






常见的锁策略:
加锁的过程中,还有处理冲突的过程中,涉及到的一些 处理的方式.
此处锁策略,并非是Java独有的.(这里的 锁策略,主要是设计锁的人需要理解)
乐观锁和悲观锁
乐观锁:
预估在加锁之前,出现锁冲突的可能性不大,所以就不会做很多的工作.(加锁的时候比较简单,但是也就更容易出现问题,虽然加锁的速度更快,但是有可能出现问题,导致cpu占用的更多)
悲观锁:
在加锁之前,判断可能出现问题可能性大,所以加锁之前会进行比较多的处理(加锁的时候可能更慢,但是会出现问题的可能性更小)
轻量级锁和重量级锁
轻量级锁:
加锁的速度快,消耗小.=>就类似乐观锁
重量级锁:
加锁的速度慢,消耗大=>就类似悲观锁
自旋锁和挂起等待锁
自旋锁就是轻量级锁的实现:
进行加锁的时候,加一个while,如果加锁成功,while自动结束.
如果加锁不成功,不是阻塞放弃cpu,而是进行下一次循环,再次尝试获取到锁.
这个反复的过程就是自旋,一旦其他线程释放了锁,就能第一时间拿到锁,同样,这样的自旋锁是乐观锁,使用自旋的前提,就是预估锁的冲突不大,对方一释放锁,这边就可以第一时间拿到锁.如果锁冲突大,那就会白白浪费cpu.
挂起等待锁是一种重量级锁的实现:
同样也是一种悲观锁,进行挂起等待的时候就需要内核调度器了,这一块要完成的操作就多了,真正获取到锁要花的时间更多一些.
Java中的synchronized算哪种锁?
synchronized具有自适应能力.
synchronized在某些情况下是乐观锁/轻量锁/自旋锁.有些情况下是悲观锁/轻量锁/挂起等待锁.
内部会自动评估锁冲突的激烈程度.
如果冲突不大就是乐观锁.如果冲突大就是悲观锁.
普通互斥锁和读写锁
普通互斥锁:类似于synchronized这些涉及到加锁和解锁的.
读写锁:类似于加读锁和加写锁.


公平锁和非公平锁


要想实现公平,就得使用数据结构.(记录每个线程的先后顺序).
可重入锁和不可重入锁
一个线程对这个锁加锁两次,如果不会死锁,就是可重入锁,如果会死锁就是不可重入锁.
synchronized是可重入锁.系统自带的锁是不可重入锁.
可重入锁需要记录持有锁的线程是谁,还有重入次数.

synchronized的自适应
synchronized的优化设计的很好.synchronized的自适应是怎么自己适应的呢???
谈恋爱就意思是"加锁".(举个例子方便理解!!!)
1.偏向锁阶段
核心思想,"懒汉模式",能不加锁,就不加锁,能晚加锁,就晚加锁.所谓的偏向锁,并非真的加锁了,而只是做了一个非常轻量的标记~~
搞暖昧, 就是偏向锁~~ 只是做一个标记,没有真加锁(也不会有互斥)一旦有其他线程,来和我竞争这个锁,就在另一个线程之前,先把锁获取到~~从偏向锁就会升级到轻量级锁(真加锁了,就有互斥了)如果我搞暖昧的过程中,要是没人来竞争,整个过程就把,加锁这样的操作就完全省略了!!
2.轻量级锁阶段
(假设有竞争,但是不多
此处就是通过自旋锁的方式来实现的
优势: 另外的线程把锁释放了,就会第一时间拿到锁劣势: 比较消耗 cpu
于此同时,同步内部也会统计当前这个锁对象上,有多少个线程在参与竞争这里当发现参与竞争的线程比较多了,就会进一步升级到重量级锁
对于自旋锁来说,如果同一个锁竞争者很多大量的线程都在自旋,整体 cpu 的消耗就很大了.
3. 重量级锁阶段
此时拿不到锁的线程就不会继续自旋了,而是进入"阻塞等待就会让出 cpu 了.(不会使 cpu 占用率太高)
当当前线程释放锁的时候,就由系统随机唤醒一个线程来获取锁了~~
一个锁,只能从1->2->3.不可以2->1.不会出现降级.
锁消除
也是锁优化的一个部分
编译器如果发现这个锁不需要加锁,就会把这个锁去掉.

