




C++ Atomic深度解析:从CPU指令到内存模型的完整剖析
🚀 引言:原子操作的革命意义
在多核并发编程的战场上,传统的互斥锁如同重炮,威力巨大但开销不菲。而std::atomic则像精准的狙击枪——轻量、快速、无锁。它不仅仅是一个库特性,更代表了现代CPU架构与编程语言的深度融合,是硬件与软件协同进化的杰作。
今天,我们将从CPU的微观世界出发,探索atomic操作的神秘面纱,揭开内存模型的深层奥秘!
🔬 硬件基础:CPU层面的原子操作
⚡ CPU原子指令的本质
在探讨C++ atomic之前,我们必须理解CPU硬件层面的支持。现代处理器提供了一系列原子指令:
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
// 演示硬件原子操作的基本概念
class HardwareAtomicDemo {
public:
static void demonstrate_basic_atomicity() {
std::cout << "=== 硬件原子操作演示 ===" << std::endl;
std::atomic<int> atomic_counter{0};
int regular_counter = 0;
const int NUM_THREADS = 10;
const int INCREMENTS_PER_THREAD = 10000;
// 测试原子操作
auto atomic_test = [&]() {
std::vector<std::thread> threads;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < INCREMENTS_PER_THREAD; ++j) {
atomic_counter.fetch_add(1, std::memory_order_relaxed);
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start);
};
// 测试非原子操作(错误示例)
auto regular_test = [&]() {
std::vector<std::thread> threads;
regular_counter = 0; // 重置
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < INCREMENTS_PER_THREAD; ++j) {
regular_counter++; // 竞态条件!
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start);
};
auto atomic_duration = atomic_test();
auto regular_duration = regular_test();
int expected = NUM_THREADS * INCREMENTS_PER_THREAD;
std::cout << "期望结果: " << expected << std::endl;
std::cout << "原子操作结果: " << atomic_counter.load() << " (耗时: "
<< atomic_duration.count() << "μs)" << std::endl;
std::cout << "普通操作结果: " << regular_counter << " (耗时: "
<< regular_duration.count() << "μs)" << std::endl;
std::cout << "数据一致性: 原子=" << (atomic_counter.load() == expected ? "✓" : "✗")
<< ", 普通=" << (regular_counter == expected ? "✓" : "✗") << std::endl;
}
};
🎯 Compare-And-Swap (CAS) 深度解析
CAS是原子操作的核心,它的伪代码逻辑是:
function CAS(address, expected, new_value):
current = *address
if current == expected:
*address = new_value
return true
else:
return false
#include <atomic>
#include <iostream>
#include <thread>
#include <random>
class CASDeepDive {
private:
std::atomic<int> shared_value{0};
public:
// 手动实现自旋锁
void manual_spinlock_demo() {
std::cout << "\n=== CAS自旋锁实现 ===" << std::endl;
std::atomic<bool> lock_flag{false};
int protected_resource = 0;
auto worker = [&](int thread_id) {
for (int i = 0; i < 5; ++i) {
// 自旋获取锁
while (true) {
bool expected = false;
if (lock_flag.compare_exchange_weak(expected, true,
std::memory_order_acquire)) {
break; // 成功获取锁
}
// 自旋等待(可以添加短暂延迟优化)
std::this_thread::yield();
}
// 临界区
std::cout << "线程" << thread_id << " 获得锁,资源值: "
<< ++protected_resource << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
// 释放锁
lock_flag.store(false, std::memory_order_release);
}
};
std::thread t1(worker, 1);
std::thread t2(worker, 2);
t1.join();
t2.join();
std::cout << "最终资源值: " << protected_resource << std::endl;
}
// ABA问题演示
void demonstrate_aba_problem() {
std::cout << "\n=== ABA问题演示 ===" << std::endl;
struct Node {
int data;
Node* next;
Node(int d) : data(d), next(nullptr) {}
};
std::atomic<Node*> head{nullptr};
// 初始化链表: head -> A -> B
Node* nodeA = new Node(1);
Node* nodeB = new Node(2);
nodeA->next = nodeB;
head.store(nodeA);
std::cout << "初始状态: head -> A(1) -> B(2)" << std::endl;
// 线程1:尝试删除A
std::thread thread1([&]() {
std::this_thread::sleep_for(std::chrono::milliseconds(100));
Node* expected = head.load();
std::cout << "线程1: 准备删除节点A,当前head指向: " << expected->data << std::endl;
// 模拟被打断,让线程2执行
std::this_thread::sleep_for(std::chrono::milliseconds(200));
// 尝试CAS操作(此时可能发生ABA问题)
Node* new_head = expected->next;
