







01/前言
Canva 是一款全球领先的在线设计工具,致力于让用户实现各类创意设计、编辑与发布。
Canva 的大部分生产工作负载都运行在 AWS 之上,核心服务包括 Amazon S3 、Amazon ECS 、Amazon RDS 以及 Amazon DynamoDB NoSQL。
过去十年间,在 AWS 的支持下, Canva 能够敏捷应对用户规模的迅猛增长——自 2013 年上线以来,月活跃用户已从零起步成长为每月超过 1 亿活跃用户的平台,累计创作了超过 150 亿个设计!
如今,Canva 的用户遍布 190 个国家和地区,并得益于国际化团队的出色本地化工作,支持 100 多种语言的设计。
在 Canva 平台上,用户通常从模板开始创作,创作者能够方便快捷地从我们精心维护的素材库中选择图像、图形、动画及视频元素,这其中包含超过 7,500 万张高质量的图片素材。
然而,与我们存储的全部内容相比,这个数字只是冰山一角——因为 Canva 允许每个品牌创建并发布自己的专属模板、媒体素材等内容,由此产生的海量用户生成内容(UGC)正是我们存储系统需要承载的关键。
Amazon S3 提供了一种可靠、耐用且低成本的存储解决方案。
针对不同访问模式和工作负载,Amazon S3 设计了多种存储类别。理解这些 S3 存储类别之间的差异对于实现高效成本管理的弹性伸缩至关重要。
在 Canva 的生产环境中,我们在 Amazon S3 中存储了超过 230 PB 的数据,其中最大的单个存储桶达到了惊人的 45 PB!
在本文中,我们将深入探讨如何对这些海量数据进行可视化管理,以及将大量数据迁移到 Amazon S3 Glacier Instant Retrieval 是如何满足我们的使用场景并每年节省数百万美元的。
02/Amazon S3 存储类别
根据工作负载的数据访问、弹性和成本需求,Amazon S3 提供了多种不同的存储类别可供选择,如下图所示:
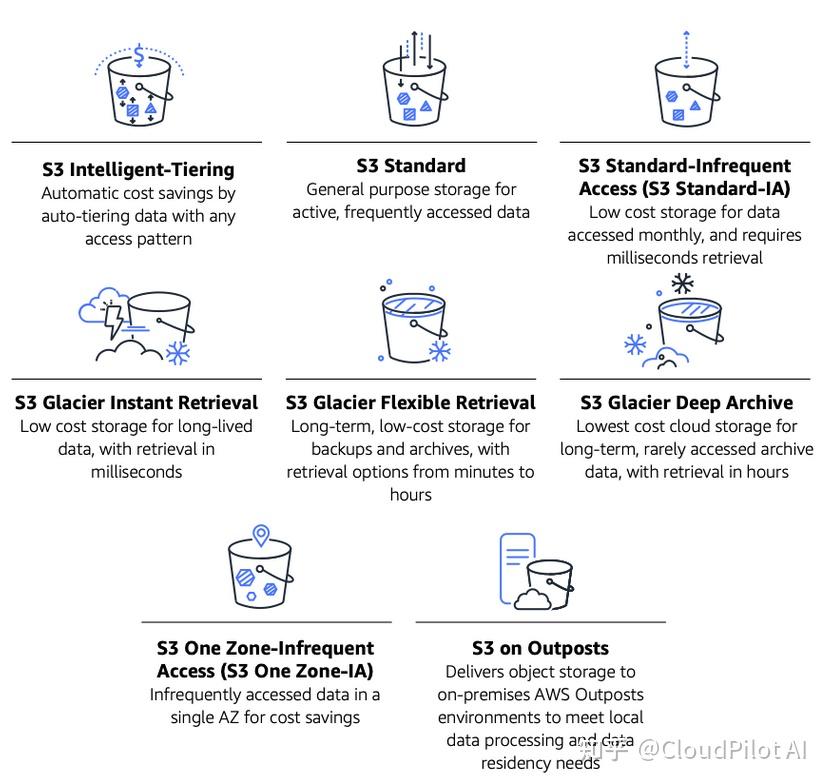
对于 Canva 的常用模板库、图片库,S3 Standard 存储类别最适合我们。许多用户每天频繁访问这些内容,因此将其保留在针对频繁访问优化的存储类别中效果最佳。
相比之下,用户个人的设计及其上传的图像和媒体往往只会在短时间内被访问。用户使用 Canva 创建设计、进行演示或完成打印之后,通常也很少会再次查看草稿。
对于这类内容,我们过去一直使用 S3 Standard-不频繁访问(S3 Standard-IA)存储类别,因为它在提供快速检索的同时比 S3 Standard 更具成本效益。
对于某些特定用途,我们还使用 S3 Glacier Flexible Retrieval 进行灵活检索,该存储类别适用于可以在几分钟到几小时内检索的数据。
对于日志归档和备份这些通常很少需要访问的数据,这种访问时间是可以接受的。但对于需要频繁访问的用户生成内容,S3 Glacier Flexible Retrieval 便不太适用。
AWS 在 2021 年 11 月推出的 S3 Glacier Instant Retrieval ,为不频繁访问的数据提供了两全其美的解决方案:低成本归档存储和毫秒级快速检索。
这促使我们开始思考:
如果将不常访问的数据迁移到 S3 Glacier Instant Retrieval ,我们能节省多少成本?哪些存储桶应该迁移?