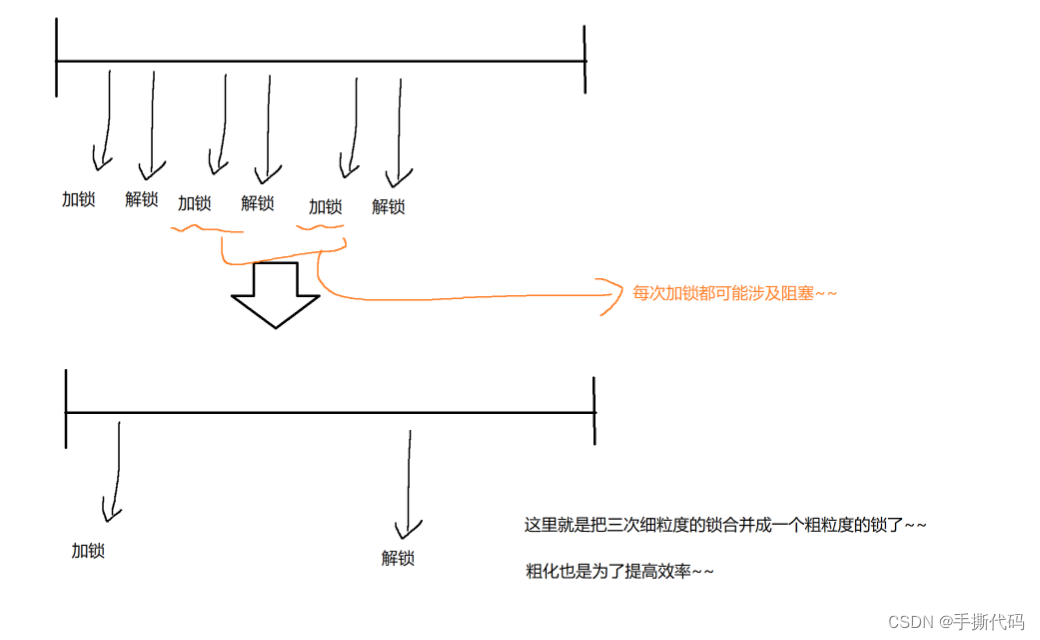
锁粗化


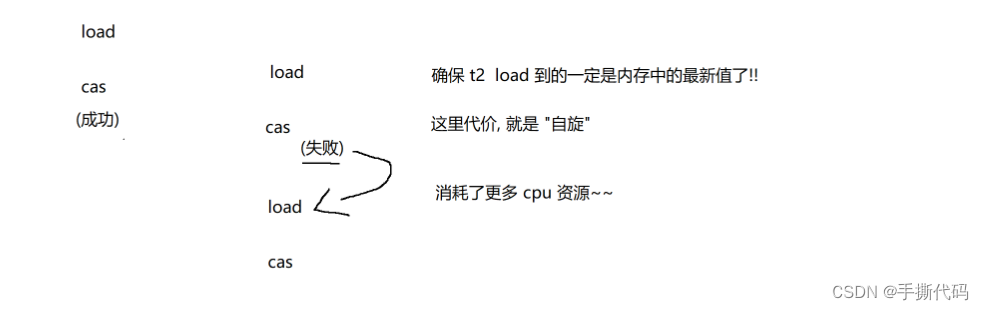
CAS
Compare and swap
![]()





