







字符串
字符串是一类基本且重要的数据类型,细节太多了说不完。
链表
链表基础功能的实现代码都在这,不过多详述
Node.h
struct node{
int data;
node* next;
};
node *CreateList(int arr[], int n);
void ShowList(node* head);
node *Find(node* head, int a);
node *FindLast(node* head);
void Insert_before(node* head, int a, int e);
void Insert_after(node* head, int a, int e);
node *Delete(node* head, int a);
node *DeleteAll(node* head, int a);
//题目:给定两个链表A和B,每个链表里面都不存在重复
// 元素,函数ListUnion(A, B)求A,B两个链表元素的并集,
//并将结果存入链表A中,即对B中的每个结点,若该结点在
// A中不存在,则将该元素加到链表A末尾,并返回新的链
// 表首节点,请实现该函数。
//例如链表A = 2->3->5->7->8,链表B = 1->9->3->6->8,
//则执行该函数后,A = 2->3->5->7->8->1->9->6。
//提示:先找到链表A的末尾节点。
bool IsIn(node* head, int a);
node* ListUnion(node* A, node* B);
node* ListCommon(node* A, node* B);
node* ListUnionAnswer(node* A, node* B);
node* DeletePrime(node* head);
node* Insert_Sort(node* head, node* tmp);
int Len(node *head);
void Extract(node *head, int n, int arr[]);
void Sort(int arr[], int n);
Node.cpp
node *CreateList(int arr[], int n){
node* head = NULL;
node* tail = NULL;
for (int i=0; i<n; i++){
//创建节点
node* tmp = new node;
tmp->data = arr[i];
tmp->next = NULL;
if (head == NULL){
head = tmp;
tail = tmp;
}
else{
tail->next = tmp;
tail = tmp;
}
}
return head;
}
void ShowList(node* head){
for (node* pi = head; pi != NULL; pi = pi->next){
if (pi->next == NULL) printf("%d\n", pi->data);
else printf("%d ->", pi->data);
}
}
node *Find(node* head, int a){
for (node* pi = head; pi != NULL; pi= pi->next){
if (pi->data == a) return pi;
}
return NULL;
}
node *FindLast(node *head) {
for (node* pi = head; pi != NULL; pi= pi->next){
if (pi->next == NULL) return pi;
}
}
void Insert_before(node* head, int a, int e){
node *nodeE = new node;
nodeE->data = e;
nodeE->next = NULL;
for (node* pi = head; pi != NULL; pi= pi->next){
if (pi->next->data == a){
nodeE->next = pi->next;
pi->next = nodeE;
break;
}
}
}
void Insert_after(node* head, int a, int e){
node *nodeE = new node;
nodeE->data = e;
nodeE->next = NULL;
for (node* pi = head; pi != NULL; pi= pi->next){
if (pi->data == a){
nodeE->next = pi->next;
pi->next = nodeE;
break;
}
}
}
node* Delete(node* head, int a){
while(head->data == a) head = head->next;
for (node* pi = head; pi != NULL; pi= pi->next){
if (pi->next == NULL) continue;
if (pi->next->data == a){
pi->next = pi->next->next;
// pi->next = nodeE;
break;
}
}
return head;
}
node *DeleteAll(node* head, int a){
while (Find(head, a) != NULL){
head = Delete(head, a);
}
return head;
}
node* ListUnion(node* A, node* B){
node *tail = FindLast(A);
for (node *pi= B; pi != NULL; pi = pi->next){
if (!IsIn(A,pi->data) ) {
Insert_after(A, tail->data,pi->data);
tail = FindLast(A);
}
}
return A;
}
node *ListCommon(node *A, node *B) {
for (node *pi=B; pi != NULL; pi = pi->next){
if (!IsIn(A, pi->data)){
B = Delete(B, pi->data);
}
}
return B;
}
bool IsIn(node *head, int a) {
bool flag = false;
for (node *pi= head; pi != NULL; pi = pi->next){
if (pi->data == a){
flag = true;
break;
}
}
return flag;
}
node* ListUnionAnswer(node* A, node* B){
node *head = A, *tail = A;
if (tail != NULL) // A非空 //寻找尾节点
{
while (tail->next != NULL)
tail = tail->next;
}
for (node* tmp = B; tmp != NULL; tmp = tmp->next)
{
node* pa;
for (pa = A; pa != NULL; pa = pa->next) // 判断B中每个tmp 是否在A中
{
if (pa->data == tmp->data)
break;
}
if (pa == NULL) //不存在,添加
{
node* nd = new node;
nd->data = tmp->data;
nd->next = NULL;
if (tail == NULL)
head = tail = nd;
else
{
tail->next = nd;
tail = nd;