03/理解业务场景的数据
虽然我们知道用户生成的内容通常在创建后就很快被访问,但我们并不完全确定其具体的访问模式。
过去,我们曾使用 S3 生命周期策略 ( Lifecycle Policies ),在 30 天后将数据从 S3 Standard 转移到S3 Standard-IA,但无法详细分析该策略的节省情况。
AWS 新推出的 S3 Storage Class Analysis 工具为我们提供了深入了解数据访问模式的机会,该功能支持单个存储桶级别开启,同时能够生成多个可供分析的图表。
下图显示了 S3 Standard 存储的数据存储量和访问率(按数据创建时间划分)。
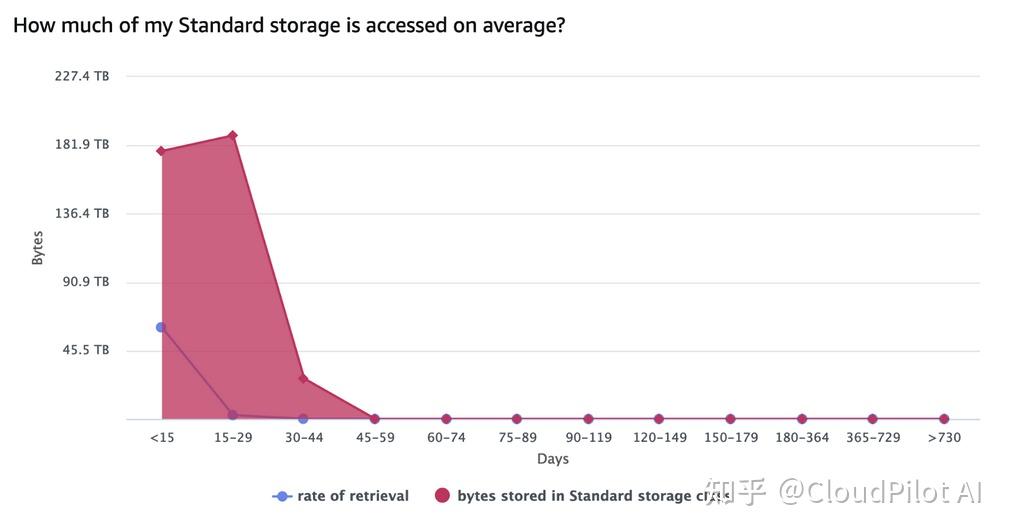
可以看到,总存储量在 30 天后急剧下降,这是由于生命周期策略的影响。同时,访问频率在 15 天后也大幅下降,这与我们之前提到的预期访问模式一致。
下图显示的是 S3 Standard-IA 存储的数据访问模式。
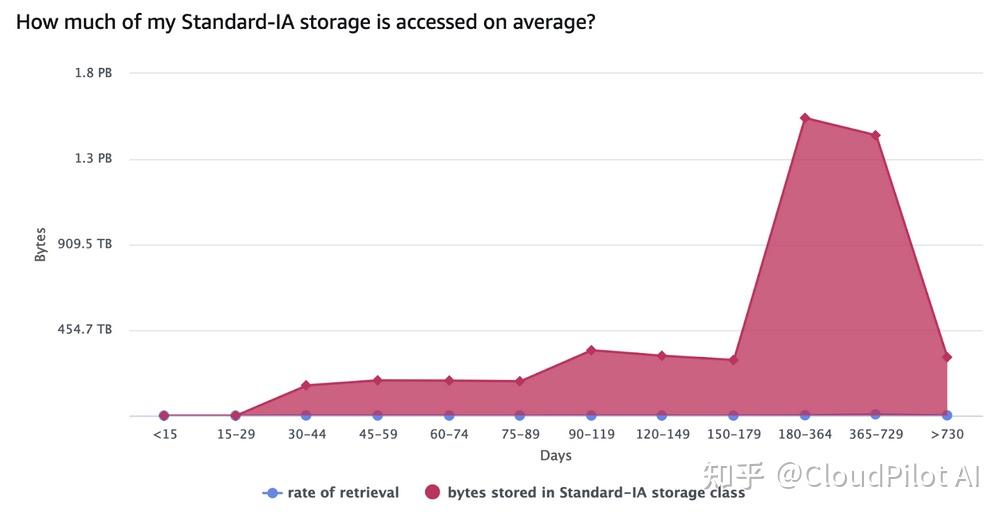
存储的数据量看起来有些奇怪,但仔细观察代表天数的 X 轴,你会发现时间间隔在逐渐变长(前 15 天、30 天、180 天、365 天)。
