







MapReduce经典入门案例:WordCount
一、业务需求
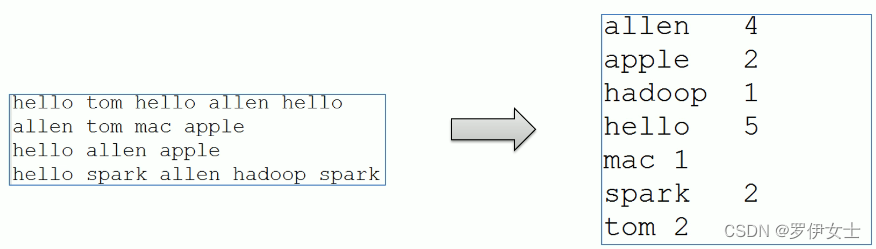
WordCount中文叫做单词统计、词频统计,指的是统计指定文件中,每个单词出现的总次数。这个是大数据计算领域经典的入门案例,相当于Hello World。
虽然WordCount业务及其简单,但是希望能够通过案例感受背后MapReduce的执行流程和默认的行为机制,这才是关键。
二、编程思路
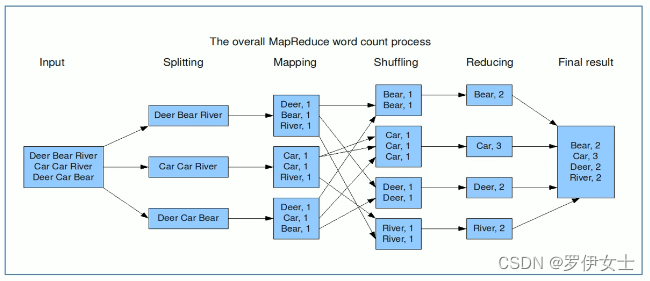
map阶段的核心∶把输入的数据经过切割,全部标记1。因此输出就是<单词,1>。
shuffle阶段核心∶经过默认的排序分区分组,key相同的单词会作为一组数据构成新的kv对。
reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1
三、WordCount案例代码详解
pom文件
一定要注意,hadoop-hdfs依赖放在最后面!!!
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.LJY</groupId>
<artifactId>MR_WordCount</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version> 2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version> 2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version> 2.9.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib</classpathPrefix>
<mainClass>WordCountDriver_v1</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
WordCountMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//按照编程规范,这个WordCountMapper类要继承父类Mapper
/**
* WordCount Mapper类 对应着MapTask
*
* KEYIN:表示map阶段输入kv中的k类型,在默认组件下,是起始位置偏移量,因此是LongWritable
* VALUEIN:表示map阶段输入kv中的v类型, 在默认组件下,是每一行内容,因此是Text
* todo MapReduce中有默认的读取数据组件,叫做TextInputFormat
* todo 其读数据的行为是一行一行地读数据 返回kv键值对
* k:每一行起始位置的偏移量 通常无意义
* v:这一行的文本内容
* KEYOUT:表示map阶段输出kv中的k类型, 跟业务相关,本需求中输出的是单词,因此是Text
* VALUEOUT:表示map阶段输出kv中的v类型, 跟业务相关,本需求中输出的是单词次数1,因此是LongWritable,如果单词量较少,也可以是IntWritable
*
*/
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
private Text outKey = new Text();
private final static LongWritable outValue = new LongWritable(1); //final终止防止被修改,value值写死
/**
* 重写父类map方法
* map方法是mapper阶段核心方法,也是具体业务逻辑实现的方法
* 注意:该方法被调用的次数与输入的kv键值对有关,每当TextInputFormat读取返回一个kv键值对,就调用一次map方法进行业务处理
* 默认情况下,map方法是基于行来处理数据的
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//拿取一行数据转换String类型
String line = value.toString();
//根据分隔符进行切割
/**
* 这里的\\s+,第一个\是转义字符,表示第二个\只是普通的斜杠,\s表示任意空白字符
*/
String[] words = line.split(" ");
//遍历数组
for (String word : words) { //获取每个单词
//输出数据 把每个单词标记1 输出结果是<单词,1>
//使用上下文对象 将数据输出
// context.write(new Text(word),new LongWritable(1));
/**
* 如果单词量较大,每次都要new一个新的对象,很麻烦,所以可以使用单词复用,统一创建一个对象,把所有内容赋值进去
*/
outKey.set(word); //赋值
context.write(outKey,outValue);
}
}
}
WordCountReducer
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reduce阶段的处理类,对应进程中的ReduceTask
* KEYIN:表示reduce阶段输入kv中的k类型,对应的是map输出的key,因此在本需求中就是单词 Text
* VALUEIN:表示reduce阶段输入kv中的v类型, 对应的是map输出的value,因此在本需求中就是单词的次数1 LongWritable
* KEYOUT:表示reduce阶段输出kv中的k类型, 跟业务相关,本需求中输出的是单词,因此是Text
* VALUEOUT:表示reduce阶段输出kv中的v类型, 跟业务相关,本需求中输出的是单词的总次数,因此是LongWritable
*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable outValue = new LongWritable();
/**
*todo Q:当map的所有输出数据来到reduce之后,该如何调用reduce方法进行处理?
