






点击蓝字⬆ 关注我们
本文共计3362字 预计阅读时长11分钟
在数字化转型的浪潮下,企业对数据价值的依赖日益加深,而数据质量的可靠性和管理效率直接决定了企业能否从数据中获取有效洞察。腾讯云WeData作为深度聚焦数据治理的智能平台,以“三层解耦架构”为核心,重塑了数据质量监控体系。本文将结合实际经验,聊聊背后的技术逻辑和产品设计思路。
01
数据质量的战略价值:
从成本中心到决策引擎
过去大家常把数据治理当作“成本负担”,但现在,高质量数据已经成为支撑业务决策智能化的核心资产。Gartner的研究指出,企业和机构因数据质量问题导致的直接经济损失每年平均高达1290万美元。现实案例也不少,比如今年某支付软件,因为缺乏有效的数据质量监控,未能及时发现异常交易额波动,结果导致上亿损失,还影响了企业声誉。
腾讯云WeData希望通过先进的数据质量治理体系,实现从被动防御到主动保护的转变,成为企业增长的“隐形护盾”。
02
数据质量的深层挑战
数据质量始终是企业面临的棘手问题。在腾讯云WeData的实践中,我们发现了几个典型挑战:
隐形规则vs显性规则:合规,但是合理吗?
数据质量不仅仅是简单的规则判定,更需要适配具体的业务场景。传统工具擅长基础规则校验(如字段非空、格式合规),但对业务语义的深度检测能力有限。例如用户年龄字段虽符合正数要求,但市场活动中出现60岁以上高净值人群异常聚集。这种异常靠简单的阈值或空值规则是识别不了的。
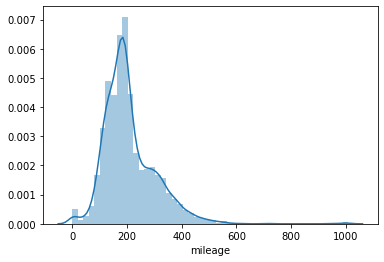
这种数据从全局质量角度来说,真的没问题吗?
静态阈值vs动态阈值:BAU和关键大促能用一套质量阈值吗?
其次,静态阈值管理跟不上业务动态变化。硬编码的规则就像“刻舟求剑”,面对流量波动、业务周期等常态变化,固定阈值的质量规则经常会导致误报。比如大促期间订单量周环比波动300%其实很正常,但如果还用5%的静态阈值,误报就会一大堆。说到底,是系统缺乏时序特征的自动学习能力,没法区分正常波动和真正的异常。
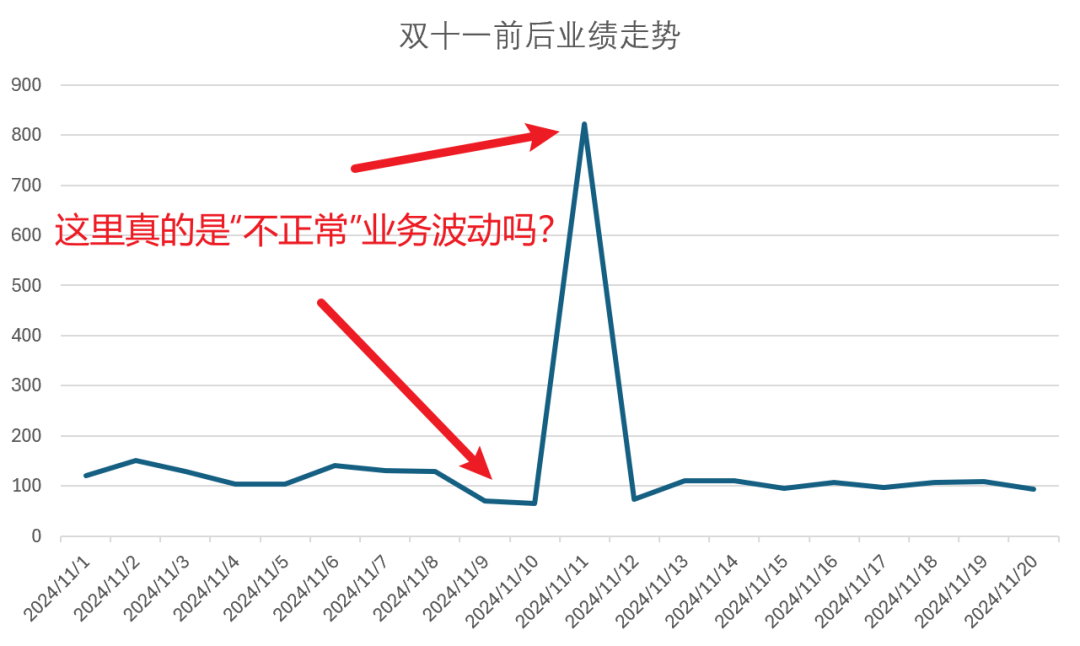
对于业务主动引发的指标波动,是否达成了期望目标才是最关键的判断标准,而不是绝对值大小。比如在上面图中,在双十一前后,销量的下降真的是异常吗?双十一时期的销量暴增真的需要触发告警嘛?更合理的做法应该是和上一次对应的大促对比,这样的预期才更合理。
单点检测vs对比检测:业务库应该是什么样的?