import java.util.concurrent.atomic.AtomicInteger;
public class niucr {
public static void main(String[] args) throws InterruptedException {
AtomicInteger count = new AtomicInteger(0);
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.getAndIncrement();//count++意思相同
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.incrementAndGet();//++count意思相同
// count.getAndAdd(n); 意思是count += n;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
}
CAS的ABA问题
举个例子:比如我去买手机,我买的是新的,但是其实是别人把用过的翻新卖给我,意味着我花了原价买了二手的.虽然外表看起来是新的,但是其实里面已经久了.
使用CAS的时候,关键要点是判断内存中的值和寄存器中的值是否一样.如果一样就进行修改,不一样就不改.(本质上是判断当前线程是否有其他线程穿插进来了.)
所以就会发生如下这种情况:在a线程执行之前,b线程将0->9,c线程将9->0;当要执行a线程的时候,不是没有别的线程穿插,而是有别的线程将他改回去了.一般来说,这种不会出现bug,但是一些特殊情况情况下就十分影响.
那什么算极端情况呢??
比如:去银行取钱.
初始账户里面有1000,要取500;
此时按了一下取钱按钮(称为a线程),卡了一下,又再次按了一下取钱按钮(称为b线程)
此时b线程执行如下代码:
b线程成功将钱取出.
之后又来了个存钱操作(称为c线程),存钱500;
然后再执行a线程,可是此时账户里的钱,以前取了500了,现在之所以有1000是因为又存了500;
可是此时a线程会继续执行.这样就出错了.(这种就是ABA问题).

JUC(java.util.concurrent)的常⻅类

Callable接⼝
Callable是⼀个interface.相当于把线程封装了⼀个"返回值.⽅便程序猿借助多线程的⽅式计算结
果.
比如我们要计算一个1+2+...+1000的计算.如果不用Callable版本.
static class Result {
public int sum = 0;
public Object lock = new Object();
}
public static void main(String[] args) throws InterruptedException {
Result result = new Result();
Thread t = new Thread() {
@Override
public void run() {
int sum = 0;
for (int i = 1; i <= 1000; i++) {
sum += i;
}
synchronized (result.lock) {
result.sum = sum;
result.lock.notify();
}
}
};
t.start();
synchronized (result.lock) {
while (result.sum == 0) {
result.lock.wait();
}
System.out.println(result.sum);
}
}可以看到,上述代码需要⼀个辅助类Result,还需要使⽤⼀系列的加锁和wait notify操作,代码复杂,容易出错.
创建线程计算1+2+3+...+1000,使⽤Callable版本
• 创建⼀个匿名内部类,实现Callable接⼝.Callable带有泛型参数.泛型参数表⽰返回值的类型.
• 重写Callable的call⽅法,完成累加的过程.直接通过返回值返回计算结果.
• 把callable实例使⽤ FutureTask包装⼀下.
• 创建线程,线程的构造⽅法传⼊FutureTask.此时新线程就会执⾏FutureTask内部的Callable的
call⽅法,完成计算.计算结果就放到了FutureTask对象中.
• 在主线程中调⽤ futureTask.get() 能够阻塞等待新线程计算完毕.并获取到FutureTask中的
结果
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 1000; i++) {
sum += i;
}
return sum;
}
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread t = new Thread(futureTask);
t.start();
int result = futureTask.get();
System.out.println(result);可以看到,使⽤Callable和FutureTask之后,代码简化了很多,也不必⼿动写线程同步代码了.
理解Callable
Callable和Runnable相对,都是描述⼀个"任务".Callable描述的是带有返回值的任务,Runnable描述的是不带返回值的任务.
Callable通常需要搭配FutureTask来使⽤.FutureTask⽤来保存Callable的返回结果.因为
Callable往往是在另⼀个线程中执⾏的,啥时候执⾏完并不确定.
FutureTask就可以负责这个等待结果出来的⼯作.
理解FutureTask
想象去吃⿇辣烫.当餐点好后,后厨就开始做了.同时前台会给你⼀张"⼩票".这个⼩票就是FutureTask.后⾯我们可以随时凭这张⼩票去查看⾃⼰的这份⿇辣烫做出来了没.
ReentrantLock
可重⼊互斥锁.和synchronized定位类似,都是⽤来实现互斥效果,保证线程安全.

