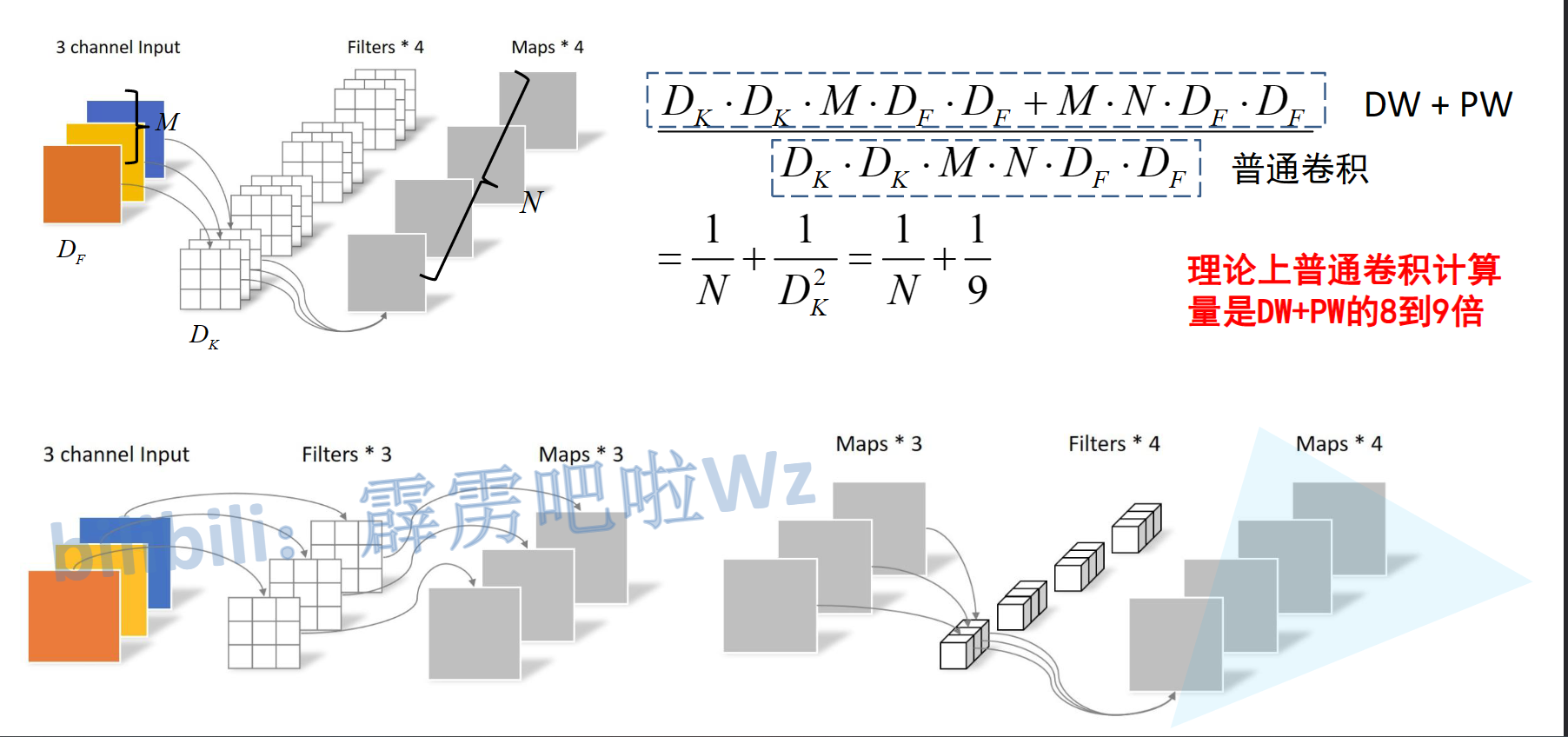
Depthwise Convolution就是将两个卷积融合减少运算量
理论上可以减少到9分之一
1.3.超参数α,β
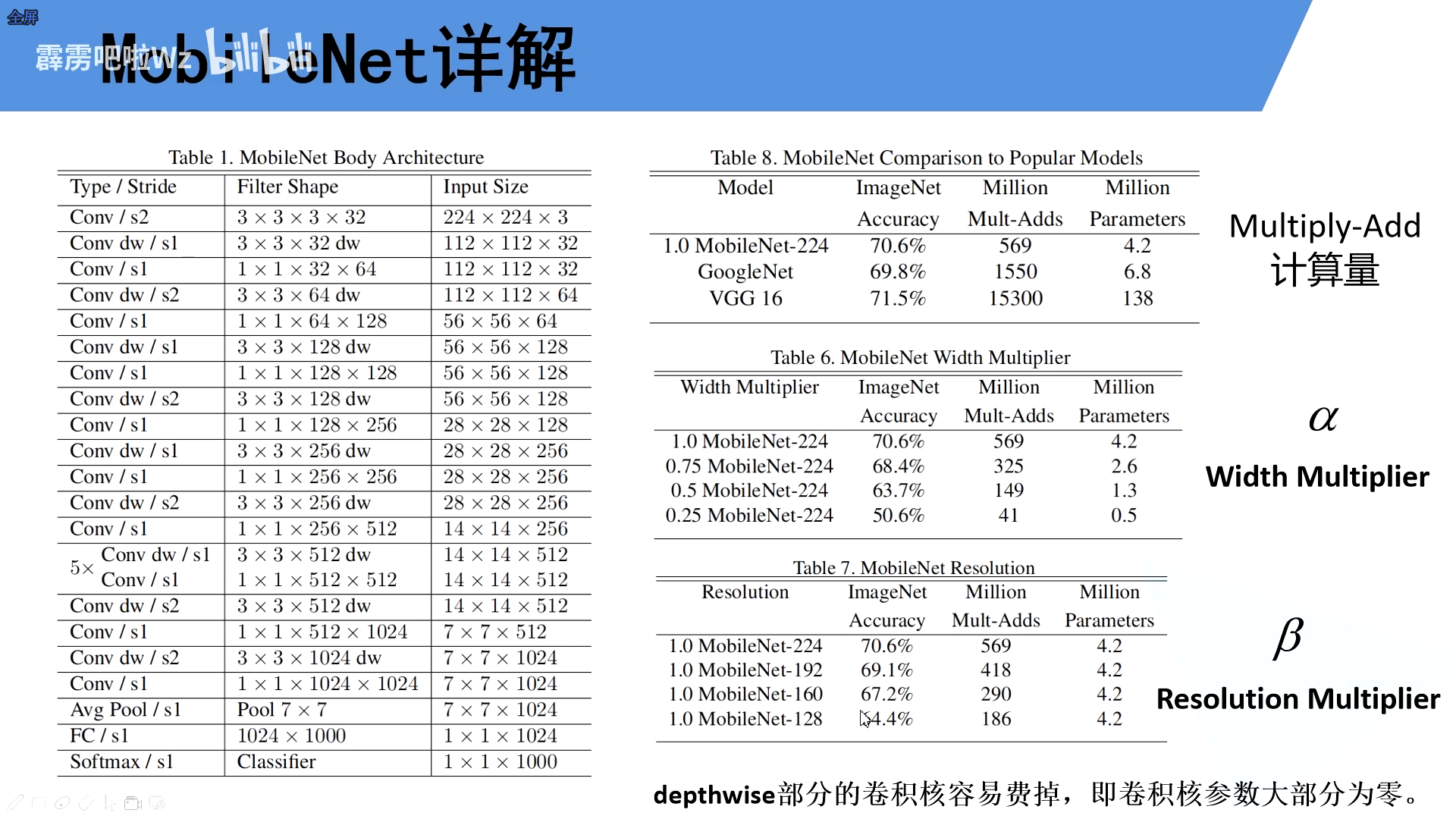
α:卷积核个数的倍率
β:输入照片的尺度
但是depthwise部分的卷积核容易费掉,即卷积核参数大部分为零。由此提出了MobileNetV2版本

