







前言
在多线程编程中,当多个线程试图同时访问和修改共享数据时,就需要考虑数据的一致性和可见性问题。C++的原子操作提供了对共享数据的无锁访问,但仅仅依赖原子操作并不足以完全解决所有同步问题。这时,原子内存序的概念就显得尤为重要。
原子内存序定义了原子操作之间的顺序以及这些操作与程序其他部分的交互方式。它影响了编译器优化、指令重排序以及处理器缓存的行为。选择合适的内存序对于实现高效且正确的多线程程序至关重要。
一、内存序
1、定义
在C++中,内存序(Memory Order)是一个与多线程编程和原子操作紧密相关的概念。它定义了处理器在访问内存时的顺序和可见性。在多核处理器或分布式系统中,不同的线程可能在不同的处理器上运行,并且它们对内存的访问可能是乱序的,这可能导致数据竞争(data race)和其他并发问题。
内存序是一个与多线程编程和原子操作紧密相关的概念,特别是在编写lock-free(无锁)代码时至关重要。它确保了在多线程环境中,对共享数据的访问能够以一种预期的顺序发生,防止数据竞争和不一致的问题。
C++11引入了
<atomic>头文件,提供了原子操作(atomic operations)和对内存序的控制。内存序指定了读写操作相对于其他读写操作的顺序,并影响了它们的可见性。C++11定义了以下内存序:
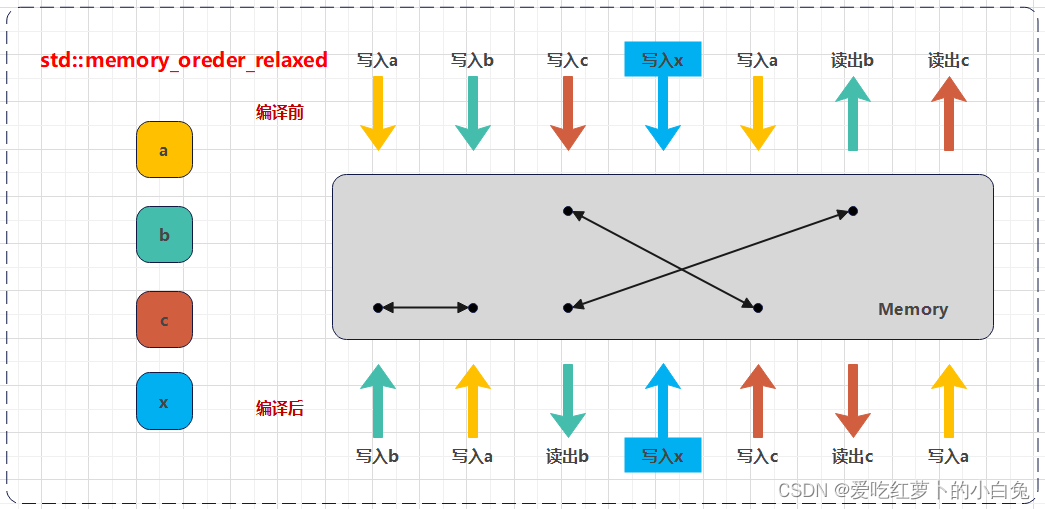
1)std::memory_order_relaxed:
- 最宽松的序。它不对其他内存操作施加任何顺序约束。
- 仅保证原子操作本身的原子性。
- 通常用于那些不需要与其他操作建立顺序关系的场景。
2)std::memory_order_consume: - 消费者-生产者模型中的“消费”序。
- 它保证了一个线程中的读操作(加载)能“看到”另一个线程中对应的写操作(存储)的结果。
- 但它并不保证其他所有线程都能看到这个写操作的结果。
- 在实践中,由于它的复杂性,很少被使用。
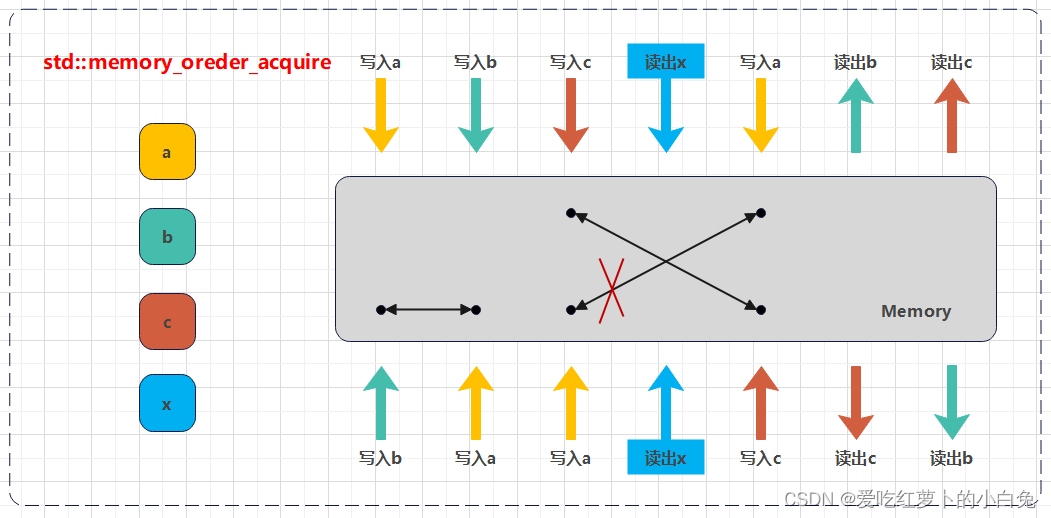
3)std::memory_order_acquire:
- 单向读,当前线程中读或写不能被重排到此读操作前。
- 常与互斥量(mutex)的解锁或其他形式的释放操作一起使用。
 4)std::memory_order_release:
4)std::memory_order_release: - 单向写,当前线程中读或写不能被重排到此写操作后。
- 常与互斥量的锁定或其他形式的获取操作一起使用。

5)std::memory_order_seq_cst(顺序一致性): - 最严格的序。它提供了单一的全局顺序,在这个顺序中,所有的读写操作都是按照它们被调用的顺序发生的。
- 这是C++中最常用的内存序,但也可能带来较高的开销。
- 当不确定应该使用哪种内存序时,它通常是一个安全的选择。
6)std::memory_order_acq_rel(获取/释放):
- 结合了
