







目录
前言
总是写后端也没意思,突发奇想,来学学爬虫。最终目标是利用Scrapy以及Django来搭建一个简单的爬虫框架,并完成一个简单的爬取任务:将目标网页的部分内容爬取下来存入Mysql数据库中。
本文记录了一个简单的爬虫框架的完整搭建步骤,适合想要快速上手的朋友。如果想系统地学习Scrapy以及Django,请前往以下列出的官方文档:
正文
环境配置
- 安装python开发环境(强烈推荐直接安装Anaconda(我目前安装的是Anaconda2-4.1.1-Windows-x86_64)
- 安装scrapy(命令行运行“conda install scrapy”)
- 安装django(命令行运行“conda install django”)
- 安装scrapyd(目前Anaconda好像还找不到这个module,直接用pip装:命令行运行“pip install scrapyd”)
- 其他还有两三个依赖的库(如scrapy_djangoitem 、MySQL-python),具体记不全了,在运行scrapy或django报错时,用pip装一下就好了
只用Scrapy完成任务
如果你只是想快速写一个简单的爬虫程序,那么没有必要搭建任何框架,只用scrapy就可以搞定了,就如下面的程序这样。(该段代码来自Scrapy官网)
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.xpath('span/small/text()').extract_first(),
}
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)将上述代码保存为quotes_spider.py,并运行命令:
scrapy runspider quotes_spider.py -o quotes.json爬取的内容输出到quotes.json文件中。
可以看到,用scrapy写一个爬虫非常简单,只要继承scrapy.Spider并实现parse函数就好了。
然而,这里的输出是放在文件中的,我们的任务目标是将输出存入mysql中,因此我们需要借助其他的库,web框架Django就是一个很好的选择。
Django自带Sqlite,也支持mysql、sqlserver等多种数据库。
简单的Django项目
在将Django与Scrapy结合之前,先简单了解一下Django的项目结构。
运行如下命令创建一个Django项目:
django-admin startproject helloscrapy可以看到此项目的文件结构:
helloscrapy/
manage.py
helloscrapy/
__init__.py
settings.py
urls.py
wsgi.py此时,你在最顶层的helloscrapy目录下运行以下命令:
python manage.py runserver用浏览器打开http://127.0.0.1:8000/就能够看到一个显示“Congratulations on your first Django-powered page.”的页面,这表示你的Django开发环境配置正确。
当然,我们的目的不是开发网站,只是利用Django来对数据库进行操作,因此,在这里我们只要熟悉Django项目文件组成即可,
(每个文件的作用在Django官方文档都有详细解释,这里不做赘述)。
连接mysql数据库
Django默认使用sqlite,因此,在编写具体的数据类之前,我们需要先配置好Django与mysql的连接。这个配置是写在里层的helloscrapy目录下的settings.py中(将其中的ip、user等信息改为自己的):
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'database_name',
'USER': 'user',
'PASSWORD': 'password',
'HOST': 'database_server_ip',
'PORT': '3306',
}
}配置好后,在项目根目录下运行以下命令:
python manage.py makemigrations
python manage.py migrate在这个过程中若遇到缺少模组的错误,请用pip install安装缺少的模组。命令成功运行后,打开你的数据库,若看到有一些auth和django开头的表建立,则说明mysql数据库连接成功。
编写一个数据类
在根目录下运行以下命令来新建一个Django app:
python manage.py startapp warehouse我们可以看到生成的warehouse的目录结构:
warehouse/
__init__.py
admin.py
apps.py
migrations/
__init__.py
models.py
tests.py
views.py接着在里层的helloscrapy目录下的settings.py中的INSTALLED_APPS中加入’warehouse’, 如下所示:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'warehouse',
]我们将把warehouse当做数据类的仓库,爬虫爬取的数据将会进行一定处理而转换为warehouse中定义的数据类(model),并存入数据库中。
接下来,在models.py中编写一个简单的model:
from django.db import models
class TestScrapy(models.Model):
text= models.CharField(max_length=255)
author= models.CharField(max_length=255)
class Meta:
app_label = 'warehouse'
db_table = 'test_scrapy'同样地,在项目根目录下运行以下命令:
python manage.py makemigrations
python manage.py migrate查看数据库中,应该能够看到刚刚建好的test_scrapy表。
加入Scrapy
现在就可以将Scrapy加入到Django项目中了。
首先,配置环境变量PYTHONPATH,设置其值为此Django的项目根目录的路径(例如E:\PythonProjects\helloscrapy)
接下来,项目根目录下新建一个bots文件夹,进入bots目录,新建一个init.py文件,内容如下:
def setup_django_env():
import os, django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "helloscrapy.settings")
django.setup()
def check_db_connection():
from django.db import connection
if connection.connection:
#NOTE: (zacky, 2016.MAR.21st) IF CONNECTION IS CLOSED BY BACKEND, CLOSE IT AT DJANGO, WHICH WILL BE SETUP AFTERWARDS.