特点
2.1Inverted Residuals(倒残差结构)
2.2Linear Bottlenecks
2.1Inverted Residuals(倒残差结构)
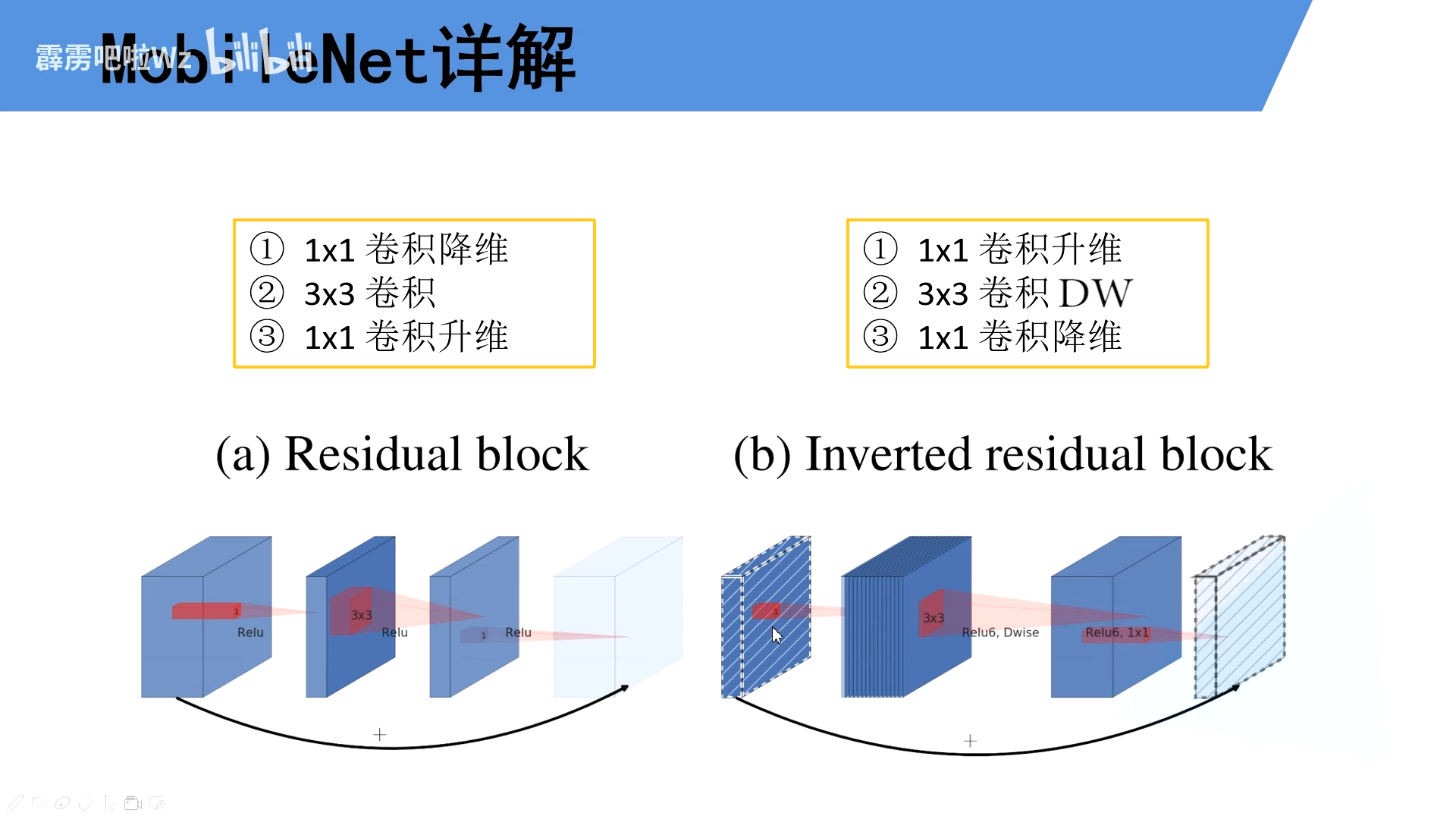
倒残差结构使用的将低维数据转化为高维数据,这样在使用Relu6函数的时候信息损失的就不多了,最后输出为低维数据的时候,又需要使用线性激活函数