ReentrantLock的⽤法:
• lock():加锁,如果获取不到锁就死等.
• trylock(超时时间):加锁,如果获取不到锁,等待⼀定的时间之后就放弃加锁.
• unlock():解锁


信号量Semaphore
信号量,⽤来表⽰"可⽤资源的个数".本质上就是⼀个计数器.
理解信号量
可以把信号量想象成是停⻋场的展⽰牌:当前有⻋位100个.表⽰有100个可⽤资源.
当有⻋开进去的时候,就相当于申请⼀个可⽤资源,可⽤⻋位就-1(这个称为信号量的P操作)
当有⻋开出来的时候,就相当于释放⼀个可⽤资源,可⽤⻋位就+1(这个称为信号量的V操作)
如果计数器的值已经为0了,还尝试申请资源,就会阻塞等待,直到有其他线程释放资源.
Semaphore的PV操作中的加减计数器操作都是原⼦的,可以在多线程环境下直接使⽤.
代码⽰例:
• 创建Semaphore⽰例,初始化为4,表⽰有4个可⽤资源.
• acquire⽅法表⽰申请资源(P操作),release⽅法表⽰释放资源(V操作)
• 创建20个线程,每个线程都尝试申请资源,sleep1秒之后,释放资源.观察程序的执⾏效果.
Semaphore semaphore = new Semaphore(4);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
System.out.println("申请资源");
semaphore.acquire();
System.out.println("我获取到资源了");
Thread.sleep(1000);
System.out.println("我释放资源了");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 20; i++) {
Thread t = new Thread(runnable);
t.start();
}知识点杂(重要)
CountDownLatch
同时等待N个任务执⾏结束.
好像跑步⽐赛,10个选⼿依次就位,哨声响才同时出发;所有选⼿都通过终点,才能公布成绩.
构造CountDownLatch实例,初始化10表⽰有10个任务需要完成.
• 每个任务执⾏完毕,都调⽤ latch.countDown() .在CountDownLatch内部的计数器同时⾃
减.
• 主线程中使⽤ latch.await(); 阻塞等待所有任务执⾏完毕.相当于计数器为0了.
import java.util.concurrent.CountDownLatch;
public class Demo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(10);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
Thread.sleep((long) (Math.random() * 10000));
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 10; i++) {
new Thread(runnable).start();
}
latch.await();
System.out.println("比赛结束");
}
}
相关⾯试题
1. 线程同步的⽅式有哪些
synchronized,ReentrantLock,Semaphore等都可以⽤于线程同步.
2. 为什么有了synchronized还需要juc下的lock
以juc的ReentrantLock为例,
• synchronized使⽤时不需要⼿动释放锁.ReentrantLock使⽤时需要⼿动释放.使⽤起来更灵活,
• synchronized在申请锁失败时,会死等.ReentrantLock可以通过trylock的⽅式等待⼀段时间就放
弃.
• synchronized是⾮公平锁,ReentrantLock默认是⾮公平锁.可以通过构造⽅法传⼊⼀个true开启
公平锁模式.
• synchronized是通过Object的wait/notify实现等待-唤醒.每次唤醒的是⼀个随机等待的线程.
ReentrantLock搭配Condition类实现等待-唤醒,可以更精确控制唤醒某个指定的线程.
3. AtomicInteger的实现原理是什么?
基于CAS机制.伪代码如下:
class AtomicInteger {
private int value;
public int getAndIncrement() {
int oldValue = value;
while ( CAS(value, oldValue, oldValue+1) != true) {
oldValue = value;
}
return oldValue;
}
}4. 信号量听说过么之前都⽤在过哪些场景下
信号量,⽤来表⽰"可⽤资源的个数".本质上就是⼀个计数器.
使⽤信号量可以实现"共享锁",⽐如某个资源允许3个线程同时使⽤,那么就可以使⽤P操作作为加
锁,V操作作为解锁,前三个线程的P操作都能顺利返回,后续线程再进⾏P操作就会阻塞等待,直到前
⾯的线程执⾏了V操作.
5. 解释⼀下ThreadPoolExecutor构造⽅法的参数的含义