还有,治理链路上经常有断点。跨源数据一致性检测的缺失会加剧质量风险。现在很多数据治理体系都缺乏对多源异构数据的统一校验能力,导致核心业务指标很难实现跨系统实时比对。比如CRM系统的销售订单金额和财务业务库的结算金额,通过自动化工具很难动态捕捉字段级的差异(比如ETL管道中汇率转换的误差等)。缺乏关联分析,数据质量问题就容易长期潜伏,最后引发决策误判。
解决方案:
其实这些问题在业界都很常见,但传统质量工具很难覆盖到。表面上看,每个问题都有解决方案:
第一个问题,数据科学里常做探查性分析,看看字段空值率、枚举值分布等,再做处理;
第二个问题,只要数据量够大,传统机器学习模型也能判断阈值的周期性并给出推荐;
第三个问题更简单,分别跑两个SQL任务提取不同系统的指标,对照一下就行了。
但为什么传统的数据质量工具还是很难覆盖这些场景?
关键在于,怎么把这些能力集成到一个产品里,怎么帮用户快速批量实现这些能力。主流方案往往是底层计算和上层告警一体化,用户用起来确实方便——创建任务、挂规则、配阈值、设告警对象,任务跑完了,空值率、波动率规则都通过了,结果质量隐患还是一堆。
这其实不能怪用户。用户很难在彻查数据之前就配出真正有效的质量规则,否则就是“盲配”。但如果能彻查数据,可能也不需要传统质量工具了,顺手解决岂不是更简单?这种工具只能帮我们解决“known unknown”,也就是用户预先知道哪里可能有问题,才会去配质量监控。但在真实业务里,用户怎么知道哪里会出问题?等出问题再补救,质量工具的意义又在哪里?
03
解耦式的架构?
针对上述挑战,腾讯云WeData提出计算层、判定层、治理层的三层解耦架构,实现精细化、智能化的数据质量治理。
三层解耦架构把质量指标计算、异常阈值判定、告警策略拆开,每一层都能独立扩展能力。这样一拆三,最大的好处就是能各司其职,互不影响,可以各自做到极致,同时也更容易复用。