2.2Relu6激活函数
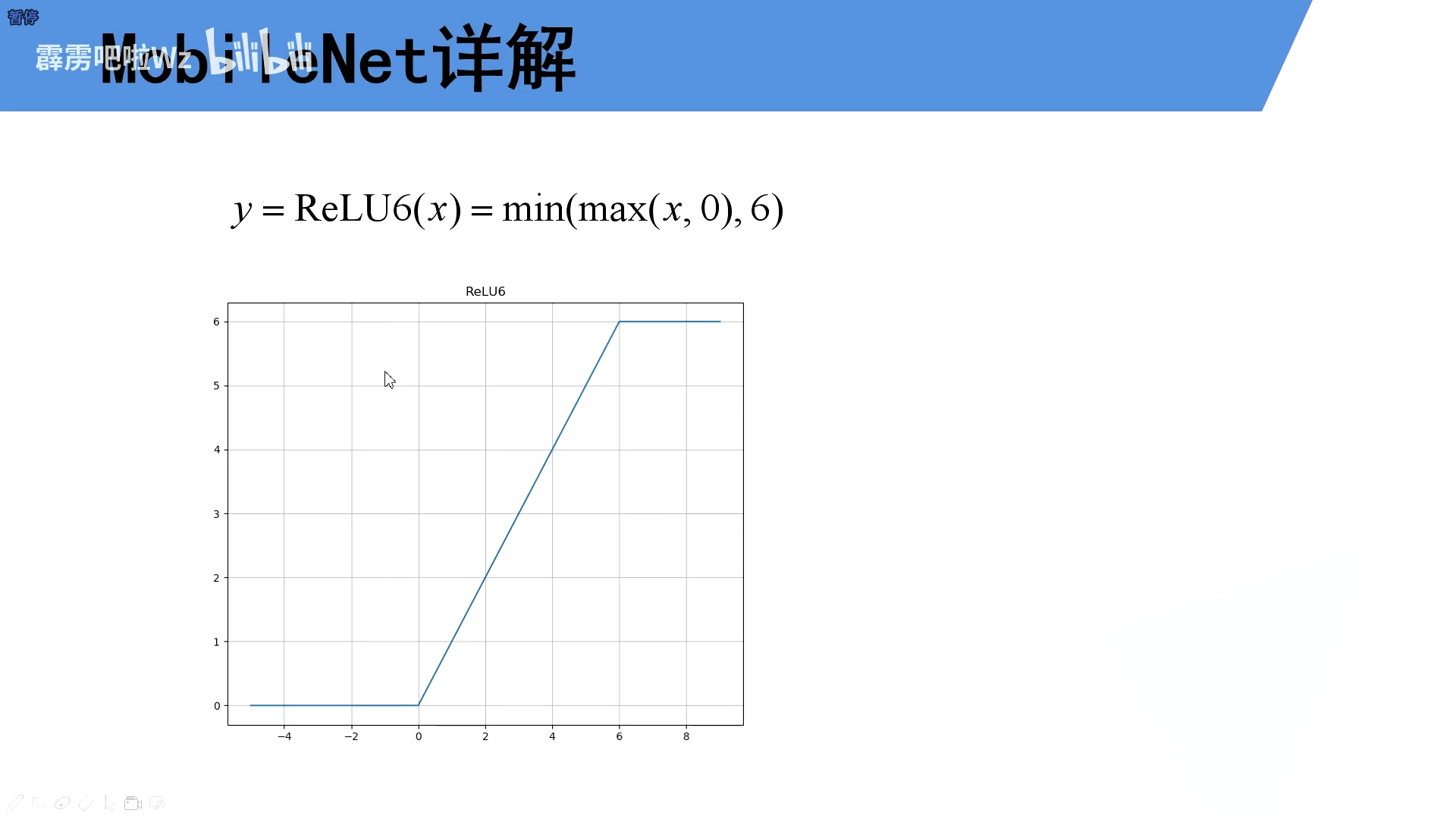
ReLU激活函数对低维特征信息照成大量损失

2.3倒残差结构图

2.4MobileNetv2结构图

首先经过一个卷积层,再连续经过多个倒残差结构(n是个数),1个1x1卷积层,一个平均池化下采样层,一个1x1的卷积层
训练效果

代码说明
结合这两个结构图