参考上⾯的ThreadPoolExecutor章节
线程安全的集合类
原来的集合类,⼤部分都不是线程安全的.
Vector,Stack,HashTable,是线程安全的(不建议⽤),其他的集合类不是线程安全的.
多线程环境使⽤ArrayList
1. ⾃⼰使⽤同步机制(synchronized或者ReentrantLock)
前⾯做过很多相关的讨论了.此处不再展开.
2. Collections.synchronizedList(new ArrayList);
synchronizedList是标准库提供的⼀个基于synchronized进⾏线程同步的List.synchronizedList
的关键操作上都带有synchronized.
3. 使⽤CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器。
• 当我们往⼀个容器添加元素的时候,不直接往当前容器添加,⽽是先将当前容器进⾏Copy,复制出⼀个新的容器,然后新的容器⾥添加元素,
• 添加完元素之后,再将原容器的引⽤指向新的容器。
这样做的好处是我们可以对CopyOnWrite容器进⾏并发的读,⽽不需要加锁,因为当前容器不会添
加任何元素。
所以CopyOnWrite容器也是⼀种读写分离的思想,读和写不同的容器。
优点:
在读多写少的场景下,性能很⾼,不需要加锁竞争.
缺点:
1. 占⽤内存较多.
2. 新写的数据不能被第⼀时间读取到.
多线程环境使⽤队列
1. ArrayBlockingQueue
基于数组实现的阻塞队列
2. LinkedBlockingQueue
基于链表实现的阻塞队列
3. PriorityBlockingQueue
基于堆实现的带优先级的阻塞队列
4. TransferQueue
最多只包含⼀个元素的阻塞队列
多线程环境使⽤哈希表
HashMap本⾝不是线程安全的.
在多线程环境下使⽤哈希表可以使⽤:
• Hashtable
• ConcurrentHashMap
1)Hashtable
只是简单的把关键⽅法加上了synchronized关键字.
这相当于直接针对Hashtable对象本⾝加锁.
• 如果多线程访问同⼀个Hashtable就会直接造成锁冲突.
• size属性也是通过synchronized来控制同步,也是⽐较慢的.
• ⼀旦触发扩容,就由该线程完成整个扩容过程.这个过程会涉及到⼤量的元素拷⻉,效率会⾮常低.
2)ConcurrentHashMap
相⽐于Hashtable做出了⼀系列的改进和优化.以Java1.8为例
• 读操作没有加锁(但是使⽤了volatile保证从内存读取结果),只对写操作进⾏加锁.加锁的⽅式仍然
是是⽤synchronized,但是不是锁整个对象,⽽是"锁桶"(⽤每个链表的头结点作为锁对象),⼤⼤降
低了锁冲突的概率.
• 充分利⽤CAS特性.⽐如size属性通过CAS来更新.避免出现重量级锁的情况.
• 优化了扩容⽅式:化整为零
◦ 发现需要扩容的线程,只需要创建⼀个新的数组,同时只搬⼏个元素过去.
◦ 扩容期间,新⽼数组同时存在.
◦ 后续每个来操作ConcurrentHashMap的线程,都会参与搬家的过程.每个操作负责搬运⼀⼩部
分元素.
◦ 搬完最后⼀个元素再把⽼数组删掉.
◦ 这个期间,插⼊只往新数组加.
◦ 这个期间,查找需要同时查新数组和⽼数组
1. ConcurrentHashMap的读是否要加锁,为什么
读操作没有加锁.⽬的是为了进⼀步降低锁冲突的概率.为了保证读到刚修改的数据,搭配了volatile
关键字.
2. 介绍下ConcurrentHashMap的锁分段技术
这个是Java1.7?中采取的技术.Java1.8中已经不再使⽤了.简单的说就是把若⼲个哈希桶分成⼀个
"段"(Segment),针对每个段分别加锁.
⽬的也是为了降低锁竞争的概率.当两个线程访问的数据恰好在同⼀个段上的时候,才触发锁竞争.
3. ConcurrentHashMap在jdk1.8做了哪些优化
取消了分段锁,直接给每个哈希桶(每个链表)分配了⼀个锁(就是以每个链表的头结点对象作为锁对
象).
将原来数组+链表的实现⽅式改进成数组+链表/红⿊树的⽅式.当链表较⻓的时候(⼤于等于8个
元素)就转换成红⿊树.
4. Hashtable和HashMap、ConcurrentHashMap之间的区别
HashMap:线程不安全.key允许为null
Hashtable:线程安全.使⽤synchronized锁Hashtable对象,效率较低.key不允许为null.
ConcurrentHashMap:线程安全.使⽤synchronized锁每个链表头结点,锁冲突概率低,充分利⽤
CAS?机制.优化了扩容⽅式.key不允许为null
死锁
死锁是什么
死锁是这样⼀种情形:多个线程同时被阻塞,它们中的⼀个或者全部都在等待某个资源被释放。由于线程被⽆限期地阻塞,因此程序不可能正常终⽌。
举个栗⼦理解死锁
滑稽⽼哥和⼥神⼀起去饺⼦馆吃饺⼦.吃饺⼦需要酱油和醋.
滑稽⽼哥抄起了酱油瓶,⼥神抄起了醋瓶.
滑稽:你先把醋瓶给我,我⽤完了就把酱油瓶给你.
⼥神:你先把酱油瓶给我,我⽤完了就把醋瓶给你.
如果这俩⼈彼此之间互不相让,就构成了死锁.
酱油和醋相当于是两把锁,这两个⼈就是两个线程.

