







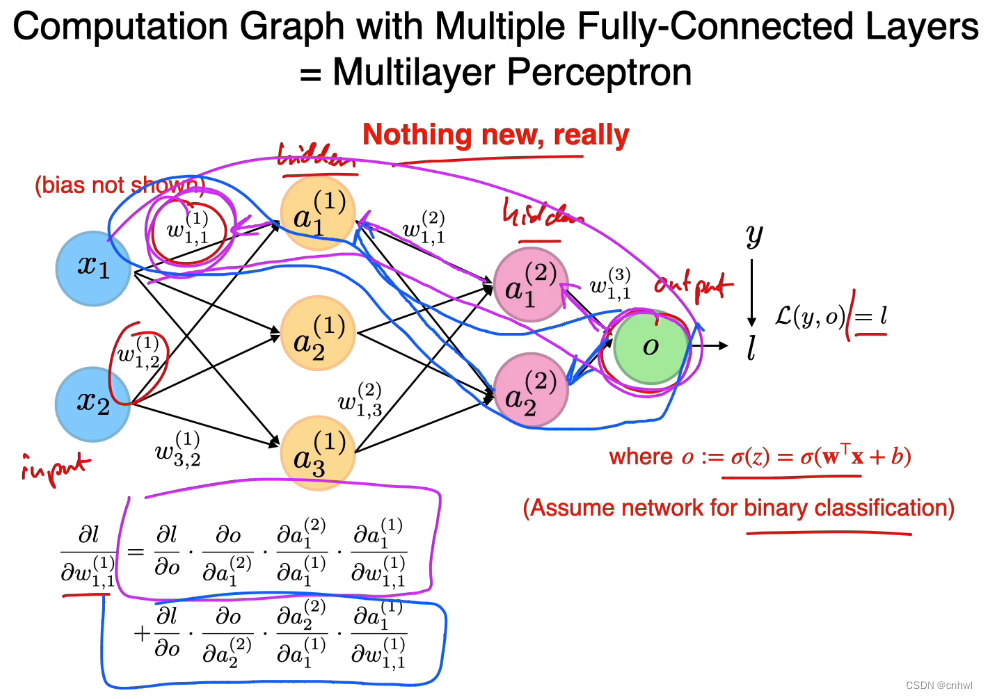
所谓多层感知器,其实就是具有一个或多个隐藏层(hidden layer)的全连接前馈神经网络,如图所示,在最重要的求取损失关于权重的偏导数的过程上,跟之前的 Logistic Regression 和 Softmax Regression 一样,仍然是使用链式法则进行求导。
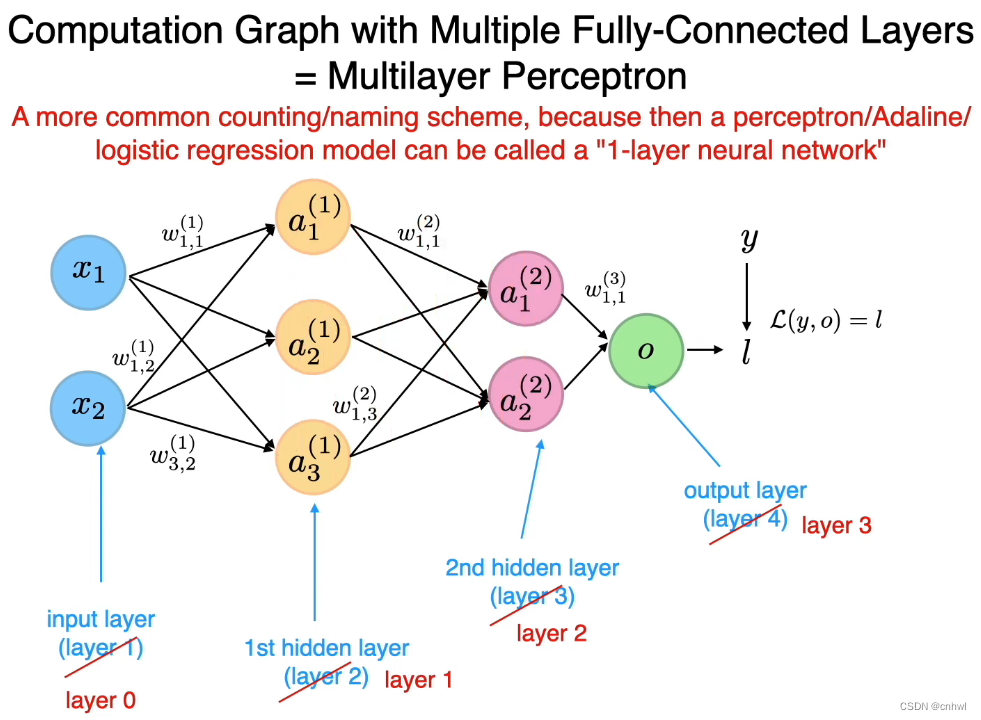
为了将感知器、Logistic Regression 和 Adaline 看作是单层神经网络,习惯上,我们把输入层作为第 0 层,把第一个隐藏层作为第 1 层,以此类推。在符号上也是如此,
a
2
(
1
)