if (head.compare_exchange_strong(expected, new_head)) {
std::cout << "线程1: 成功删除节点A" << std::endl;
delete expected;
} else {
std::cout << "线程1: CAS失败,head已被修改" << std::endl;
}
});
// 线程2:删除A和B,然后重新插入A
std::thread thread2([&]() {
std::this_thread::sleep_for(std::chrono::milliseconds(150));
std::cout << "线程2: 开始修改链表" << std::endl;
// 删除A和B
Node* oldA = head.load();
Node* oldB = oldA->next;
// 创建新的A节点
Node* newA = new Node(1);
head.store(newA);
std::cout << "线程2: 删除旧A、B,插入新A" << std::endl;
delete oldA;
delete oldB;
});
thread1.join();
thread2.join();
if (head.load()) {
std::cout << "最终head指向: " << head.load()->data << std::endl;
delete head.load();
}
}
// 无锁栈实现
class LockFreeStack {
private:
struct Node {
std::atomic<int> data;
Node* next;
Node(int value) : data(value), next(nullptr) {}
};
std::atomic<Node*> head{nullptr};
public:
void push(int value) {
Node* new_node = new Node(value);
new_node->next = head.load();
while (!head.compare_exchange_weak(new_node->next, new_node)) {
// CAS失败,重试
}
}
bool pop(int& result) {
Node* old_head = head.load();
while (old_head && !head.compare_exchange_weak(old_head, old_head->next)) {
// CAS失败,重新加载头节点
}
if (old_head == nullptr) {
return false; // 栈为空
}
result = old_head->data;
delete old_head;
return true;
}
bool empty() const {
return head.load() == nullptr;
}
~LockFreeStack() {
int dummy;
while (pop(dummy)) {
// 清空栈
}
}
};
void test_lockfree_stack() {
std::cout << "\n=== 无锁栈测试 ===" << std::endl;
LockFreeStack stack;
std::atomic<int> push_count{0};
std::atomic<int> pop_count{0};
// 生产者线程
auto producer = [&](int thread_id) {
for (int i = 0; i < 100; ++i) {
stack.push(thread_id * 1000 + i);
push_count++;
}
};
// 消费者线程
auto consumer = [&]() {
int value;
while (pop_count < 300) { // 等待所有元素
if (stack.pop(value)) {
pop_count++;
}
std::this_thread::yield();
}
};
std::vector<std::thread> producers;
std::vector<std::thread> consumers;
// 启动生产者
for (int i = 0; i < 3; ++i) {
producers.emplace_back(producer, i);
}
// 启动消费者
for (int i = 0; i < 2; ++i) {
consumers.emplace_back(consumer);
}
// 等待完成
for (auto& t : producers) t.join();
for (auto& t : consumers) t.join();
std::cout << "生产数量: " << push_count.load() << std::endl;
std::cout << "消费数量: " << pop_count.load() << std::endl;
std::cout << "栈是否为空: " << (stack.empty() ? "是" : "否") << std::endl;
}
};
🧠 内存模型:并发的哲学基础
📋 C++内存模型概述
C++11引入的内存模型定义了多线程程序中内存操作的语义。这不仅仅是技术规范,更是并发哲学的体现:
⚡ 内存序详细分析
#include <atomic>
#include <thread>
#include <iostream>
#include <cassert>
class MemoryOrderingDemo {
private:
std::atomic<bool> flag{false};
std::atomic<int> data{0};
public:
// 1. Relaxed ordering - 最弱的内存序
void demonstrate_relaxed() {
std::cout << "=== memory_order_relaxed 演示 ===" << std::endl;
std::atomic<int> counter{0};
std::vector<std::thread> threads;
// 多个线程并发递增
for (int i = 0; i < 4; ++i) {
threads.emplace_back([&counter, i]() {
for (int j = 0; j < 1000; ++j) {
counter.fetch_add(1, std::memory_order_relaxed);
}
std::cout << "线程" << i << " 完成" << std::endl;
});
}
for (auto& t : threads) {
t.join();
}
std::cout << "Relaxed ordering 结果: " << counter.load(std::memory_order_relaxed) << std::endl;
std::cout << "说明:只保证原子性,不保证操作间的顺序" << std::endl;
}
// 2. Acquire-Release ordering
void demonstrate_acquire_release() {
std::cout << "\n=== memory_order_acquire/release 演示 ===" << std::endl;
std::atomic<bool> ready{false};
std::atomic<int> shared_data{0};
// 生产者线程(Release)
std::thread producer([&]() {
shared_data.store(42, std::memory_order_relaxed); // 设置数据
ready.store(true, std::memory_order_release); // 发布信号
std::cout << "生产者: 数据已准备好" << std::endl;
});