为了进⼀步阐述死锁的形成,很多资料上也会谈论到"哲学家就餐问题".
• 有个桌⼦,围着⼀圈哲学家,桌⼦中间放着⼀盘意⼤利⾯.每个哲学家两两之间,放着⼀根筷⼦.
如果哲学家发现筷⼦拿不起来了(被别⼈占⽤了),就会阻塞等待.
[关键点在这]假设同⼀时刻,五个哲学家同时拿起左⼿边的筷⼦,然后再尝试拿右⼿的筷⼦,就会发
现右⼿的筷⼦都被占⽤了.由于哲学家们互不相让,这个时候就形成了死锁.
死锁是⼀种严重的BUG!!导致⼀个程序的线程"卡死",⽆法正常⼯作!
如何避免死锁
死锁产⽣的四个必要条件:
• 互斥使⽤,即当资源被⼀个线程使⽤(占有)时,别的线程不能使⽤
• 不可抢占,资源请求者不能强制从资源占有者⼿中夺取资源,资源只能由资源占有者主动释放。
• 请求和保持,即当资源请求者在请求其他的资源的同时保持对原有资源的占有。
• 循环等待,即存在⼀个等待队列:P1占有P2的资源,P2占有P3的资源,P3占有P1的资源。这样就形成了⼀个等待环路。
当上述四个条件都成⽴的时候,便形成死锁。当然,死锁的情况下如果打破上述任何⼀个条件,便可让死锁消失。
其中最容易破坏的就是"循环等待"
破坏循环等待
最常⽤的⼀种死锁阻⽌技术就是锁排序.假设有N个线程尝试获取M把锁,就可以针对M把锁进⾏编号(1,?2,?3...M).
N个线程尝试获取锁的时候,?都按照固定的按编号由⼩到⼤顺序来获取锁.这样就可以避免环路等待.
可能产⽣环路等待的代码:
两个线程对于加锁的顺序没有约定,就容易产⽣环路等待
Object lock1 = new Object();
Object lock2 = new Object();
Thread t1 = new Thread() {
@Override
public void run() {
synchronized (lock1) {
synchronized (lock2) {
// do something...
}
}
}
};
t1.start();
Thread t2 = new Thread() {
@Override
public void run() {
synchronized (lock2) {
synchronized (lock1) {
// do something...
}
}
}
};
t2.start();不会产⽣环路等待的代码:
约定好先获取lock1,再获取lock2,就不会环路等待.
Object lock1 = new Object();
Object lock2 = new Object();
Thread t1 = new Thread() {
@Override
public void run() {
synchronized (lock1) {
synchronized (lock2) {
// do something...
}
}
}
};
t1.start();
Thread t2 = new Thread() {
@Override
public void run() {
synchronized (lock1) {
synchronized (lock2) {
// do something...
}
}
}
};
t2.start();相关⾯试题
谈谈死锁是什么,如何避免死锁,避免算法,实际解决过没有
参考整个"死锁"章节
其他常⻅问题
1. 谈谈volatile关键字的⽤法