a_2^{(1)}
a2(1) 表示第 1 层的第 2 个神经元,即第一个隐藏层的第 2 个神经元。
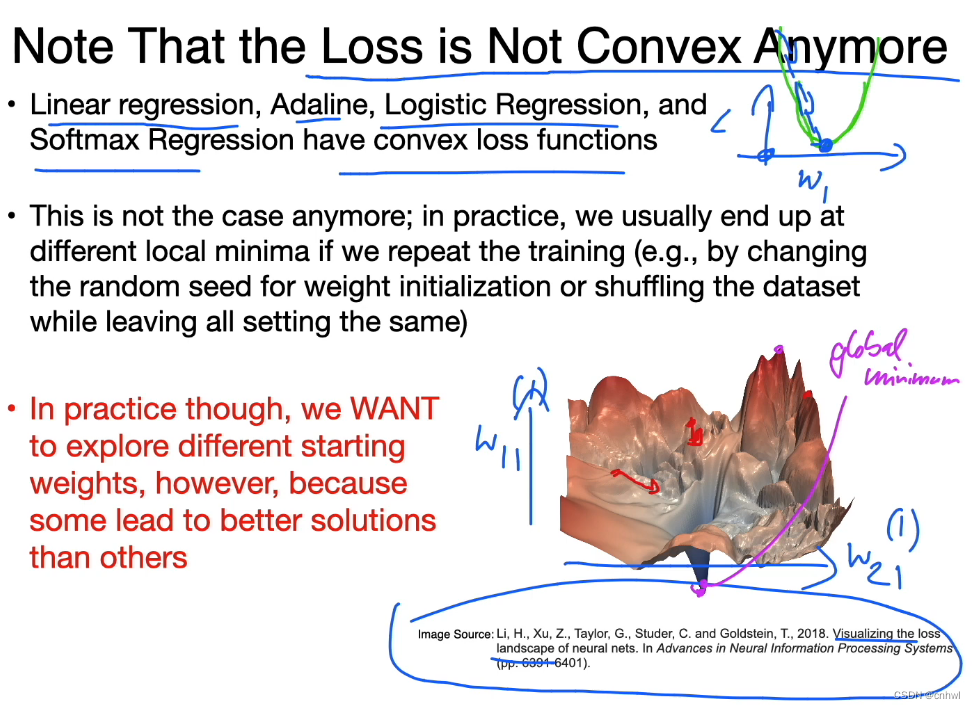
单层神经网络模型的损失函数是凸函数,而在多层神经网络模型下就不是了,凸函数会存在很多的局部极小值点,所以需要进行多次不同的权重初始化,以防止损失陷入局部极小值点。

Sigmoid 激活函数 + MSE 损失函数的组合虽然在形式上很好(Sigmoid 函数的导数抵消了负对数似然函数导数的分母),但是 Sigmoid 函数
σ
(
z
)
\sigma (z)
σ(z) 当输入 z 很小时,其输出也会很小,这就造成了梯度消失的问题。
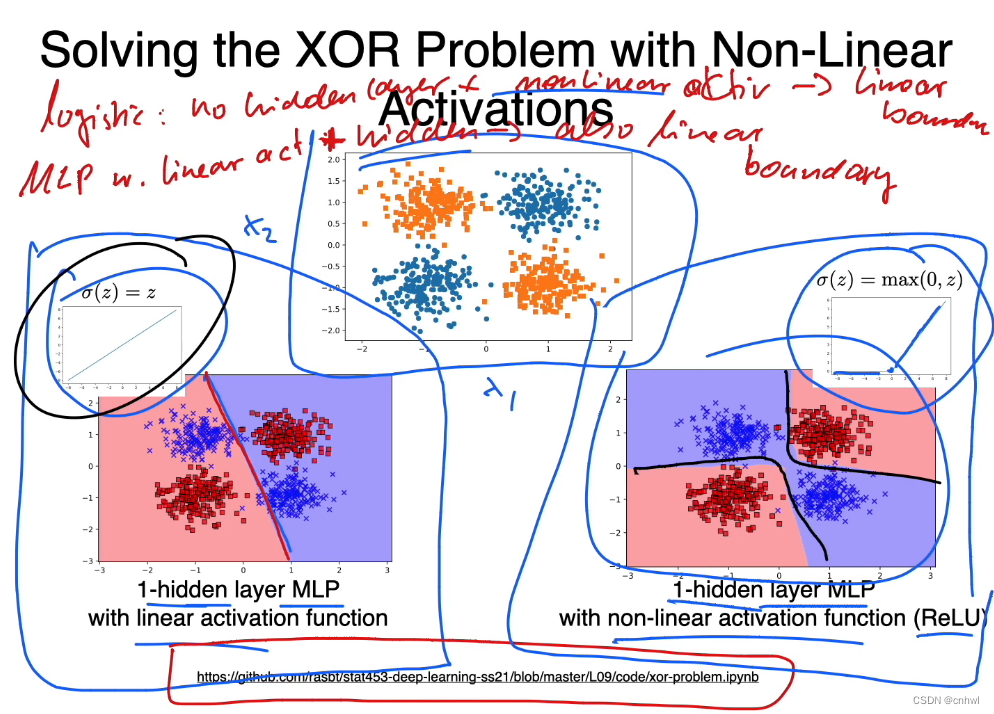