如果将这个图表调整为均匀的时间间隔,你会发现它与 Canva 用户增长曲线十分相似。值得注意的是,数据访问率在所有时间段内都相当稳定。
最终,我们分析了存储桶中每个存储类别中被访问的数据总量。
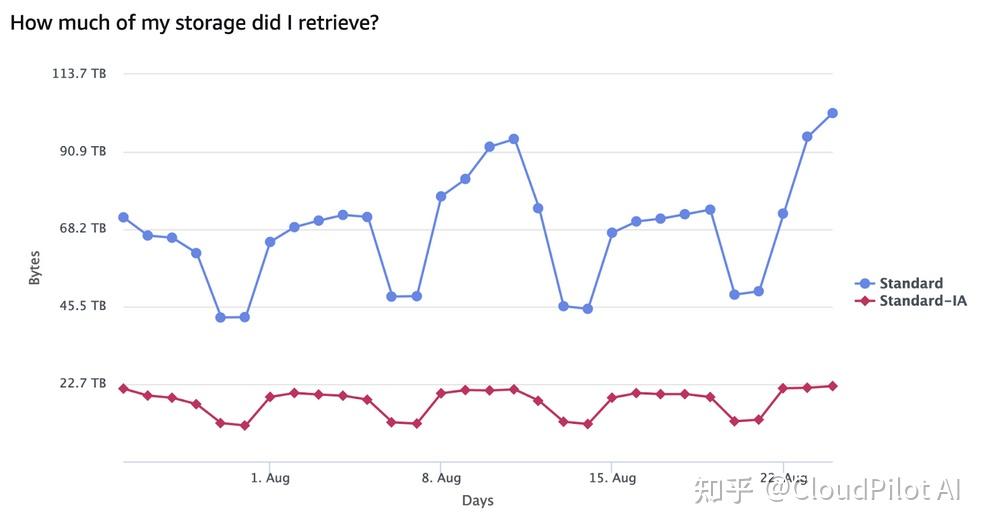
在这个特定存储桶中,约 10% 的总数据存储在 S3 Standard 中,而 90% 存储在 S3 Standard-IA 中。
图表显示,60-70% 的被访问数据来自 S3 Standard,30-40%来自 S3 Standard-IA。
这与 S3 存储类别的定价模型非常吻合:
- S3 Standard 的每 GB 存储成本较高,但数据访问成本非常低;
- S3 Standard-IA 和 S3 Glacier Instant Retrieval 的每 GB 存储成本较低,但数据访问成本较高。
这种数据访问模式在我们用于存储用户生成内容的许多存储桶中都很常见。所以,我们是不是只需添加一个生命周期策略,将所有内容转移到 S3 Glacier Instant Retrieval,就万事大吉了呢?