// 消费者线程(Acquire)
std::thread consumer([&]() {
while (!ready.load(std::memory_order_acquire)) { // 获取信号
std::this_thread::yield();
}
int value = shared_data.load(std::memory_order_relaxed); // 读取数据
std::cout << "消费者: 读取到数据 = " << value << std::endl;
assert(value == 42); // 保证能看到生产者的写入
});
producer.join();
consumer.join();
std::cout << "说明:Release确保之前的写入对Acquire可见" << std::endl;
}
// 3. Sequential Consistency - 最强的内存序
void demonstrate_seq_cst() {
std::cout << "\n=== memory_order_seq_cst 演示 ===" << std::endl;
std::atomic<int> x{0}, y{0};
std::atomic<int> r1{0}, r2{0};
auto test_run = [&]() {
x.store(0, std::memory_order_seq_cst);
y.store(0, std::memory_order_seq_cst);
r1.store(0, std::memory_order_seq_cst);
r2.store(0, std::memory_order_seq_cst);
std::thread t1([&]() {
x.store(1, std::memory_order_seq_cst);
r1.store(y.load(std::memory_order_seq_cst), std::memory_order_seq_cst);
});
std::thread t2([&]() {
y.store(1, std::memory_order_seq_cst);
r2.store(x.load(std::memory_order_seq_cst), std::memory_order_seq_cst);
});
t1.join();
t2.join();
return std::make_pair(r1.load(), r2.load());
};
int count_00 = 0, count_01 = 0, count_10 = 0, count_11 = 0;
int iterations = 10000;
for (int i = 0; i < iterations; ++i) {
auto result = test_run();
if (result.first == 0 && result.second == 0) count_00++;
else if (result.first == 0 && result.second == 1) count_01++;
else if (result.first == 1 && result.second == 0) count_10++;
else if (result.first == 1 && result.second == 1) count_11++;
}
std::cout << "结果分布 (r1, r2):" << std::endl;
std::cout << "(0,0): " << count_00 << " 次" << std::endl;
std::cout << "(0,1): " << count_01 << " 次" << std::endl;
std::cout << "(1,0): " << count_10 << " 次" << std::endl;
std::cout << "(1,1): " << count_11 << " 次" << std::endl;
std::cout << "说明:seq_cst保证全局一致的执行顺序,(0,0)情况不应该出现" << std::endl;
}
// 4. Memory fence演示
void demonstrate_memory_fence() {
std::cout << "\n=== Memory Fence 演示 ===" << std::endl;
std::atomic<int> a{0}, b{0};
std::atomic<int> x{0}, y{0};
std::thread t1([&]() {
a.store(1, std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release); // Release fence
b.store(1, std::memory_order_relaxed);
});
std::thread t2([&]() {
while (b.load(std::memory_order_relaxed) == 0) {
std::this_thread::yield();
}
std::atomic_thread_fence(std::memory_order_acquire); // Acquire fence
x.store(a.load(std::memory_order_relaxed), std::memory_order_relaxed);
});
t1.join();
t2.join();
std::cout << "a的值: " << a.load() << std::endl;
std::cout << "x的值: " << x.load() << std::endl;
std::cout << "说明:内存栅栏确保了操作的顺序" << std::endl;
}
};
🔧 不同数据类型的原子操作
📊 支持的原子类型全览
#include <atomic>
#include <iostream>
#include <type_traits>
#include <complex>
class AtomicTypesDemo {
public:
static void demonstrate_supported_types() {
std::cout << "=== 原子类型支持情况 ===" << std::endl;
// 整数类型
std::cout << "整数类型原子支持:" << std::endl;
std::cout << " atomic<bool>: " << std::atomic<bool>::is_always_lock_free << std::endl;
std::cout << " atomic<char>: " << std::atomic<char>::is_always_lock_free << std::endl;
std::cout << " atomic<int>: " << std::atomic<int>::is_always_lock_free << std::endl;
std::cout << " atomic<long>: " << std::atomic<long>::is_always_lock_free << std::endl;
std::cout << " atomic<long long>: " << std::atomic<long long>::is_always_lock_free << std::endl;
// 指针类型
std::cout << "\n指针类型原子支持:" << std::endl;
std::cout << " atomic<void*>: " << std::atomic<void*>::is_always_lock_free << std::endl;
std::cout << " atomic<int*>: " << std::atomic<int*>::is_always_lock_free << std::endl;
// 浮点类型(C++20开始支持)
std::cout << "\n浮点类型原子支持:" << std::endl;