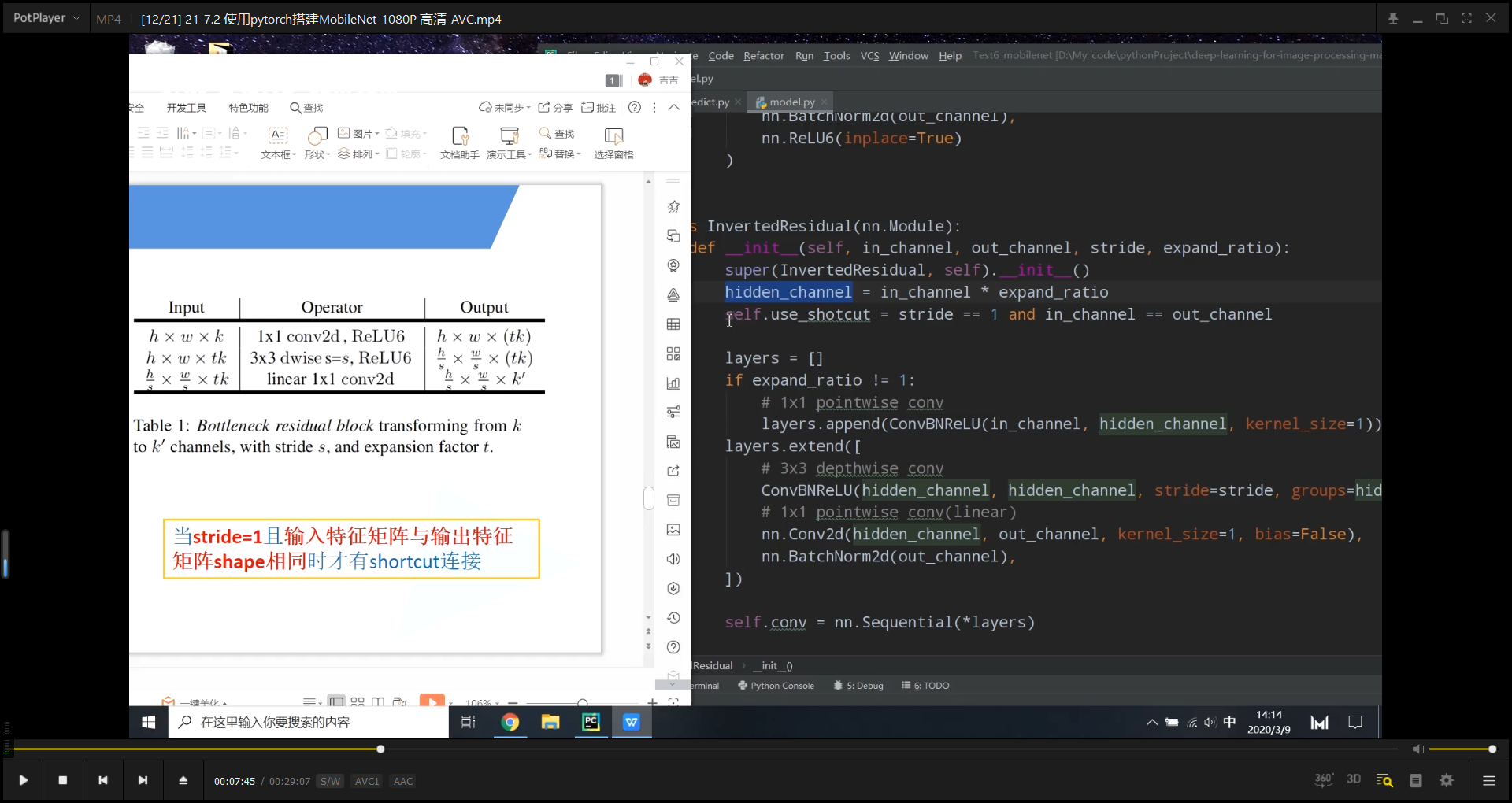
理解代码
MObileNetV3
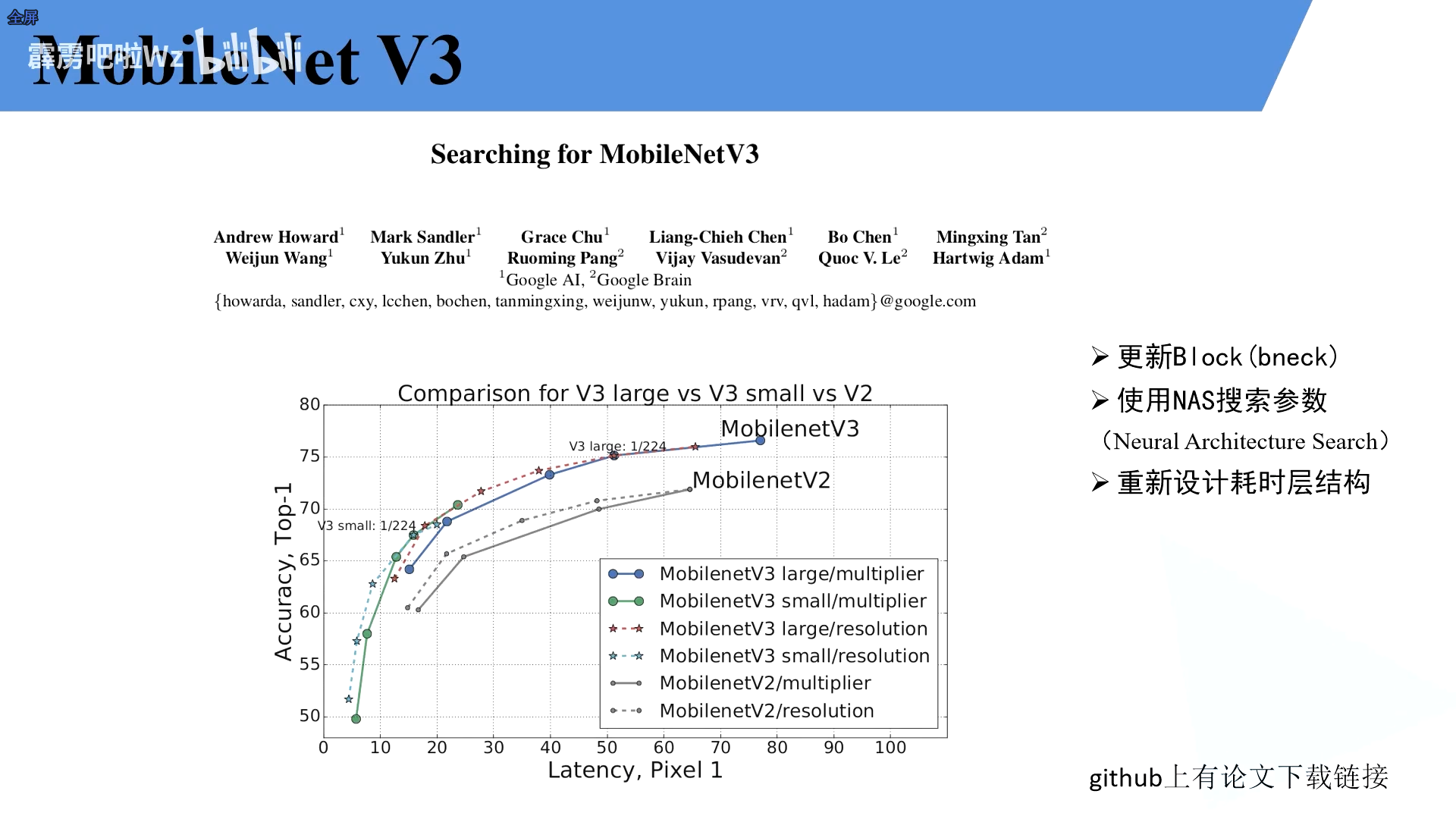
- 更新Block(bneck)
- 使用NAS搜索参数(Neural Architecture Search
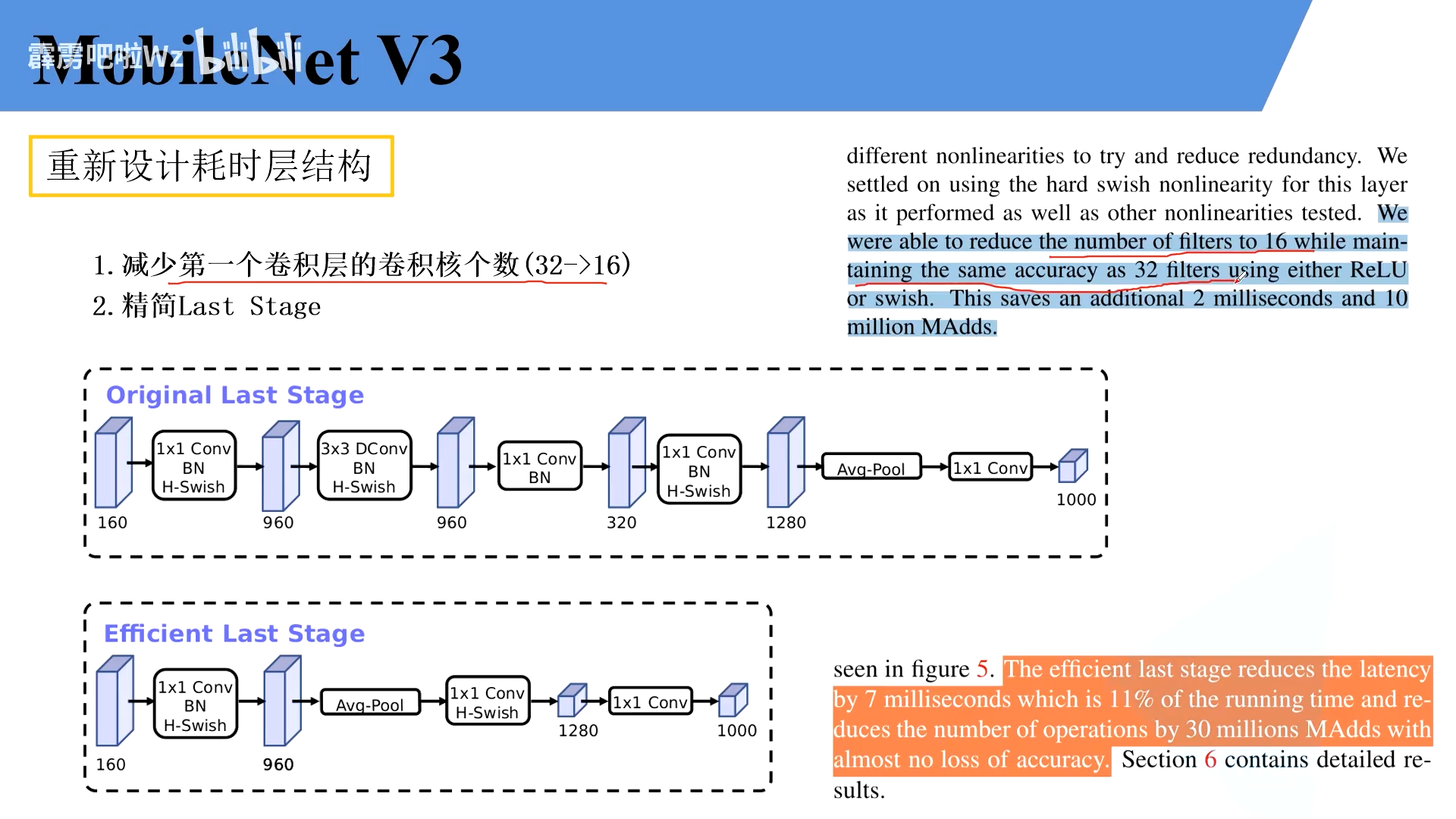
- 重新设计耗时层结构
相比v2速度更快