计算层的输入是主数据,输出是质检指标,重点在于怎么高效、低成本地计算指标;
判定层的输入是质检指标,输出是数据问题,关键是提升判定的准确率和召回率;
治理层的输入是数据问题,输出是问题处理,关注的是更人性化的通知策略和更定制化的处理方式。
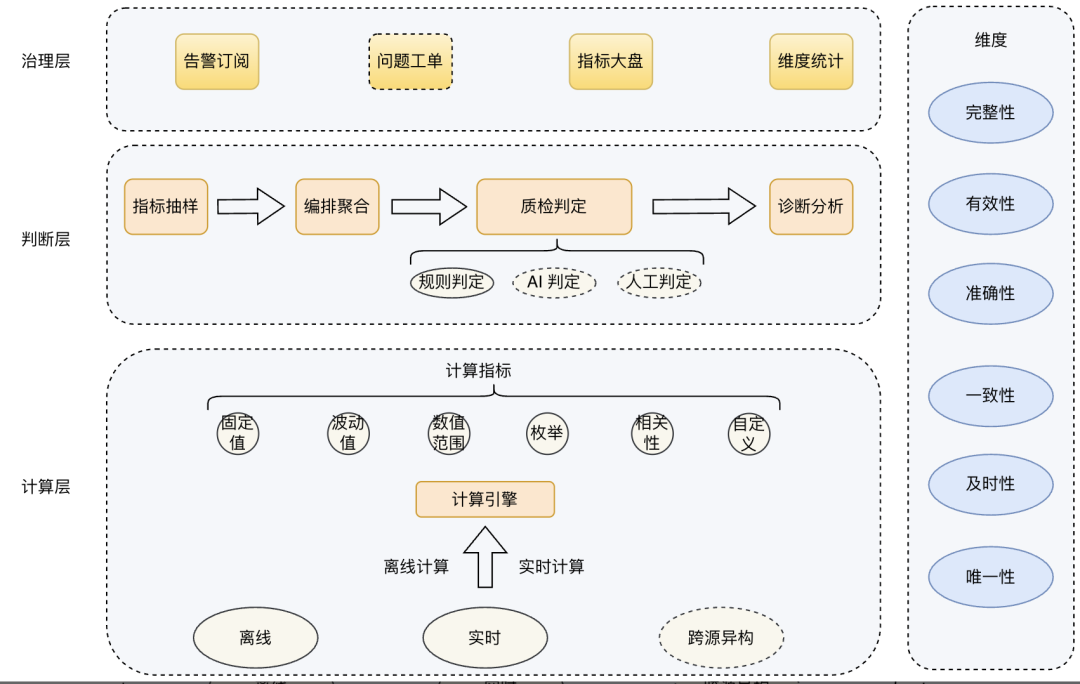
乍一看,好像把简单的质量规则检验搞复杂了,但其实这种架构让用户可以有选择地复用各层能力,针对自己的业务场景定制需要的质量方案。
我们可以具体看看每一层:
1.计算层
计算层的核心目标就是把所有数据资产转化为统一的质检指标,同时要平衡计算成本和指标可靠性。
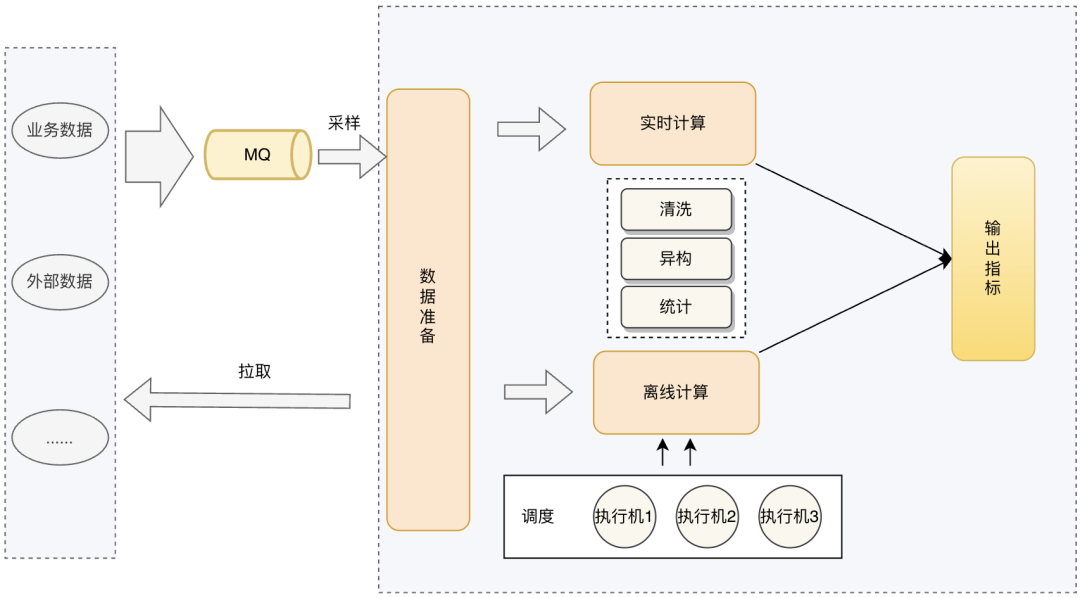
这里实时计算和离线质量校验的区别就不赘述了。实时能保证检测实时性,减少质量问题的影响,但是只能检测单条数据,无法计算统计式的质量指标。离线的计算则相反。这里需要大家根据自己的业务场景选择。
这里主要是两个重点:
一是抽样。在大数据场景下,直接聚合全量数据去算统计指标,资源消耗太大。可以引入抽样,让用户确定能接受的置信度,然后计算需要的样本数,抽出来的数据可以存成新的样本库,后续的质量审查都基于这个样本库来做。
我们在腾讯内部的早期实践中,抽样最初只是个可选项,但后来发现,在大数据场景下,质检计算反复从海量数据里捞一小段,资源浪费太明显,降本增效压力下很难持续。
抽样方式也很重要。同样是1%的样本,按行抽和按列抽,结果可能差很多。比如对订单信息表做质量检测,第一种方式是从1万行数据里抽100行完整数据,针对这100行提取质量指标;第二种方式是全随机抽样,每个字段独立抽100条数据来算指标。在我们的实践中,第一种方式在大多数质检指标计算上表现更好,但在数据极度倾斜的场景下,可能还得用全随机抽样。