但是,在 MLP 中,只有隐藏层还不够,还需要加上非线性的激活函数,才能解决异或问题。Logistic Regression 是无隐藏层 + 非线性激活函数,线性 MLP 是有隐藏层 + 线性激活函数,它们都是只能产生线性决策边界的。
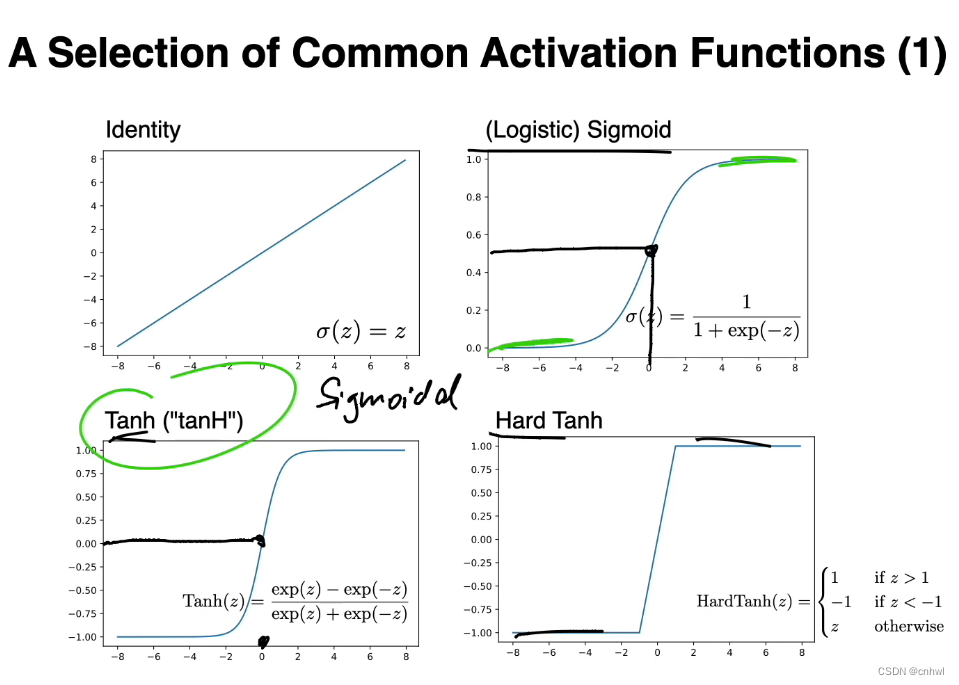
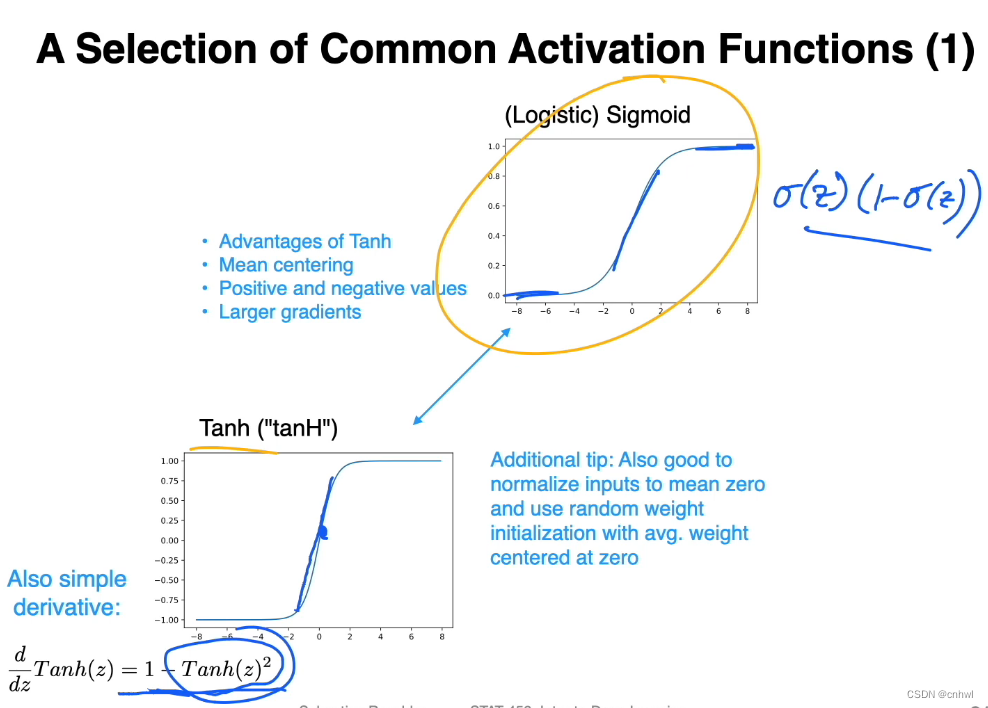
在非线性激活函数中,Sigmoid 和 Tanh(及其变种)都是 S 型曲线,而 Tanh 与 Sigmoid 相比,优势在于其过零点、零点附近的曲线更陡峭(梯度大)、可以同时产生正负值(避免了梯度消失)
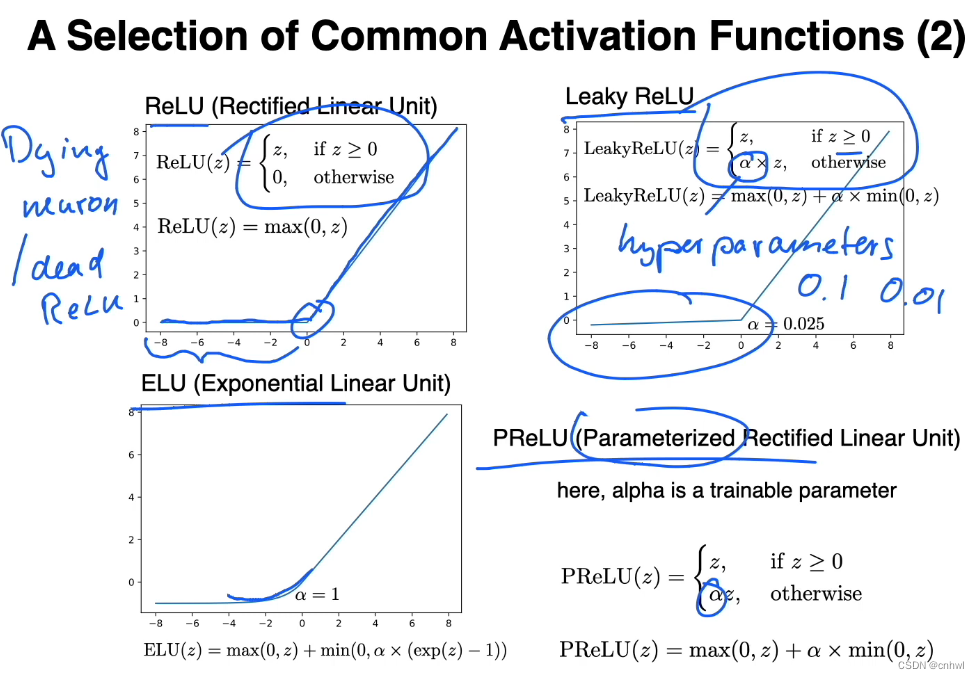