就像软件开发中的许多问题一样,答案是——视情况而定。
04/迁移成本与回本周期
在 S3 存储类别之间迁移对象时,每次请求都会产生费用。
例如,将对象迁移到 S3 Glacier Instant Retrieval 的成本为每 1,000 个对象 0.02 美元。
然而,Canva 的 S3 inventory 中包含超过 3,000 亿个对象,如果不加考虑地直接迁移所有对象,成本将超过 600 万美元!
这再次说明了存储成本可视化以及深入理解数据存储情况的重要性。
有趣的是,这种迁移成本取决于移动的对象数量,而 S3 Glacier Instant Retrieval 带来的潜在节省则主要取决于存储的数据总量。
此外,迁移所有数据的成本是一次性费用,而更便宜存储类别带来的节省是持续性的。
这意味着我们可以根据存储桶中对象的平均大小,计算从 S3 Standard 迁移到 S3 Glacier Instant Retrieval 达到收支平衡所需的大致时间。
例如,如果需要迁移少量非常大的对象,回报会很快实现。相反,迁移大量小对象可能需要数月才能达到收支平衡。
我们对 S3 Standard-IA 也做了同样的分析,因为我们已经在该存储类别中存储了大量数据以降低成本。
因此,我们需要先计算迁移的回本周期,并选择最优的迁移策略。
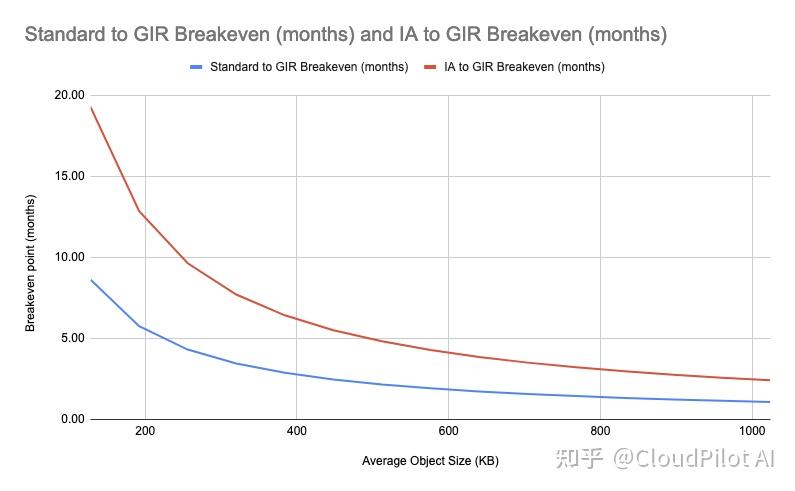
该图表的 X 轴 从左侧的 128 KB 开始,这是因为 S3 Standard-IA 和 S3 Glacier Instant Retrieval 的最小计费对象大小为 128 KB(即对象小于 128 KB,仍按 128 KB 计费)。
因此,当对象大小低于 128 KB 时,从 S3 Standard-IA 迁移到 S3 Glacier Instant Retrieval 的回本时间是恒定的,因为所有对象都会按 128 KB 计费。
你可以在下方的图表中看到这一点:
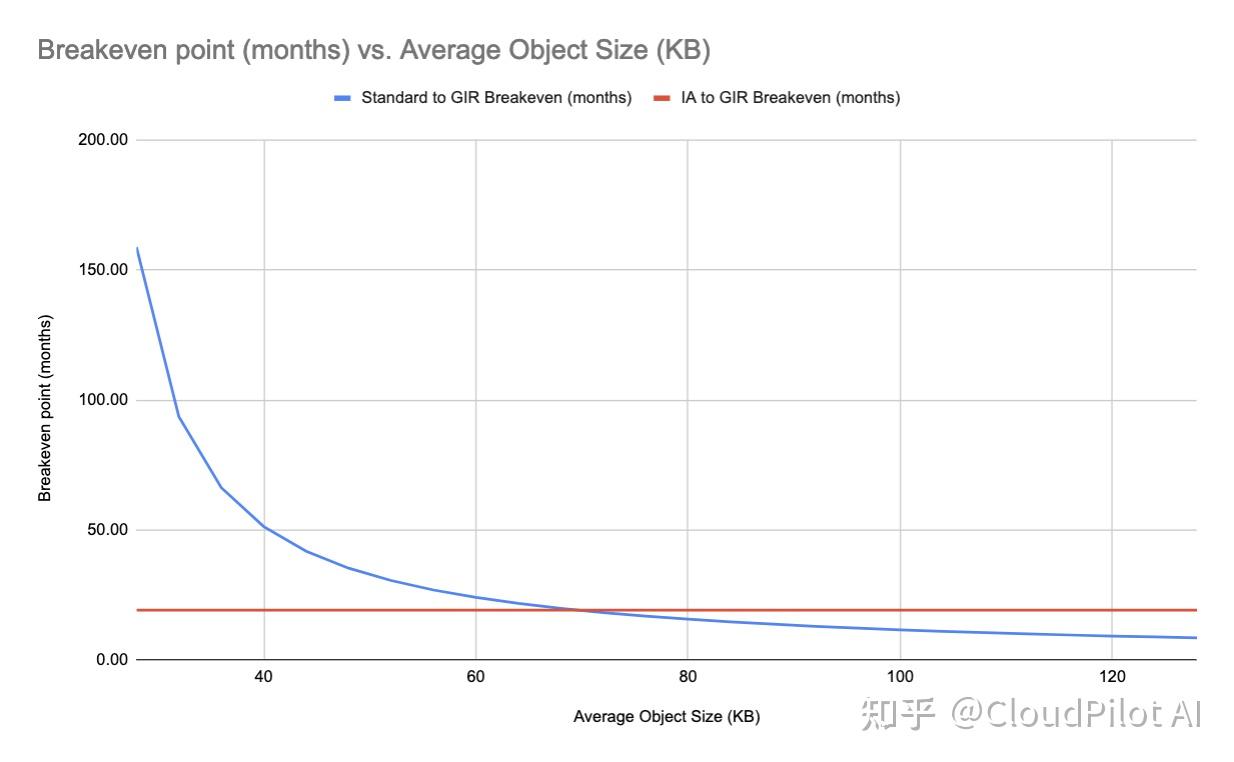
这张图表探讨了小于 128 KB 的对象的回本点。
需要再次强调,S3 Standard-IA 和 S3 Glacier Instant Retrieval 中的对象始终按 128 KB 计费。因此,当对象大小在约 20 KB 时,存储在 S3 Standard 反而比存储在 S3 Standard-IA 或 S3 Glacier Instant Retrieval 更具成本效益。