std::cout << " atomic<float>: " << std::atomic<float>::is_always_lock_free << std::endl;
std::cout << " atomic<double>: " << std::atomic<double>::is_always_lock_free << std::endl;
// 用户定义类型
struct SmallStruct {
int a, b;
};
struct LargeStruct {
int data[100];
};
std::cout << "\n用户定义类型原子支持:" << std::endl;
std::cout << " atomic<SmallStruct> (" << sizeof(SmallStruct) << " bytes): "
<< std::atomic<SmallStruct>::is_always_lock_free << std::endl;
std::cout << " atomic<LargeStruct> (" << sizeof(LargeStruct) << " bytes): "
<< std::atomic<LargeStruct>::is_always_lock_free << std::endl;
}
// 整数原子操作
void demonstrate_integer_atomics() {
std::cout << "\n=== 整数原子操作演示 ===" << std::endl;
std::atomic<int> counter{10};
std::cout << "初始值: " << counter.load() << std::endl;
// 基本操作
std::cout << "fetch_add(5): " << counter.fetch_add(5) << ", 新值: " << counter.load() << std::endl;
std::cout << "fetch_sub(3): " << counter.fetch_sub(3) << ", 新值: " << counter.load() << std::endl;
std::cout << "fetch_and(0xFF): " << counter.fetch_and(0xFF) << ", 新值: " << counter.load() << std::endl;
std::cout << "fetch_or(0x10): " << counter.fetch_or(0x10) << ", 新值: " << counter.load() << std::endl;
std::cout << "fetch_xor(0x05): " << counter.fetch_xor(0x05) << ", 新值: " << counter.load() << std::endl;
// 前缀和后缀操作
std::cout << "前缀递增 ++: " << ++counter << std::endl;
std::cout << "后缀递增 ++: " << counter++ << ", 新值: " << counter.load() << std::endl;
std::cout << "前缀递减 --: " << --counter << std::endl;
std::cout << "后缀递减 --: " << counter-- << ", 新值: " << counter.load() << std::endl;
// 复合赋值操作
counter += 10;
std::cout << "复合赋值 += 10: " << counter.load() << std::endl;
counter -= 5;
std::cout << "复合赋值 -= 5: " << counter.load() << std::endl;
counter &= 0x1F;
std::cout << "复合赋值 &= 0x1F: " << counter.load() << std::endl;
}
// 指针原子操作
void demonstrate_pointer_atomics() {
std::cout << "\n=== 指针原子操作演示 ===" << std::endl;
int array[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
std::atomic<int*> atomic_ptr{array};
std::cout << "初始指针指向: " << *atomic_ptr.load() << std::endl;
// 指针算术运算
int* old_ptr = atomic_ptr.fetch_add(3);
std::cout << "fetch_add(3) 返回旧值: " << *old_ptr << ", 新值: " << *atomic_ptr.load() << std::endl;
old_ptr = atomic_ptr.fetch_sub(1);
std::cout << "fetch_sub(1) 返回旧值: " << *old_ptr << ", 新值: " << *atomic_ptr.load() << std::endl;
// 指针比较和交换
int* expected = array + 2;
int* new_ptr = array + 5;
if (atomic_ptr.compare_exchange_strong(expected, new_ptr)) {
std::cout << "CAS成功,新指针指向: " << *atomic_ptr.load() << std::endl;
} else {
std::cout << "CAS失败,当前指针指向: " << *atomic_ptr.load() << std::endl;
}
}
// 自定义类型原子操作
struct Point {
int x, y;
Point() : x(0), y(0) {}
Point(int x_, int y_) : x(x_), y(y_) {}
bool operator==(const Point& other) const {
return x == other.x && y == other.y;
}
friend std::ostream& operator<<(std::ostream& os, const Point& p) {
return os << "(" << p.x << ", " << p.y << ")";
}
};
void demonstrate_custom_type_atomics() {
std::cout << "\n=== 自定义类型原子操作演示 ===" << std::endl;
std::atomic<Point> atomic_point{Point(1, 2)};
std::cout << "初始点: " << atomic_point.load() << std::endl;
std::cout << "是否无锁: " << (atomic_point.is_lock_free() ? "是" : "否") << std::endl;
// 原子交换
Point old_point = atomic_point.exchange(Point(10, 20));
std::cout << "exchange后 - 旧值: " << old_point << ", 新值: " << atomic_point.load() << std::endl;
// 比较交换
Point expected{10, 20};
Point new_point{30, 40};
if (atomic_point.compare_exchange_strong(expected, new_point)) {
std::cout << "CAS成功,新点: " << atomic_point.load() << std::endl;
} else {