ReLU 及其变种,当 ReLU 函数的输入小于 0 时,斜率也为 0,相当于神经元“死亡”,如果太多神经元“死亡”就会影响训练,但也可以看作是一种剪枝或者正则化方法(避免过拟合)。Leaky ReLU 的 α 是超参数,需要人为设定;而PReLU 中的 α 是通过训练得到的。
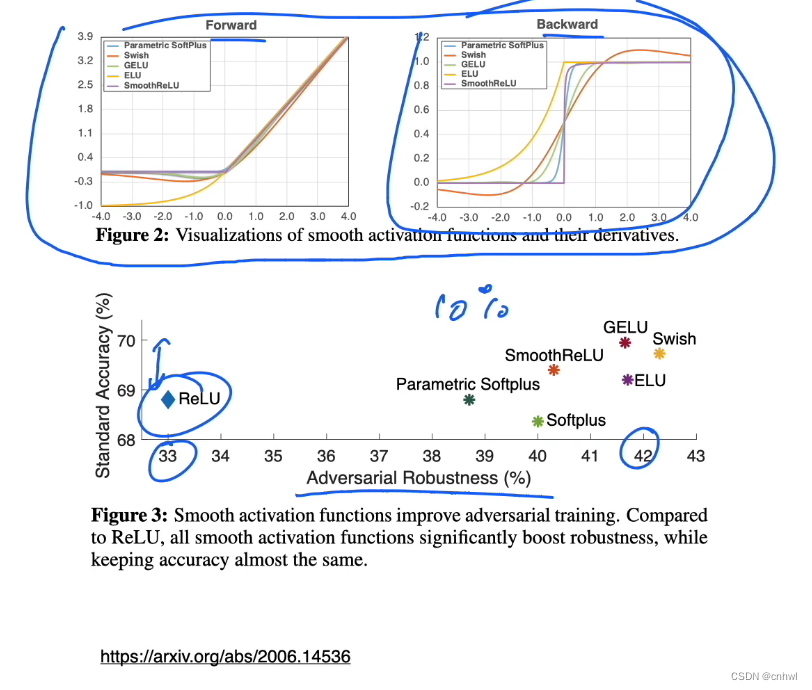
在 Smooth Adversarial Training 这篇论文中,作者比较了不同激活函数的性能与鲁棒性。
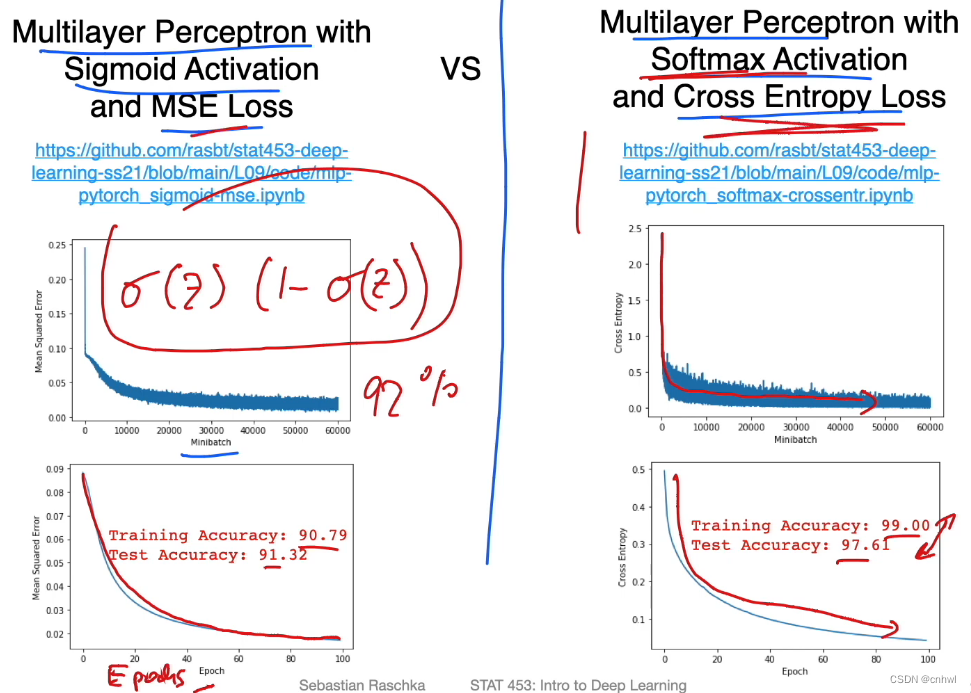
代码示例 1 是 Sigmoid + 均方损失,代码示例 2 是 Softmax + 交叉熵损失,后者的性能更好,可能是因为前面提到过的,Sigmoid + MSE 的组合会留下
σ
(
z
)
(
1
−
σ
(
z
)
)
\sigma (z) (1 - \sigma (z))
σ(z)(1−σ(z)) ,这是两个小数的乘积,值会越来越小导致梯度消失。


虽然已经有论文证明单层神经网络可以逼近任意函数,但不代表它是可行的。使用深度学习而不是宽度学习,好处是能用更少的神经元(参数)得到相同的学习能力,而后面的层受到前面层的限制,也可以避免过拟合,但是层数多会造成梯度消失和梯度爆炸的问题。
















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









