






实验目的:
通过实验,使学生掌握利用 SIMNOMERGE余弦相似度计算文档得分的算法。
实验内容:
XML由于文档包含非常复杂的树形结构,属性之间还存在嵌套关系,属性数目也高于参数化搜索和域搜索,因此检索更为复杂。基于向量空间模型的XML搜索中,为更好地提高检索正确率,需要利用SIMNOMERGE余弦相似度计算文档得分
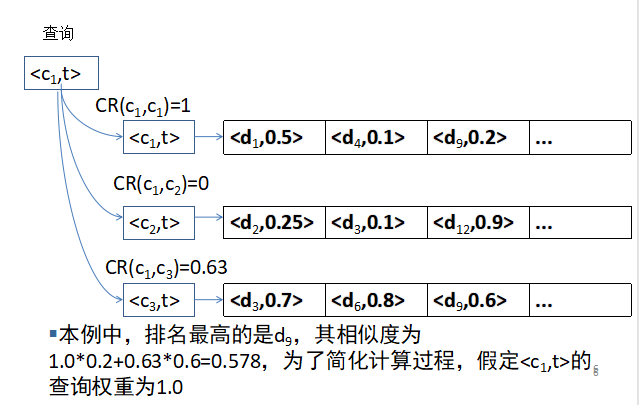
实验要求:
输入:上下文c1,c2,c3与c1的匹配结果CR ,即CR(c1,c1),CR(c1,c2),CR(c1,c3)词项,以及词项t在各文档中的倒排记录表。
输出:每个文档的相似度得分
编程语言:python

num=1
d=[]
dt_w={}
CR={}
while 1:
dt=input("请输入词项t在文档C{}中的倒排记录表(用,隔开):".format(num)).replace(" ",'').split(',')
w=list(map(float,input("请输入相应的权重(用,隔开):").replace(" ",'').split(',')))
d+=dt
if len(w)==len(w):
C=eval(input("请输入文档C{}与查询的上下文相似度:".format(num)))
dt_w[num]=dict(zip(dt,w))
CR[num]=C
num+=1
else:
print("输入有误!",end = '')
flag = input('要继续输入吗[y/n]:')
if flag == 'n':
break
d=set(d)
score={}
for i in d:
for j in CR.keys():
if i in dt_w[j].keys():
score[i]=round(score.get(i,0)+dt_w[j][i]*CR[j],3)
print("相似度得分:",score
程序运行结果如图所示:
















 2484
2484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