}
}
}
return head;
}
bool IsPrime(int n) {
if (n==1) return false;
bool flag = true;
for (int i=2; i<n; i++){
if (n%i == 0) {
flag = false;
break;
}
}
return flag;
}
node *DeletePrime(node *head) {
for (node *pi= head; pi != NULL; pi = pi->next){
if (IsPrime(pi->data)){
head = Delete(head, pi->data);
}
}
return head;
}
node *Insert_Sort(node *head, node *tmp) {
int n = Len(head);
int arr[n];
Extract(head, n, arr);
Sort(arr, n);
node* C = CreateList(arr, n);
for (node* pi=C; pi != NULL; pi = pi->next){
if (tmp->data < pi->data ){
Insert_before(C, pi->data, tmp->data);
break;
}
}
return C;
}
int Len(node *head) {
int count = 0;
for (node* pi=head; pi != NULL; pi = pi->next){
count++;
}
return count;
}
void Extract(node *head, int n, int arr[]) {
// int n = Len(head);
// int arr[n];
int i = 0;
for (node* pi=head; pi != NULL; pi = pi->next){
arr[i++] = pi->data;
}
// return arr;
}
void Sort(int *arr, int n) {
for (int i=0; i< n; i++){
int min = arr[i];
for (int j=i; j< n; j++){
if (arr[j] < min){
min = arr[j];
int tmp = arr[j];
arr[j] = arr[i];
arr[i] = tmp;
}
}
}
}
main.cpp
int main() {
int n;
cin >> n;
int A[n];
for (int i=0; i<n; i++){
cin >> A[i];
}
node* nodeA = CreateList(A, n);
int m;
cin >> m;
int B[m];
for (int i=0; i<m; i++){
cin >> B[i];
}
node* nodeB = CreateList(B, m);
ShowList(nodeA);
ShowList(nodeB);
// node *tmp = new node;
// tmp->data = 8;
// tmp->next = NULL;
// node* C = Insert_Sort(nodeA, tmp);
node* C = ListCommon(nodeA, nodeB);
ShowList(C);
return 0;
}
字符串的链表实现
假设x和y是两个由单链表组成的字符串(其中每个结点只存储一个字符)
请编写一个算法,找出x中第一个不在y中出现的字符。
一、 基础功能要求实现
结点定义即部分操作的函数声明
struct node{
char x; //结点存储一个字符
node* next;
};
void InitCMyString(node* &head_s, char* s);//初始化链表字符串
void PrintLink(node *head); //打印链表字符串
node* FristNotIn(node* s_y, node* s_x);//找出x中第一个不在y中出现的字符
初始化链表字符串
void InitCMyString(node* &head_s, char* s){
//初始化链表字符串
node *head = NULL, *rear = NULL;
for(; *s; s++) {
node *tmp = new node;
tmp->x = *s;
tmp->next = NULL;
if (rear == NULL) {
head = rear = tmp;
}
else{
rear->next = tmp;
rear = tmp;
}
}
head_s = head;
}
打印链表字符串
void PrintLink(node *head){
for (node *pi = head; pi != NULL; pi=pi->next){
// printf("%s -> ",pi->x);
cout<<pi->x<< "->";
}
cout << "\n";
}
算法-找出x中第一个不在y中出现的字符 的具体实现
node* FristNotIn(node* s_y, node* s_x){
for (node * pi=s_x; pi != NULL; pi=pi->next){ //目标字符串中每个字符
node *pj;
for (pj=s_y; pj != NULL; pj=pj->next){ //在文本中遍历
if (pi->x == pj->x ){
break;
}
}
if (pj == NULL) return pi; //文本遍历结束
}
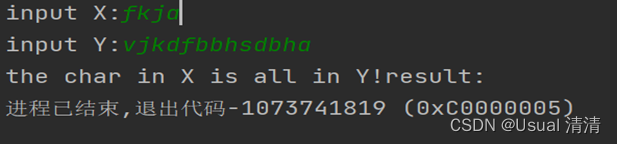
cout << "the char in X is all in Y!";
return NULL;
}
main
int main(){
char sx[30], sy[3000];
cout << "input X:"; cin>>sx;
cout << "input Y:"; cin>>sy;
node *s_x, *s_y, *sm_y;
InitCMyString(s_x, Simplify(sx)); PrintLink(s_x);
InitCMyString(s_y, Simplify(sy)); PrintLink(s_y);
node* sub = FristNotIn(s_y, s_x);
cout <<"result: "<< sub->x;
return 0;
}
//测试用例:
// sx sy
// abc dafgc
// fkja vjkdfbbhsdbha
运行结果:

二、优化改进:
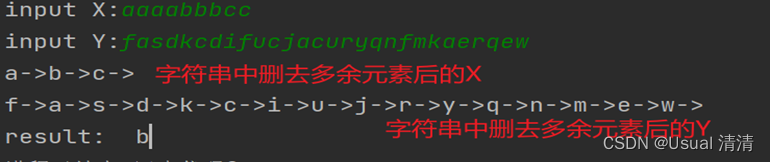
链表中每个元素只能通过头结点逐个访问,所以对链表这种逻辑结构的查找用挨个查找是比较好的方法,因此可以通过缩减原文本X和Y,删除重复的字符以减少遍历次数来达到优化算法
char* Simplify(char *src){
//对字符串src进行化简并返回结果
char *re;
int n = 0;
for(int i=0;i<strlen(src);++i){
int k;
for(k=0;k<i;++k){//注意k<i
if(src[i]==re[k]) break;
}
if(k==i){//当没有执行break时即为没有重复的字符串(核心)
re[n]=src[i];
++n;
}
}
re[n] = '\0';
return re;
}
Main:
// An highlighted block
var foo = 'bar';
输入测试数据和运行结果














 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