关键结论
在平均对象较大的存储桶中,将数据从 S3 Standard-IA 迁移到 S3 Glacier Instant Retrieval 能更快实现收支平衡。
基于这一分析,我们决定首先针对平均对象大小为 400 KB或更大的存储桶(具有前文提到的适当使用模式),因为这些存储桶将在 6 个月或更短时间内显示正投资回报。
05/总结
关于这次迁移工作,其实没有太多可写的——对工程师而言,这无疑是梦寐以求的理想迁移情况!
我们仅需为每个存储桶应用生命周期策略,就在大约两天内快速迁移了近 800 亿个对象。
截至本文撰写时,Canva 在 S3 中共存储的 230 PB 数据中,约有 130 PB 位于 S3 Glacier Instant Retrieval 中。
事实证明,这是一种极具价值的工具,它能有效降低我们对不常访问的用户数据的存储成本,同时兼具 S3 Standard-IA 和 S3 Glacier Flexible Retrieval 的优点。
由于这些优化,Canva 能够每月节省约 30 万美元(每年 360 万美元)。随着我们存储的用户生成内容不断增长,这些节省还将持续增加。
然而,值得注意的是,这些节省并非凭空得来,我们首先需要深入理解数据的访问模式,并且承担了一次性 160 万美元的迁移成本(覆盖 800 亿个对象的迁移费用)。
但总的来说,我们短短几个月内就实现了正向投资回报(ROI),这依然是非常了不起的成果!
在整个过程中,AWS 一直是 Canva 的重要合作伙伴,持续投资于适用于各种规模业务的存储类别,帮助客户优化存储成本和效率。
如果你正在寻找优化存储成本的最佳实践,关注「CloudPilot AI 」,我们将持续带来各企业成本优化的优秀实践案例
推荐阅读
流量翻倍,但成本降低86%!「芝麻街」制作方PBS的俭约架构实践
美国版“大众点评”的 Karpenter 迁移实践:如何让每一分钱的效益提升25%?
kOps + Karpenter 集成实践:实现 K8s 集群的动态扩展


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