if not connection.is_usable():
connection.close()
在bots目录下运行以下命令来新建一个scrapy项目:
scrapy startproject testbottestbot项目结构如下:
testbot/
__init__.py
scrapy.cfg
testbot/
__init__.py
items.py
pipelines.py
settings.py
spiders/ 编写items
items文件:
import scrapy
from scrapy_djangoitem import DjangoItem
from warehouse.models import TestScrapy
class TestbotItem(DjangoItem):
django_model = TestScrapy编写spiders
在spiders目录下新建一个test_spider.py,内容如下:
import scrapy
from testbot.items import TestbotItem
class TestSpider(scrapy.Spider):
name = "test_spider"
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
item = TestbotItem()
item['text'] = quote.css('span.text::text').extract_first()
item['author'] = quote.xpath('span/small/text()').extract_first()
yield item
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)编写pipelines
class TestbotPipeline(object):
def process_item(self, item, spider):
item.save()
return item爬虫设置
testbot下的settings.py:
from bots import setup_django_env
setup_django_env()
BOT_NAME = 'testbot'
SPIDER_MODULES = ['testbot.spiders']
NEWSPIDER_MODULE = 'testbot.spiders'
DOWNLOAD_HANDLERS = {'s3': None}
DOWNLOAD_DELAY = 0.5
DOWNLOAD_TIMEOUT = 100
CONCURRENT_REQUESTS_PER_IP=1
ITEM_PIPELINES = {
'testbot.pipelines.TestbotPipeline': 1,
}ok, 到这里,一个简单的Scrapy算是完成了,接下来就是部署和启动,这里我们使用scrapyd-client来部署爬虫到scrapyd上
部署和运行爬虫
启动scrapyd
运行下面的命令:
scrapyd打开 http://localhost:6800/ 应该能够看到scrapyd的页面
部署爬虫到scrapyd
将testbot目录下的scrapy.cfg中url前的的“#”删除:
url = http://localhost:6800/在testbot目录下运行部署命令以及:
scrapyd-deploy
curl http://localhost:6800/schedule.json -d project=testbot -d spider=test_spider在 http://localhost:6800/ 查看爬虫运行状态。
运行结果
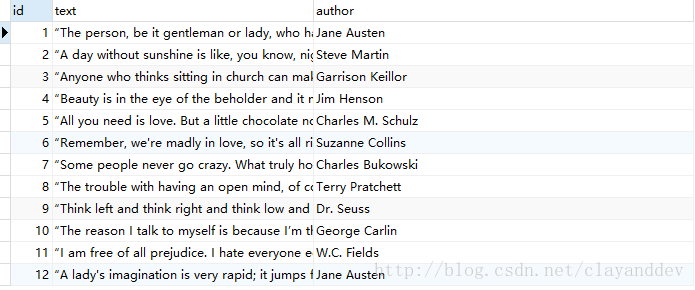
如果爬虫运行结束,你应该能够在数据库中的test_scrapy表中看到结果,如下图所示:
项目地址
https://github.com/clayandgithub/helloscrapy
后记
无

















 1878
1878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