1.Block
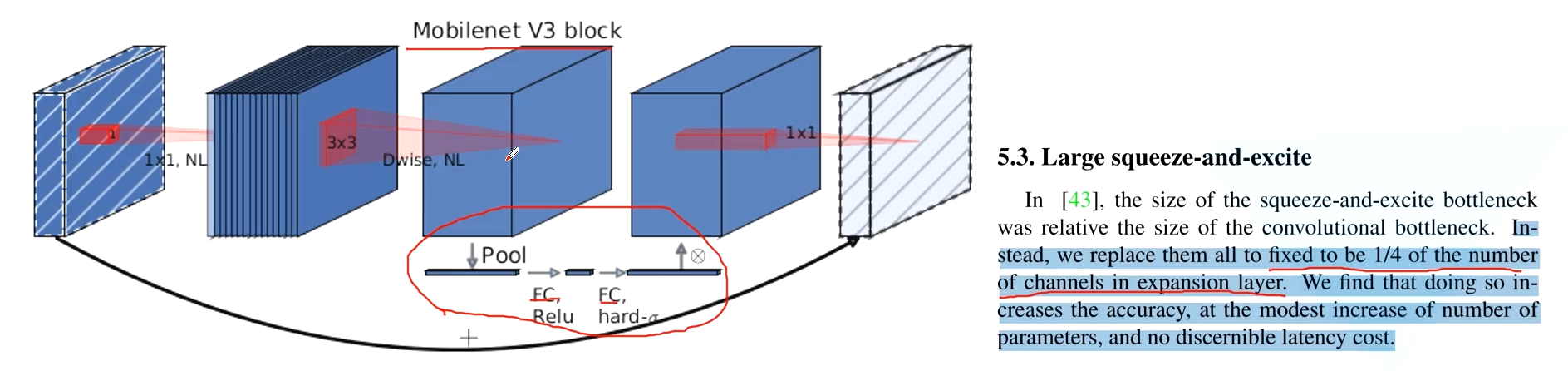
- 加入SE机制
- 更新了激活函数
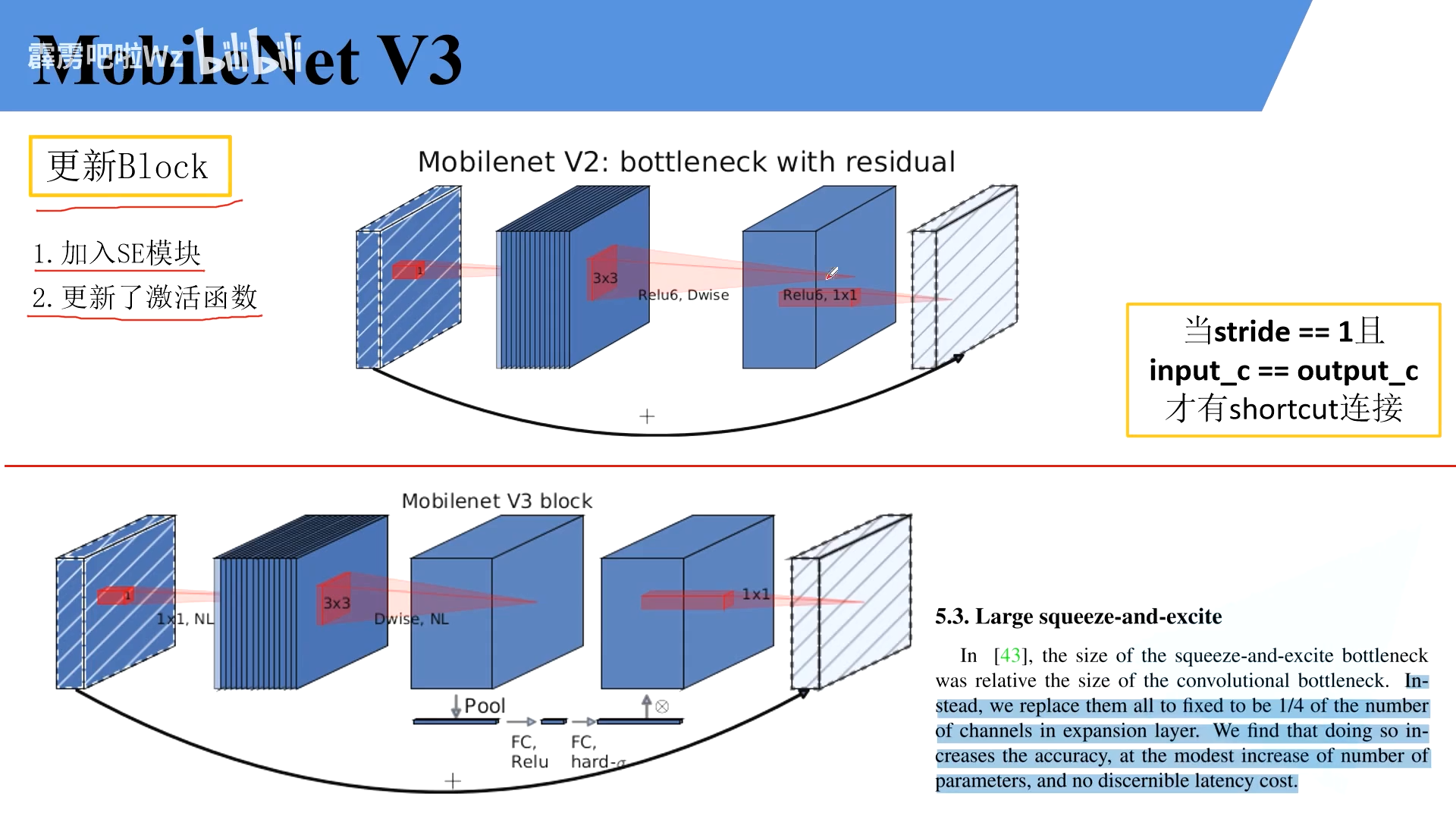
相比V21模型,就是再中间加入了SE模块
DW卷积核PW卷积

SE通道注意力
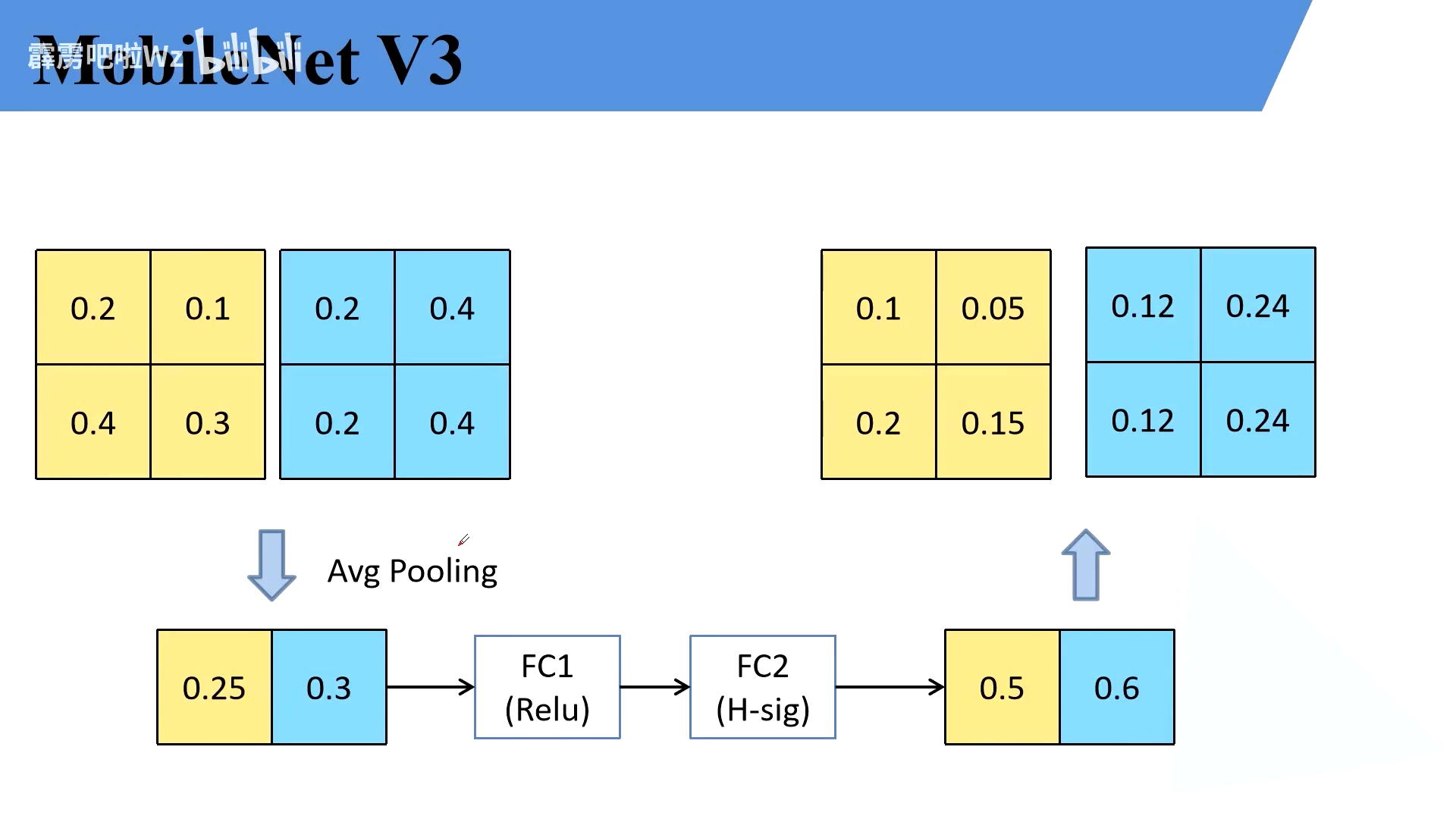