二是任务编排和合并。就是怎么把质检指标的计算方式做优化,比如把一张表所有字段的空值、均值、长度等合并计算,一次SQL就能搞定。或者通过优化SQL查询策略,用临时表存放中间结果,后续再做资源消耗大的group by计算。
指标算出来之后,就可以进入下一层了。
2.判定层
判定层的解耦,主要是给用户更大的灵活度去定制判定逻辑。这里主要做质量问题的判定和分类,什么情况算质量问题,什么情况是严重影响生产的质量问题,都可以灵活配置。
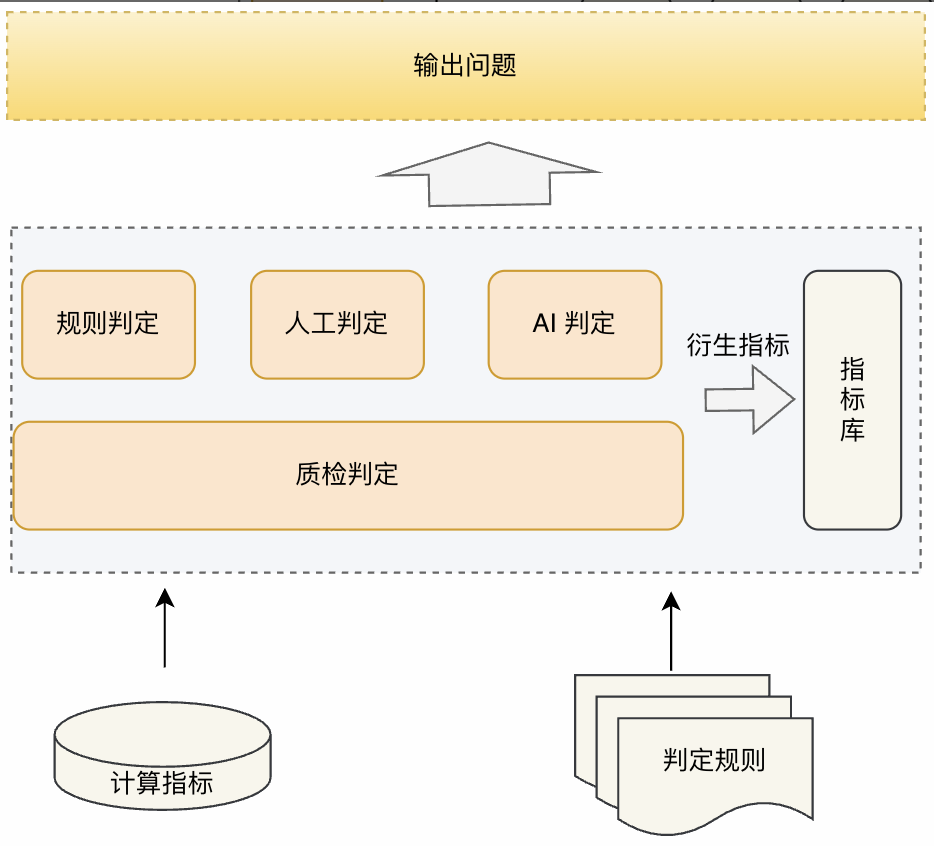
这里有个核心支撑——质量指标库。指标库其实就是个时序库,计算层会按用户配置的调度,定时把各时段的指标存进去。这个指标库是整个架构的核心,也是后续各种应用的基础。
有了这些指标,判定方式其实可以很丰富,主要有三种:人工判定、规则判定和AI判定。
人工判定其实就是最基础的数据探索性分析,比如在数据作业前先瞅一眼基础数据探查,虽然不能覆盖所有“unknown unknown”的质量问题,但用户大致能对数据有个感知,凭经验判断哪里有问题、怎么处理。
规则判定是最常见的,主流质量工具基本都是靠规则判定,让用户填阈值,自动分类和判断质量问题。有了指标库后,像跨数据源比对这种场景也变得简单,比如业务库到数仓的ETL管道后,关键字段比对一下指标就能知道有没有丢数据。
AI判定则是为了解决人工判定太耗精力、规则判定太死板的问题。比如动态阈值,就是用时序机器学习模型在指标库上训练,通过统计手段推荐下次校验指标的合理区间和置信度。随着指标库样本的积累,推荐精度会越来越高,有足够的质量指标甚至能识别数据的周期性,解决大促期间销量表和日常表的异常阈值不一样的问题。
False Positive还是False Negative?
