






MapReduce
MapReduce是负责计算的,HDFS是负责存储的。
Hadoop是负责处理海量数据的存储和计算的。
MapReduce的概述
定义

优缺点

核心思想

1、分布式的运算程序往往需要分成至少 2 个阶段。
2、第一个阶段的 MapTask 并发实例,完全并行运行,互不相干。
3、第二个阶段的 ReduceTask 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask 并发实例的输出。
4、MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行。总结:分析 WordCount 数据流走向深入理解 MapReduce 核心思想。
Map阶段是分数据,将大文件分成多个小文件(以块大小分文件,即默认128M文件),然后分开执行MapTask
MapTask工作时,是按行读取数据,并进行处理的。
MapReduce进程

官方WordCount源码
采用反编译工具反编译源码,发现 WordCount 案例有 Map 类、Reduce 类和驱动类。且数据的类型是 Hadoop 自身封装的序列化类型。
Hadoop Writable类型与Java的比较

编写的程序分成三个部分:Mapper、Reducer 和 Driver。

集成自己的父类中的自己就是值Hadoop,涉及的父类就是Mapper和Reducer。
KV对就是,我们常见的键值对,和JAVA中的Map很相似。
以下是官方的WordCount源码
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
// mr程序其实也就是一个Job
// A从这里开始
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
// A从到这里结束,是声明一个Job的范式
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
// Reduce
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
// Map
// 前两个参数是输入数据的类型,第一个是字节的偏移量,第二个是具体内容;
// 后两个参数是输出数据的类型,第三个是输出具体的内容(Key),第四个是Value
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
WordCount实操
目的:在给定的文本文件中统计输出每一个单词出现的次数总和
输入文件:hello.txt,内容如下:
hello hello hello
wo
shi
caocao caocao caocao
ye
shi
cao
cao
hai shi caocao
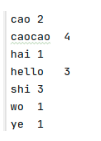
期望输出结果
cao 2
caocao 4
hai 1
hello 3
shi 3
wo 1
ye 1
需求分析(以第一行hello hello hello为例):
Map阶段:
1、将MapTask传入文本转成String;
2、根据空格将数据切分成单词;
## 例如第一行切分成三个hello
hello
hello
hello
3、将单词输出成键值对:<单词,1>;
## 例如第一行得到的结果是
hello,1
hello,1
hello,1
所有的Map任务全部执行完成才会进入Reduce阶段。
Reduce阶段;
1、汇总各个Key的个数;
2、输出该Key的总数;
## 例如第一行得到的结果是
hello,3
Driver:
1、获取配置信息,获取Job对象实例;
2、指定本程序的jar所在的本地路径;
3、关联Mapper/Reducer业务类;
4、指定Mapper输出数据的KV类型;
5、指定最终输出的数据KV类型;
6、指定job的输入原始文件所在目录;
7、指定job的输出结果所在目录;
8、提交作业。
代码如下:
Mapper类
/**
* map阶段
* 1、KEYIN 输入数据的key
* 2、VALUEIN 输入数据的value
* 3、KEYOUT 输出数据的key
* 4、VALUEOUT 输出数据的value
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// hello hello hello
// 1、获取一行数据
String line = value.toString();
// 2、切割单词
String[] words = line.split(" ");
// 3、循环写出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
Reducer类
/**
* reduce
* 1、KEYIN 输入数据的key
* 2、VALUEIN 输入数据的value
* 3、KEYOUT 输出数据的key
* 4、VALUEOUT 输出数据的value
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 第一次运行key是hello
// 第一次运行values是
// cao,1
// cao,1
// 会按照String的顺序进行排序
// 1、累加求和
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
// 2、写出,第一次写出为cao,2
v.set(sum);
context.write(key, v);
}
}
Driver类
public class WordCountDriver {
public static void main (String[] args) throws Exception {
// 1、获取Job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2、设置jar文件存储位置,即驱动类的路径
job.setJarByClass(WordCountDriver.class);
// 3、关联Map和Reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4、设置Mapper阶段输出数据的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5、设置最终数据输出的key和value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6、设置程序输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7、提交Job对象
// job.submit();
job.waitForCompletion(true);
}
}
输出结果如下(重复运行时需要将out目录删除,否则会报错):
将其放到集群上运行,那么首先需要将其打成jar包,打成jar包之后上传到集群上,然后执行以下命令进行执行
## hadoop jar jar文件路径 driver的包名 输入路径 输出路径
hadoop jar wordCount.jar com.starnet.mapreduce.wordcount.WordCountDriver /sanguo/wei /sanguo/wei/output














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