std::cout << "CAS失败,当前点: " << atomic_point.load() << std::endl;
}
// 多线程安全更新
std::vector<std::thread> threads;
std::atomic<int> update_count{0};
for (int i = 0; i < 4; ++i) {
threads.emplace_back([&, i]() {
for (int j = 0; j < 100; ++j) {
Point current = atomic_point.load();
Point new_val{current.x + 1, current.y + 1};
while (!atomic_point.compare_exchange_weak(current, new_val)) {
new_val.x = current.x + 1;
new_val.y = current.y + 1;
}
update_count++;
}
});
}
for (auto& t : threads) {
t.join();
}
std::cout << "多线程更新后: " << atomic_point.load() << std::endl;
std::cout << "总更新次数: " << update_count.load() << std::endl;
}
};
🚀 性能分析:原子操作 vs 传统锁
📈 详细性能基准测试
#include <atomic>
#include <mutex>
#include <shared_mutex>
#include <chrono>
#include <thread>
#include <vector>
#include <iostream>
class PerformanceBenchmark {
private:
static constexpr int ITERATIONS = 1000000;
static constexpr int NUM_THREADS = 8;
public:
// 测试不同同步机制的性能
static void comprehensive_benchmark() {
std::cout << "=== 同步机制性能对比 (迭代: " << ITERATIONS
<< ", 线程: " << NUM_THREADS << ") ===" << std::endl;
// 1. 原子操作 (relaxed)
auto atomic_relaxed_time = benchmark_atomic_relaxed();
// 2. 原子操作 (seq_cst)
auto atomic_seqcst_time = benchmark_atomic_seqcst();
// 3. 互斥锁
auto mutex_time = benchmark_mutex();
// 4. 自旋锁
auto spinlock_time = benchmark_spinlock();
// 5. 读写锁
auto rwlock_time = benchmark_rwlock();
// 6. 无同步(错误示例)
auto nosync_time = benchmark_nosync();
std::cout << "\n性能结果:" << std::endl;
std::cout << "原子操作 (relaxed): " << atomic_relaxed_time << " μs" << std::endl;
std::cout << "原子操作 (seq_cst): " << atomic_seqcst_time << " μs" << std::endl;
std::cout << "互斥锁: " << mutex_time << " μs" << std::endl;
std::cout << "自旋锁: " << spinlock_time << " μs" << std::endl;
std::cout << "读写锁: " << rwlock_time << " μs" << std::endl;
std::cout << "无同步 (错误): " << nosync_time << " μs" << std::endl;
std::cout << "\n相对性能 (以原子relaxed为基准):" << std::endl;
std::cout << "原子操作 (seq_cst): " << (double)atomic_seqcst_time / atomic_relaxed_time << "x" << std::endl;
std::cout << "互斥锁: " << (double)mutex_time / atomic_relaxed_time << "x" << std::endl;
std::cout << "自旋锁: " << (double)spinlock_time / atomic_relaxed_time << "x" << std::endl;
std::cout << "读写锁: " << (double)rwlock_time / atomic_relaxed_time << "x" << std::endl;
}
private:
static long benchmark_atomic_relaxed() {
std::atomic<long> counter{0};
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < ITERATIONS; ++j) {
counter.fetch_add(1, std::memory_order_relaxed);
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}
static long benchmark_atomic_seqcst() {
std::atomic<long> counter{0};
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < ITERATIONS; ++j) {
counter.fetch_add(1, std::memory_order_seq_cst);
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}
static long benchmark_mutex() {
long counter = 0;
std::mutex mtx;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < ITERATIONS; ++j) {
std::lock_guard<std::mutex> lock(mtx);
++counter;
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}
// 简单自旋锁实现
class SpinLock {
std::atomic<bool> flag{false};
public:
void lock() {
while (flag.exchange(true, std::memory_order_acquire)) {
while (flag.load(std::memory_order_relaxed)) {
std::this_thread::yield();
}
}
}
void unlock() {
flag.store(false, std::memory_order_release);
}
};
static long benchmark_spinlock() {
long counter = 0;
SpinLock spinlock;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < ITERATIONS; ++j) {
spinlock.lock();
++counter;
spinlock.unlock();
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}