volatile能够保证内存可⻅性.强制从主内存中读取数据.此时如果有其他线程修改被volatile修饰的
变量,可以第⼀时间读取到最新的值.
2. Java多线程是如何实现数据共享的
JVM把内存分成了这⼏个区域:
⽅法区,堆区,栈区,程序计数器.
其中堆区这个内存区域是多个线程之间共享的.
只要把某个数据放到堆内存中,就可以让多个线程都能访问到.
3. Java创建线程池的接⼝是什么参数 LinkedBlockingQueue 的作⽤是什么
创建线程池主要有两种⽅式:
• 通过Executors⼯⼚类创建.创建⽅式⽐较简单,但是定制能⼒有限.
• 通过ThreadPoolExecutor创建.创建⽅式⽐较复杂,但是定制能⼒强.
LinkedBlockingQueue 表⽰线程池的任务队列.⽤⼾通过submit/execute向这个任务队列中
添加任务,再由线程池中的⼯作线程来执⾏任务.
4. Java线程共有⼏种状态状态之间怎么切换的?
• NEW:安排了⼯作,还未开始⾏动.新创建的线程,还没有调⽤start⽅法时处在这个状态.
• RUNNABLE:可⼯作的.⼜可以分成正在⼯作中和即将开始⼯作.调⽤start⽅法之后,并正在CPU上运⾏/在即将准备运⾏的状态.
• BLOCKED:使⽤synchronized的时候,如果锁被其他线程占⽤,就会阻塞等待,从⽽进⼊该状态.
• WAITING:调⽤wait⽅法会进⼊该状态.
• TIMED_WAITING:调⽤?sleep⽅法或者wait(超时时间)会进⼊该状态.
• TERMINATED:⼯作完成了.当线程?run⽅法执⾏完毕后,会处于这个状态.
5. 在多线程下,如果对⼀个数进⾏叠加,该怎么做
• 使⽤synchronized/ReentrantLock加锁
• 使⽤AtomInteger原⼦操作.
6. Servlet是否是线程安全的?
Servlet本⾝是⼯作在多线程环境下.
如果在Servlet中创建了某个成员变量,此时如果有多个请求到达服务器,服务器就会多线程进⾏操
作,是可能出现线程不安全的情况的.
7. Thread和Runnable的区别和联系?
Thread类描述了⼀个线程.
Runnable描述了⼀个任务.
在创建线程的时候需要指定线程完成的任务,可以直接重写Thread的run⽅法,也可以使⽤
Runnable来描述这个任务.
8. 多次start⼀个线程会怎么样?
第⼀次调⽤start可以成功调⽤.
后续再调⽤start会抛出java.lang.IllegalThreadStateException异常
9. 有synchronized两个⽅法,两个线程分别同时⽤这个⽅法,请问会发⽣什么?
synchronized加在⾮静态⽅法上,相当于针对当前对象加锁.
如果这两个⽅法属于同⼀个实例:
线程1能够获取到锁,并执⾏⽅法.线程2会阻塞等待,直到线程1执⾏完毕,释放锁,线程2获取到锁之
后才能执⾏⽅法内容.
如果这两个⽅法属于不同实例:
两者能并发执⾏,互不⼲扰.
10. 进程和线程的区别?
• 进程是包含线程的.每个进程⾄少有⼀个线程存在,即主线程。
• 进程和进程之间不共享内存空间.同⼀个进程的线程之间共享同⼀个内存空间.
• 进程是系统分配资源的最⼩单位,线程是系统调度的最⼩单位。















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