* <hello,1><hadoop,1><hello,1><hadoop,1><hello,1>
*1、排序:规则:根据key的字典序进行排序 a-z
* <hadoop,1><hadoop,1><hadoop,1><hello,1><hello,1>
*2、分组:规则:key相同的分为一组
* <hadoop,1><hadoop,1><hadoop,1>
* <hello,1><hello,1>
*3、分组之后,同一组的数据组成一个新的kv键值对,调用一次reduce方法。reduce方法基于分组调用一个分组调用一次
* todo 同一组数据组成一个新的kv键值对
* 新key:该组共同的key
* 新value:该组所有的value组成的一个迭代器 Iterable
* <hadoop,1><hadoop,1><hadoop,1>-------<hadoop,Iterable[1,1,1]>
* <hello,1><hello,1>-------------------<hello,Iterable[1,1]>
*/
//重写父类的reduce方法
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//统计变量
long count = 0;
//遍历该组的values
for (LongWritable value : values) {
//累加计算总次数
count += value.get();
}
//赋值
outValue.set(count);
//最终使用上下文输出结果
context.write(key,outValue);
}
}
WordCountDriver
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reduce阶段的处理类,对应进程中的ReduceTask
* KEYIN:表示reduce阶段输入kv中的k类型,对应的是map输出的key,因此在本需求中就是单词 Text
* VALUEIN:表示reduce阶段输入kv中的v类型, 对应的是map输出的value,因此在本需求中就是单词的次数1 LongWritable
* KEYOUT:表示reduce阶段输出kv中的k类型, 跟业务相关,本需求中输出的是单词,因此是Text
* VALUEOUT:表示reduce阶段输出kv中的v类型, 跟业务相关,本需求中输出的是单词的总次数,因此是LongWritable
*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable outValue = new LongWritable();
/**
*todo Q:当map的所有输出数据来到reduce之后,该如何调用reduce方法进行处理?
* <hello,1><hadoop,1><hello,1><hadoop,1><hello,1>
*1、排序:规则:根据key的字典序进行排序 a-z
* <hadoop,1><hadoop,1><hadoop,1><hello,1><hello,1>
*2、分组:规则:key相同的分为一组
* <hadoop,1><hadoop,1><hadoop,1>
* <hello,1><hello,1>
*3、分组之后,同一组的数据组成一个新的kv键值对,调用一次reduce方法。reduce方法基于分组调用一个分组调用一次
* todo 同一组数据组成一个新的kv键值对
* 新key:该组共同的key
* 新value:该组所有的value组成的一个迭代器 Iterable
* <hadoop,1><hadoop,1><hadoop,1>-------<hadoop,Iterable[1,1,1]>
* <hello,1><hello,1>-------------------<hello,Iterable[1,1]>
*/
//重写父类的reduce方法
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//统计变量
long count = 0;
//遍历该组的values
for (LongWritable value : values) {
//累加计算总次数
count += value.get();
}
//赋值
outValue.set(count);
//最终使用上下文输出结果
context.write(key,outValue);
}
}
WordCountDriver使用工具类ToolRunner提交MapReduce作业
与上一个方法选一个即可,官方推荐用本方法
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 使用工具类ToolRunner提交MapReduce作业
* 需要继承configured类,注意选hadoop下的,实现一个接口Tool
*/
public class WordCountDriver_v2 extends Configured implements Tool {
public static void main(String[] args) throws Exception{
//创建配置对象
Configuration conf = new Configuration();
//todo 使用工具类ToolRunner提交程序
int status = ToolRunner.run(conf, new WordCountDriver_v2(),args);
//退出客户端
System.exit(status);
}
/**
*ctrl + i ,实现run方法
*/
@Override
public int run(String[] args) throws Exception {
//构造job作业的实例,参数(配置对象,job名字)
Job job = Job.getInstance(getConf(), WordCountDriver_v2.class.getSimpleName());
//设置mr程序运行的主类
job.setJarByClass(WordCountDriver_v1.class);
//设置本次mr程序的mapper类型、reducer类型
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//指定mapper阶段输出的key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reducer阶段输出的key value数据类型,也是mr程序最终的输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//配置本次作业的输入数据路径和输出数据路径
//todo 默认组件 TextInputFormat TextOutputFormat
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
return job.waitForCompletion(true)? 0:1;
}
}















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