static long benchmark_rwlock() {
long counter = 0;
std::shared_mutex rw_mtx;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < ITERATIONS; ++j) {
std::unique_lock<std::shared_mutex> lock(rw_mtx);
++counter;
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}
static long benchmark_nosync() {
long counter = 0;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < ITERATIONS; ++j) {
++counter; // 竞态条件
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}
};
🎨 实际应用场景
🔧 高性能计数器
#include <atomic>
#include <thread>
#include <vector>
#include <chrono>
#include <iostream>
// 高性能多线程计数器
class HighPerformanceCounter {
private:
// 使用padding避免false sharing
struct alignas(64) PaddedCounter {
std::atomic<long> value{0};
};
static constexpr int NUM_COUNTERS = 8;
PaddedCounter counters_[NUM_COUNTERS];
std::atomic<int> thread_counter_{0};
public:
void increment() {
// 每个线程使用不同的计数器以减少竞争
thread_local int my_counter = thread_counter_.fetch_add(1) % NUM_COUNTERS;
counters_[my_counter].value.fetch_add(1, std::memory_order_relaxed);
}
long get_total() const {
long total = 0;
for (int i = 0; i < NUM_COUNTERS; ++i) {
total += counters_[i].value.load(std::memory_order_relaxed);
}
return total;
}
void reset() {
for (int i = 0; i < NUM_COUNTERS; ++i) {
counters_[i].value.store(0, std::memory_order_relaxed);
}
thread_counter_.store(0);
}
};
// 传统单计数器对比
class SimpleCounter {
private:
std::atomic<long> value_{0};
public:
void increment() {
value_.fetch_add(1, std::memory_order_relaxed);
}
long get_total() const {
return value_.load(std::memory_order_relaxed);
}
void reset() {
value_.store(0);
}
};
void counter_performance_test() {
std::cout << "=== 高性能计数器测试 ===" << std::endl;
const int num_threads = 8;
const int increments_per_thread = 1000000;
// 测试高性能计数器
{
HighPerformanceCounter hp_counter;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < increments_per_thread; ++j) {
hp_counter.increment();
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "高性能计数器:" << std::endl;
std::cout << " 结果: " << hp_counter.get_total() << std::endl;
std::cout << " 耗时: " << duration.count() << "ms" << std::endl;
}
// 测试简单计数器
{
SimpleCounter simple_counter;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back([&]() {
for (int j = 0; j < increments_per_thread; ++j) {
simple_counter.increment();
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "简单计数器:" << std::endl;
std::cout << " 结果: " << simple_counter.get_total() << std::endl;
std::cout << " 耗时: " << duration.count() << "ms" << std::endl;
}
}
🎯 无锁队列实现
#include <atomic>
#include <memory>
// 单生产者单消费者无锁队列
template<typename T>
class SPSCQueue {
private:
struct Node {
std::atomic<T*> data{nullptr};
std::atomic<Node*> next{nullptr};
};
std::atomic<Node*> head_;
std::atomic<Node*> tail_;
public:
SPSCQueue() {
Node* dummy = new Node;
head_.store(dummy);
tail_.store(dummy);
}
~SPSCQueue() {
Node* current = head_.load();
while (current != nullptr) {
Node* next = current->next.load();
if (current->data.load()) {
delete current->data.load();
}
delete current;
current = next;
}
}
void enqueue(T item) {
Node* new_node = new Node;
T* data = new T(std::move(item));
Node* prev_tail = tail_.exchange(new_node);
prev_tail->data.store(data);
prev_tail->next.store(new_node);
}
bool dequeue(T& result) {
Node* head = head_.load();
Node* next = head->next.load();
if (next == nullptr) {
return false; // 队列为空
}
T* data = next->data.load();
if (data == nullptr) {
return false; // 数据还未准备好
}
result = *data;
delete data;
head_.store(next);
delete head;
return true;
}
bool empty() const {
