







 本文介绍如何使用Django创建一个爬虫项目,从百度百科抓取链接关键词及其简介和URL。通过分析网页结构,借助BeautifulSoup库,将数据存储到SQLite3数据库。在Django中配置数据库设置,处理特殊情况,如不存在的摘要,以及URL编码问题。同时,展示了models.py中的数据库模型创建,以及使用makemigrations和migrate命令同步到数据库。最后,讨论了views.py和home.html中如何利用Bootstrap进行页面渲染。
本文介绍如何使用Django创建一个爬虫项目,从百度百科抓取链接关键词及其简介和URL。通过分析网页结构,借助BeautifulSoup库,将数据存储到SQLite3数据库。在Django中配置数据库设置,处理特殊情况,如不存在的摘要,以及URL编码问题。同时,展示了models.py中的数据库模型创建,以及使用makemigrations和migrate命令同步到数据库。最后,讨论了views.py和home.html中如何利用Bootstrap进行页面渲染。
整个Django project要实现的目的,是在Python 百度百科这个网页中将所有的链接关键词抓取下来,并将它们的简介、网址通过一个网页显示出来。
首先,我们先上到这个网站,使用F12 开发者工具查看网页元素,并结合网页源代码,可以发现百度百科网页组成的规律,如
整个文字简介在这个层 class=”lemma-summary”
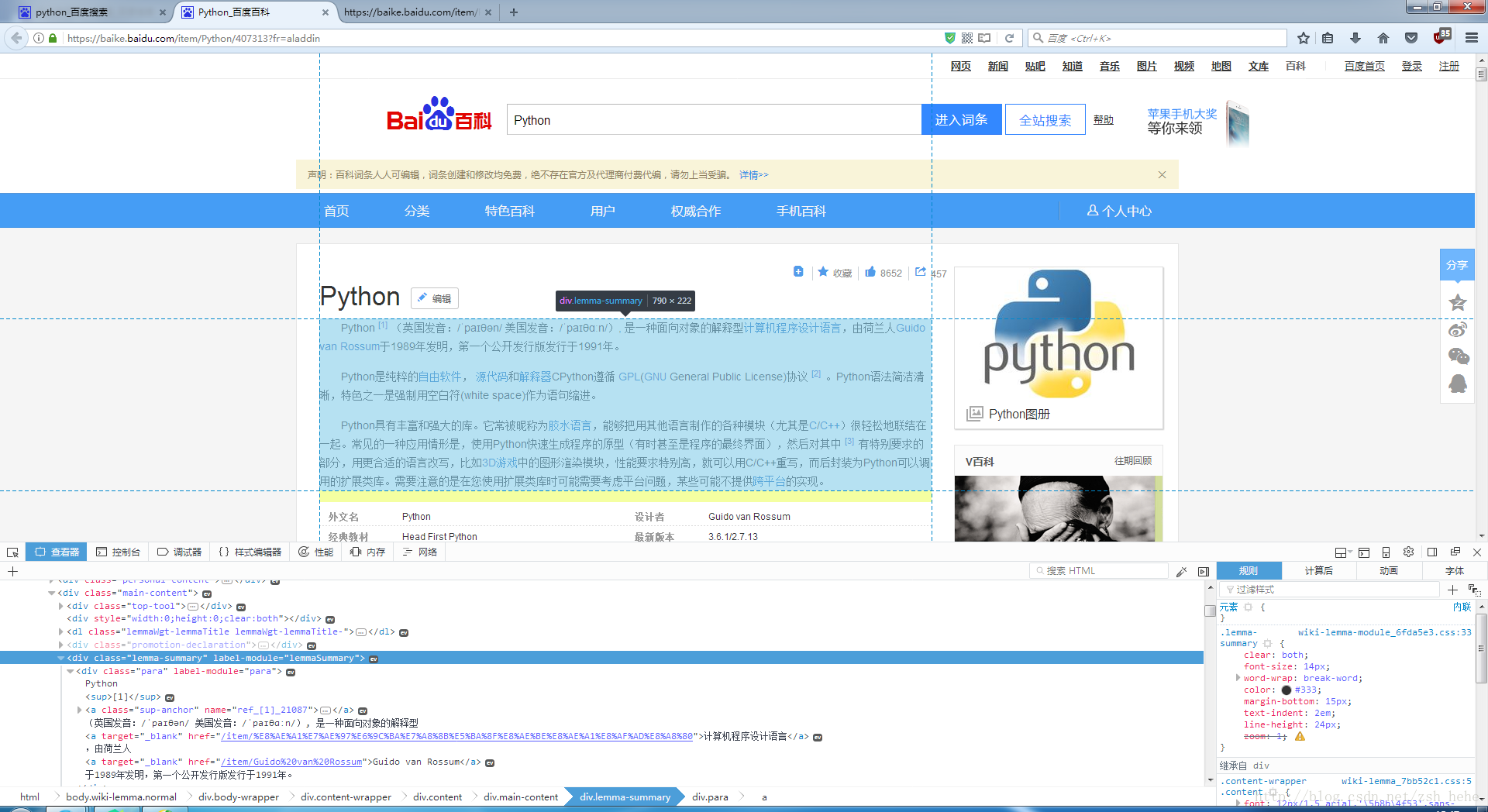
链接关键词前有target=_blank href=”/item/

以及url组成,都是https://baike.baidu.com/item/ + 关键词, 如https://baike.baidu.com/item/Python
根据这些规律,我们再借助BeautifulSoup中的一些筛选例子,就可以完成整个爬虫,并把数据导入到splite3型数据库中:
spider.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
# import data into mysql(sqlite3), must have these four lines defination:
import os
# 我所创建的project名称为learn_spider;里面的app名称为website
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "learn_spider.settings")
import django
django.setup()
# urllib2 package: open resource by URL; re package: use regular expression to filter the objects
import urllib2, re
# BeautifulSoup: abstract data clearly from html/xml files
from bs4 import BeautifulSoup
# import tables from models.py
from website.models import Website
# urlopen()方法需要加read()才可视源代码,其中decode("utf-8")表示以utf-8编码解析原网页,这个编码格式是根据网页源代码中<head>标签下的<meta charset="utf-8">来决定的。
html_python = urllib2.urlopen('https://baike.baidu.com/item/Python').read().decode("utf-8")
soup_python = BeautifulSoup(html_python, "html.parser")
# print soup
#这里用到了正则表达式进行筛选
item_list = soup_python.find_all('a', href=re.compile("item"))
for each in item_list:
print each.string
# use quote to replace special characters in string(escape encode method)
urls = "https://baike.baidu.com/item/" + urllib2.quote(each.string.encode("utf-8"))
print urls
html = urllib2.urlopen(urls).read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
if soup.find('div', 'lemma-summary') == None:
text =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









