







 本文详细介绍了四个Spark基础案例,包括词频统计、平均年龄计算、身高信息统计和词频统计2,涵盖Scala编程,数据处理和结果展示,帮助读者深入理解Spark处理大数据的应用。
本文详细介绍了四个Spark基础案例,包括词频统计、平均年龄计算、身高信息统计和词频统计2,涵盖Scala编程,数据处理和结果展示,帮助读者深入理解Spark处理大数据的应用。
总结了四个基础的spark案例,可以对使用 Scala 编写 Spark 应用程序处理大数据有较为深入的了解。
(一)词频统计
案例描述
提起 Word Count(词频数统计),相信大家都不陌生,就是统计一个或者多个文件中单词出现的次数。
案例分析
将文件转换成RDD,然后用flatMap将单词以空格符分开,然后用map将单个单词转换成key-value对,最后使用reduceByKey将相同单词累加。
编程实现
spark源码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* Created by sys on 2016/11/22.
*/
object SparkWordCount {
def FILE_NAME:String = "word_count_results_";
def main(args: Array[String]){
if (args.length < 1){
println("Usage:SparkWordCount File name");
System.exit(1);
}
val conf = new SparkConf().setAppName("Spark Exercise: Spark Version Word Count Program");
val sc = new SparkContext(conf);
val textFile = sc.textFile(args(0));
val wordCounts = textFile.flatMap(line => line.split(" ")).map(
word => (word,1)).reduceByKey((a,b)=> a+b)
wordCounts.collect().foreach(e => {
val (k,v) = e
println(k+"="+v)
});
wordCounts.saveAsTextFile(FILE_NAME+System.currentTimeMillis());
println("Word Count program running results are successfully saved.");
}
}
随便找一篇英文文章上传到HDFS,然后将spark程序提交到集群上执行
[root@Master bin]# ./spark-submit --class SparkWordCount --executor-memory 512M /home/spark-exercise/spark-exercise.jar hdfs://master.hadoop:9000/usr/word_count/test.txt执行结果

(二)统计平均年龄
案例描述
我们将假设我们需要统计一个 1000 万人口的所有人的平均年龄。假设这些年龄信息都存储在一个文件里,并且该文件的格式如下,第一列是 ID,第二列是年龄。
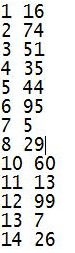
我们需要用 Scala 写一个生成 1000 万人口年龄数据的文件,源程序如下:
package CreatData
import java.io.{File, FileWriter}
import scala.util.Random
/**
* Created by sys on 2016/11/22.
*/
object averageAge {
def main(args: Array[String]): Unit  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