Node* head = head_.load();
Node* next = head->next.load();
return next == nullptr;
}
};
void lockfree_queue_test() {
std::cout << "\n=== 无锁队列测试 ===" << std::endl;
SPSCQueue<int> queue;
std::atomic<bool> producer_done{false};
std::atomic<int> total_produced{0};
std::atomic<int> total_consumed{0};
// 生产者线程
std::thread producer([&]() {
for (int i = 0; i < 10000; ++i) {
queue.enqueue(i);
total_produced++;
}
producer_done.store(true);
});
// 消费者线程
std::thread consumer([&]() {
int value;
while (!producer_done.load() || !queue.empty()) {
if (queue.dequeue(value)) {
total_consumed++;
} else {
std::this_thread::yield();
}
}
});
producer.join();
consumer.join();
std::cout << "生产数量: " << total_produced.load() << std::endl;
std::cout << "消费数量: " << total_consumed.load() << std::endl;
std::cout << "队列是否为空: " << (queue.empty() ? "是" : "否") << std::endl;
}
🛡️ 内存屏障与缓存一致性
🔍 CPU缓存架构影响
💡 False Sharing问题与解决
#include <atomic>
#include <thread>
#include <chrono>
#include <iostream>
class FalseSharingDemo {
private:
// 错误示例:False sharing
struct BadLayout {
std::atomic<long> counter1{0};
std::atomic<long> counter2{0};
std::atomic<long> counter3{0};
std::atomic<long> counter4{0};
};
// 正确示例:使用padding避免false sharing
struct alignas(64) GoodCounter {
std::atomic<long> counter{0};
// 剩余字节会被padding填充,确保占用完整缓存行
};
struct GoodLayout {
GoodCounter counter1;
GoodCounter counter2;
GoodCounter counter3;
GoodCounter counter4;
};
public:
static void demonstrate_false_sharing() {
std::cout << "=== False Sharing 影响演示 ===" << std::endl;
const int iterations = 10000000;
// 测试false sharing情况
{
BadLayout bad_counters;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
threads.emplace_back([&]() {
for (int i = 0; i < iterations; ++i) {
bad_counters.counter1.fetch_add(1, std::memory_order_relaxed);
}
});
threads.emplace_back([&]() {
for (int i = 0; i < iterations; ++i) {
bad_counters.counter2.fetch_add(1, std::memory_order_relaxed);
}
});
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
auto bad_time = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "False sharing 布局耗时: " << bad_time.count() << "ms" << std::endl;
}
// 测试优化后的情况
{
GoodLayout good_counters;
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
threads.emplace_back([&]() {
for (int i = 0; i < iterations; ++i) {
good_counters.counter1.counter.fetch_add(1, std::memory_order_relaxed);
}
});
threads.emplace_back([&]() {
for (int i = 0; i < iterations; ++i) {
good_counters.counter2.counter.fetch_add(1, std::memory_order_relaxed);
}
});
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
auto good_time = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "优化布局耗时: " << good_time.count() << "ms" << std::endl;
}
std::cout << "说明:相邻的原子变量可能位于同一缓存行,造成false sharing" << std::endl;
std::cout << "sizeof(BadLayout): " << sizeof(BadLayout) << " bytes" << std::endl;
std::cout << "sizeof(GoodLayout): " << sizeof(GoodLayout) << " bytes" << std::endl;
}
};
🎯 最佳实践与性能优化
📋 选择合适的内存序
// 内存序选择指南
class MemoryOrderingGuide {
public:
// 场景1: 简单计数器 - 使用relaxed
static void scenario_simple_counter() {
std::atomic<int> counter{0};
// 多线程递增
auto worker = [&]() {
for (int i = 0; i < 1000; ++i) {
counter.fetch_add(1, std::memory_order_relaxed); // relaxed足够
}
};
std::vector<std::thread> threads;
for (int i = 0; i < 4; ++i) {
threads.emplace_back(worker);
}
for (auto& t : threads) {
t.join();
}
}
// 场景2: 标志同步 - 使用acquire-release
static void scenario_flag_synchronization() {
std::atomic<bool> ready{false};
int shared_data = 0;
std::thread producer([&]() {
shared_data = 42; // 准备数据