这里还有个要点,数据开发经常会遇到大量告警信息,不论是False Positive(告警,但不是真正的问题)还是False Negative(不告警,但是是真正的问题),需要花很多精力判断告警的有效性。
这两种告警都很烦人,但在我们前置一系列手段下,False Negative会相对减少很多。我们推荐可以稍微提高一些告警的置信度,只有到了一定程度才会告警,让每一次告警都尽量真实有效。不然无效的告警多了之后,后续的告警大概率只会在垃圾邮件箱里吃灰了。
围绕指标库,其实还能衍生出很多应用场景,比如AI模型的问题溯源。线上模型预测精度有问题时,可以通过血缘能力溯源到推理表,再到对应的质量指标库,看看时序指标有没有明显变化,是数据管道问题还是模型本身问题,排查起来更高效。
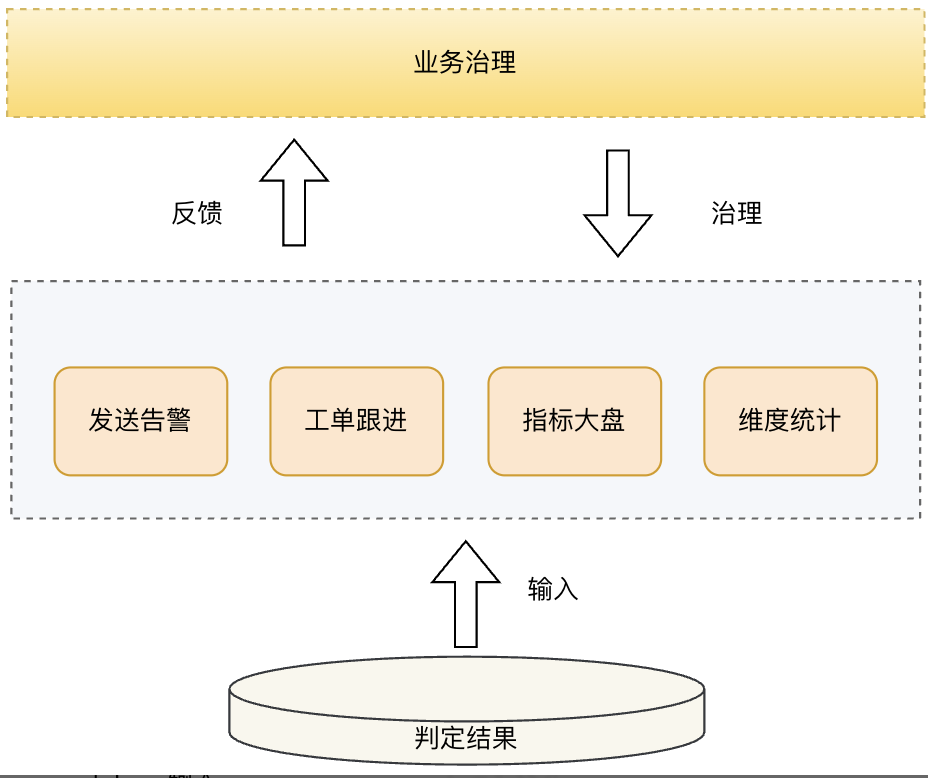
3.治理层
治理层就更贴近用户实际业务场景了。比如对不同严重程度的告警做不同处理,轻微的集中起来定时通知,严重的立即通知,特别严重的则可以在通知用户的同时自动阻断下游管道,保障业务安全。
04
结语
数据质量治理没有终点,而是随着企业数据增长不断演化的过程。随着企业数据规模和复杂度的持续提升,传统的“一刀切”式质量监控已经难以满足业务的多样化和精细化需求。我们在腾讯云WeData的实践中体会到,只有通过架构的解耦和能力的灵活组合,才能真正让数据质量治理变得高效、智能、可持续。
未来,我们也希望和更多行业伙伴一起,持续探索数据治理的新边界,让数据真正成为企业创新和增长的坚实底座。
腾讯云大数据始终致力于为各行业客户提供轻快、易用,智能的大数据平台。
END
关注腾讯云大数据╳探索数据的无限可能

⏬点击阅读原文
了解更多产品详情

分享给认识的人吧



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