SE主要是找出了feature map参数的权重,以便更好地调整参数
关键在于最中间的池化,接FC1,FC2,最后又输出权重矩阵,分别和原特征矩阵相乘进行了更新
FC1的个数为平均池化后channel的四分之一
FC2的个数为原来的channel的个数,使用的是hard-sodmig
2.重新设计耗时层结构
重新设计激活函数
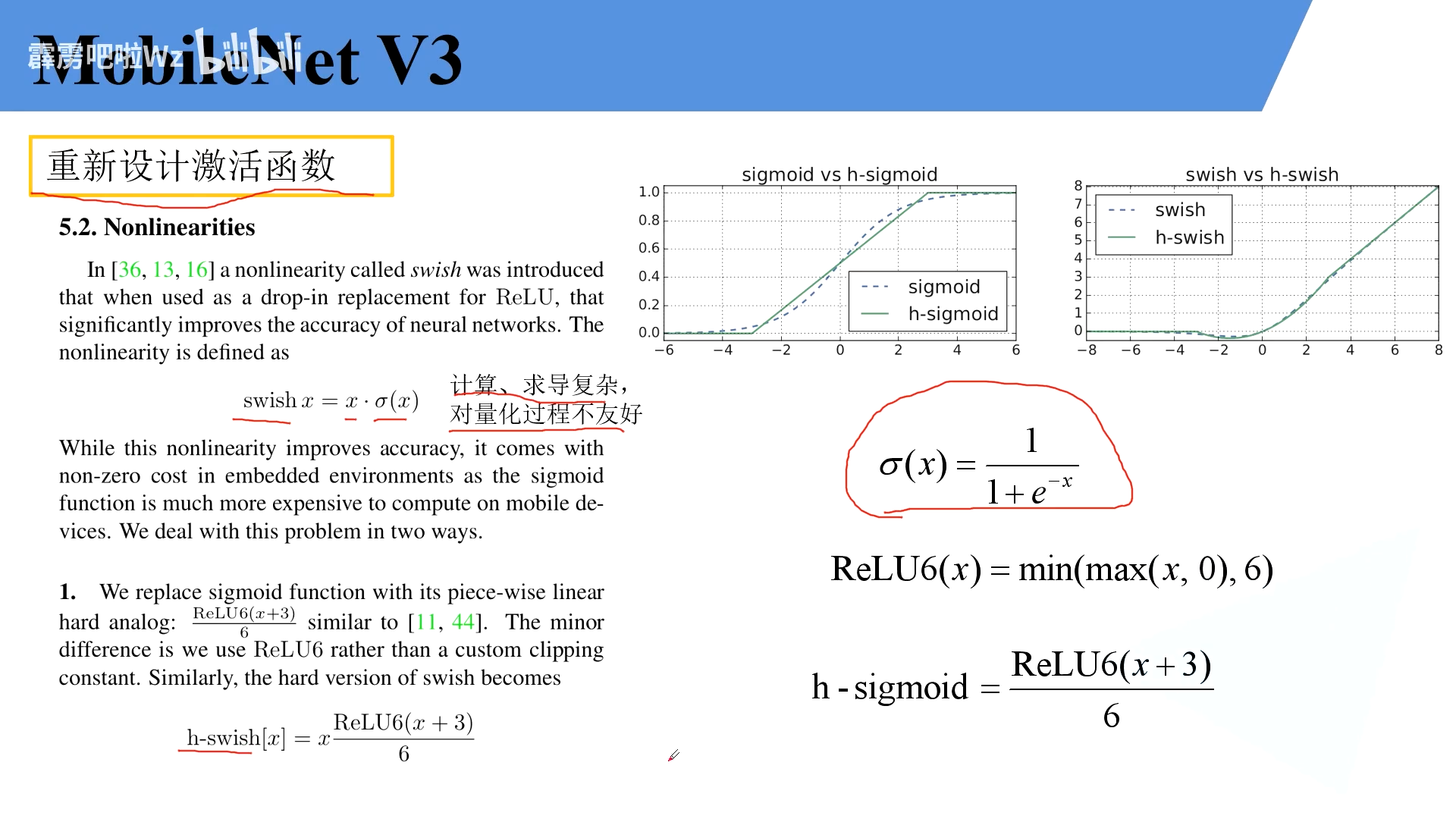
swish激活函数