ready.store(true, std::memory_order_release); // 发布信号
});
std::thread consumer([&]() {
while (!ready.load(std::memory_order_acquire)) { // 获取信号
std::this_thread::yield();
}
// 此时保证能看到shared_data = 42
assert(shared_data == 42);
});
producer.join();
consumer.join();
}
// 场景3: 需要全局顺序 - 使用seq_cst
static void scenario_global_ordering() {
std::atomic<int> x{0}, y{0};
std::atomic<bool> flag1{false}, flag2{false};
std::thread t1([&]() {
x.store(1, std::memory_order_seq_cst);
flag1.store(true, std::memory_order_seq_cst);
});
std::thread t2([&]() {
y.store(1, std::memory_order_seq_cst);
flag2.store(true, std::memory_order_seq_cst);
});
std::thread t3([&]() {
while (!flag1.load(std::memory_order_seq_cst)) {}
if (flag2.load(std::memory_order_seq_cst)) {
assert(y.load(std::memory_order_seq_cst) == 1);
}
});
t1.join();
t2.join();
t3.join();
}
};
🛠️ 性能优化技巧
class OptimizationTechniques {
public:
// 技巧1: 批量操作减少竞争
class BatchCounter {
std::atomic<long> global_counter_{0};
public:
void increment_batch(int count) {
global_counter_.fetch_add(count, std::memory_order_relaxed);
}
long get_value() const {
return global_counter_.load(std::memory_order_relaxed);
}
};
// 技巧2: 线程本地聚合
class ThreadLocalAggregator {
std::atomic<long> global_sum_{0};
public:
void add_local_batch() {
thread_local long local_sum = 0;
thread_local int batch_count = 0;
local_sum += 1;
batch_count++;
if (batch_count >= 1000) { // 每1000次才同步到全局
global_sum_.fetch_add(local_sum, std::memory_order_relaxed);
local_sum = 0;
batch_count = 0;
}
}
long get_total() const {
return global_sum_.load(std::memory_order_relaxed);
}
};
// 技巧3: 使用合适的数据对齐
struct alignas(std::hardware_destructive_interference_size) AlignedAtomic {
std::atomic<int> value{0};
};
// 技巧4: 避免ABA问题的解决方案
template<typename T>
struct VersionedPointer {
T* ptr;
std::uintptr_t version;
VersionedPointer() : ptr(nullptr), version(0) {}
VersionedPointer(T* p, std::uintptr_t v) : ptr(p), version(v) {}
bool operator==(const VersionedPointer& other) const {
return ptr == other.ptr && version == other.version;
}
};
template<typename T>
class ABAResistantStack {
std::atomic<VersionedPointer<Node<T>>> head_;
struct Node {
T data;
Node* next;
Node(const T& item) : data(item), next(nullptr) {}
};
public:
void push(const T& item) {
Node* new_node = new Node(item);
VersionedPointer<Node> old_head = head_.load();
do {
new_node->next = old_head.ptr;
} while (!head_.compare_exchange_weak(
old_head,
VersionedPointer<Node>{new_node, old_head.version + 1}
));
}
bool pop(T& result) {
VersionedPointer<Node> old_head = head_.load();
while (old_head.ptr != nullptr) {
if (head_.compare_exchange_weak(
old_head,
VersionedPointer<Node>{old_head.ptr->next, old_head.version + 1}
)) {
result = old_head.ptr->data;
delete old_head.ptr;
return true;
}
}
return false;
}
};
};
🎪 总结:掌握原子操作的艺术
📊 何时使用atomic的决策矩阵
| 场景 | 推荐方案 | 内存序选择 | 性能特点 |
|---|---|---|---|
| 简单计数器 | atomic<int> | relaxed | 最快 |
| 标志通知 | atomic<bool> | acquire/release | 中等 |
| 复杂同步 | atomic + fence | seq_cst | 较慢 |
| 高频读写 | Thread-local + 批量 | relaxed | 优化版最快 |
| 指针操作 | atomic<T*> | acquire/release | 中等 |
| 自定义类型 | 小对象用atomic | seq_cst | 取决于大小 |
🎯 性能优化黄金法则
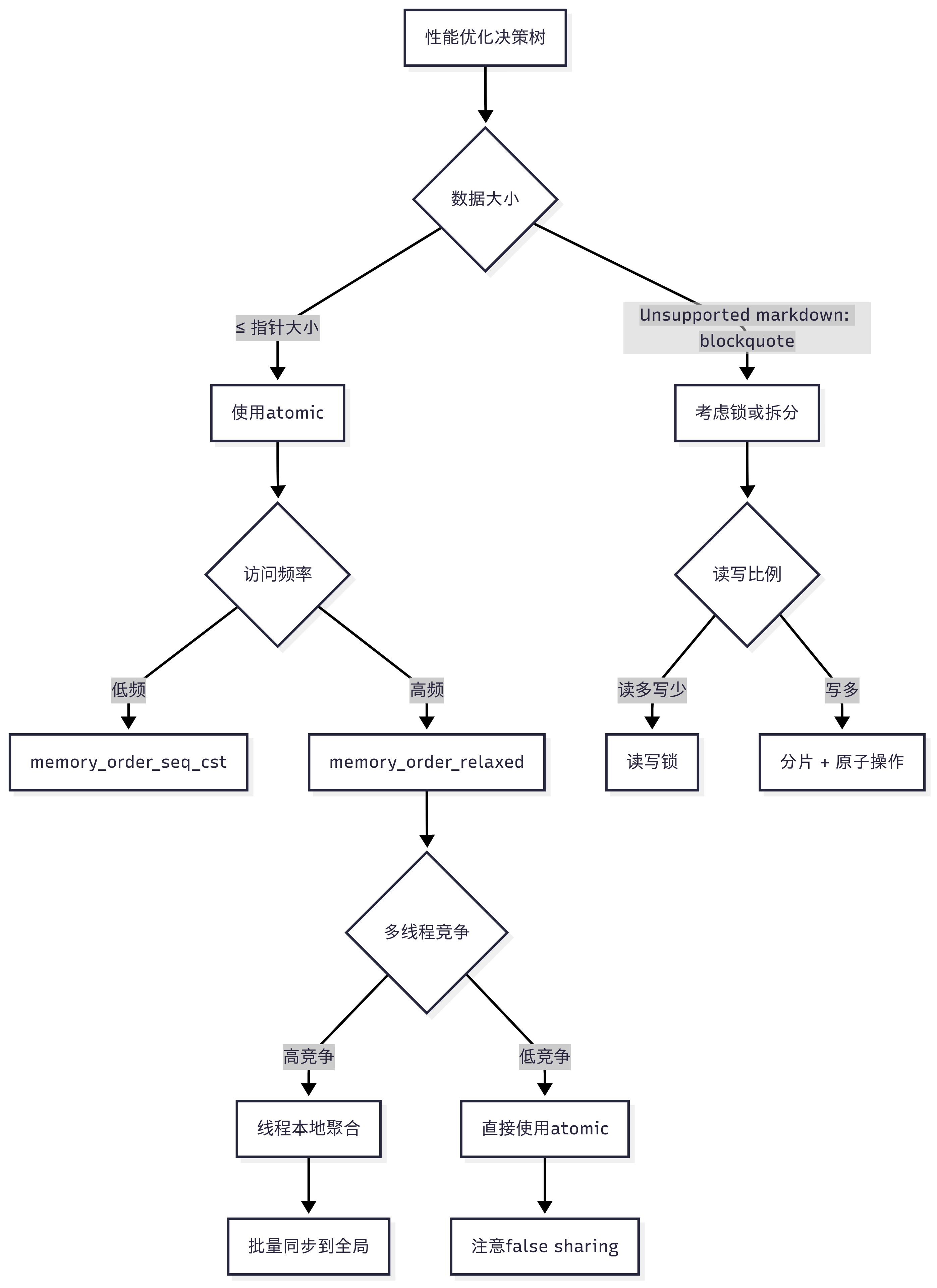
🌟 最终建议
C++的atomic操作是现代并发编程的核心工具,但要想真正掌握它,需要理解:
- 硬件基础:了解CPU缓存、内存屏障、CAS指令的工作原理
- 内存模型:掌握不同内存序的语义和适用场景
- 性能特性:知道何时使用atomic,何时使用锁
- 优化技巧:避免false sharing,使用合适的对齐和批量操作
- 实际应用:在合适的场景下构建无锁数据结构
记住这个核心原则:原子操作是工具而非万能药,选择合适的工具解决合适的问题!
通过深入理解atomic操作的底层机制和最佳实践,我们能够写出既高效又正确的并发程序。在多核时代,这不仅是技术技能,更是编程艺术的体现。


















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