std::memory_order_acquire和std::memory_order_release的特性。 - 它通常用于读-修改-写操作,如原子加法或比较并交换(CAS)。
在选择适当的内存序时,需要考虑数据依赖关系、性能需求以及与其他同步原语的交互。错误的内存序可能导致数据竞争、死锁或其他并发问题。
2、内存序作用
内存序可以影响编译器和CPU的指令重排行为。编译器在优化代码时可能会重排指令,而CPU在执行指令时也可能会根据其内部架构进行重排。内存序规定了在这些情况下哪些指令不能被重排,从而保证了并发执行的正确性。
如何理解编译器与CPU指令重排?
编译器和CPU都通过指令重排来优化程序的执行,但它们的侧重点不同。编译器主要关注于代码的逻辑优化,而CPU则侧重于利用硬件特性来提高性能,主要区别在于它们发生的时间点和目的。
时间点:
- 编译器重排:发生在编译阶段,即源代码转换为机器码的过程中。
- CPU重排:发生在运行期,即程序在CPU上执行时。
目的:
- 编译器重排:旨在优化代码的执行效率,确保单线程程序语义不变。
- CPU重排:目的是提高指令的并行度和整体性能,利用硬件资源使多条指令能够重叠执行。
3、原子变量与内存序
对于原子类型上的每一种操作,都可以提供额外的参数,从枚举类
std::memory_order取值,用于设定所需的内存次序语义,下面是不同的原子操作可以使用的内存序
- 存储(store)操作:可选
std::memory_order_relaxed、std::memory_order_release或std::memory_order_seq_cst - 载入(load)操作:可选
std::memory_order_relaxed、std::memory_order_consume、std::memory_order_acquire或std::memory_order_seq_cst - 读-改-写(read-modify-write)操作:可选
std::memory_order_relaxed、std::memory_order_consume、std::memory_order_acquire、std::memory_order_release、std::memory_order_acq_rel或std::memory_order_seq_cst
原子操作默认使用的是
std::memory_order_seq_cst次序。
4、顺序模型
六种内存顺序相互组合可以实现三种顺序模型,如下:
Sequencial consistent ordering:实现同步, 且保证全局顺序一致 (single total order) 的模型. 是一致性最强的模型, 也是默认的顺序模型Acquire-release ordering:实现同步, 但不保证保证全局顺序一致的模型Relaxed ordering:不能实现同步, 只保证原子性的模型
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