因为其缺点所以作者使用了H-swish函数,将simog函数替换为Relu函数
3.mobileNet-large
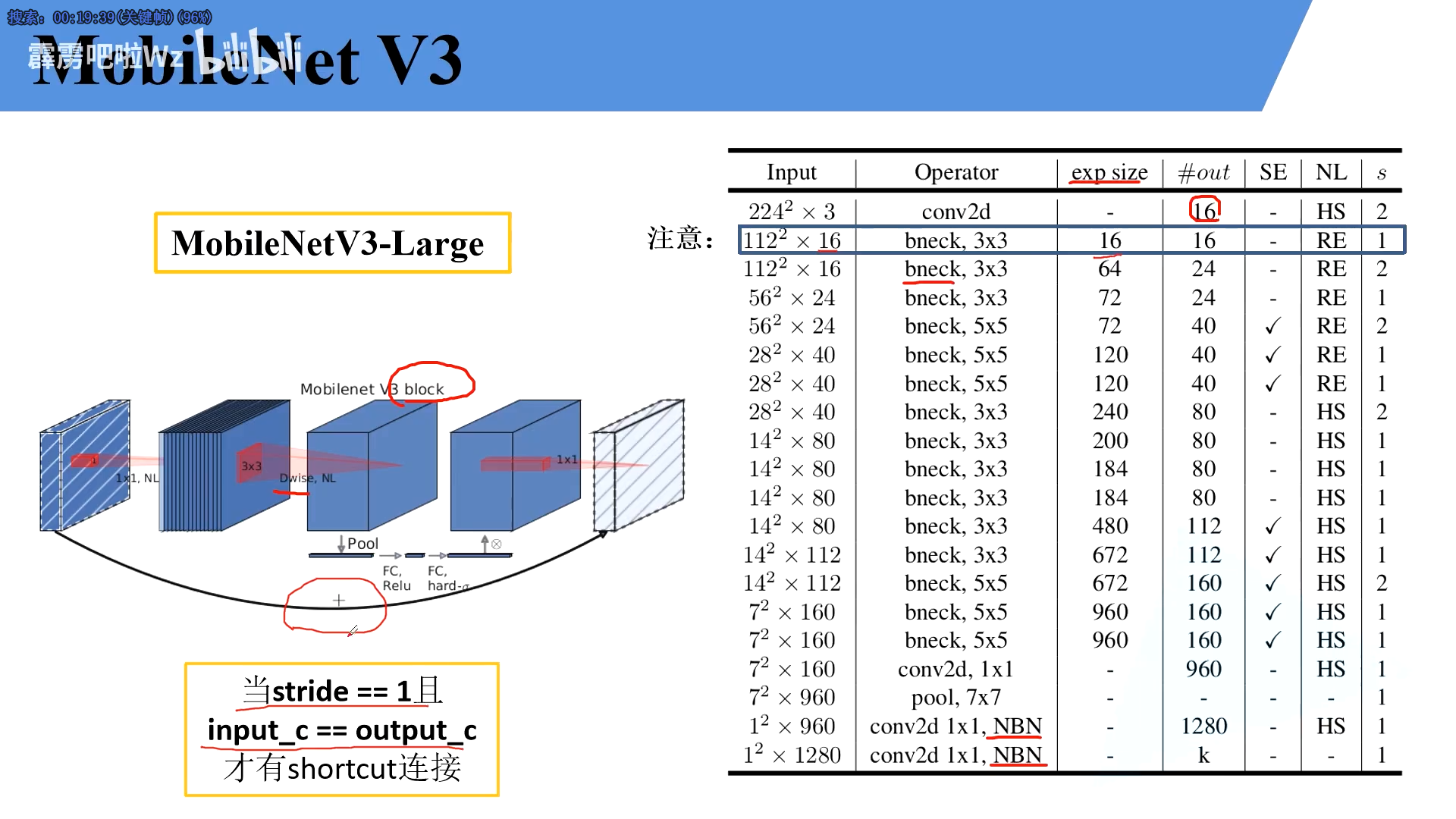
注意第一个 bleck并没有真实升维,所以在实现中并没有这个步骤
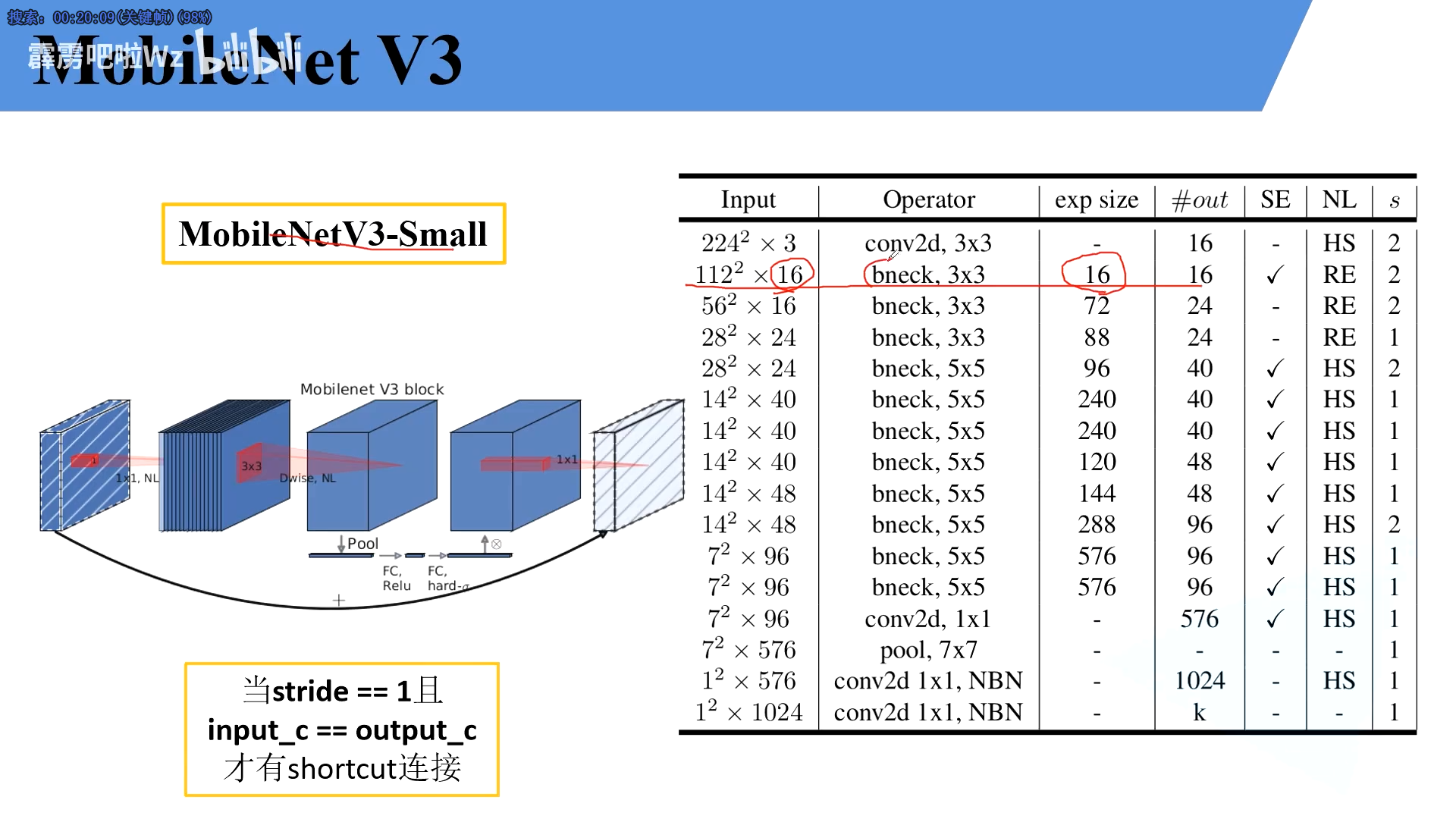
MobileNet-small
4.代码解读
1._make_divisible:
2.ConvBNActivation:
3.SqueezeExcitation:
4.InvertedResidualConfig
5.InvertedResidual
各个代码各司其职,共同组成了最后的代码,很厉害!
















 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











