






嵌套循环(Nested Loops)
在 SQL Server 中,Nested Loops(嵌套循环)是一种常用的连接算法,适用于小数据集或索引支持的场景。Nested Loops 的执行逻辑比较简单且直接,但在处理大规模数据时可能效率较低。
嵌套循环(Nested Loops)的执行逻辑
嵌套循环可以理解为就是两层For循环,外层For对应外部输入表(执行计划的图示排在上面),内层For对应内部出入表(执行计划的图示排在下面)
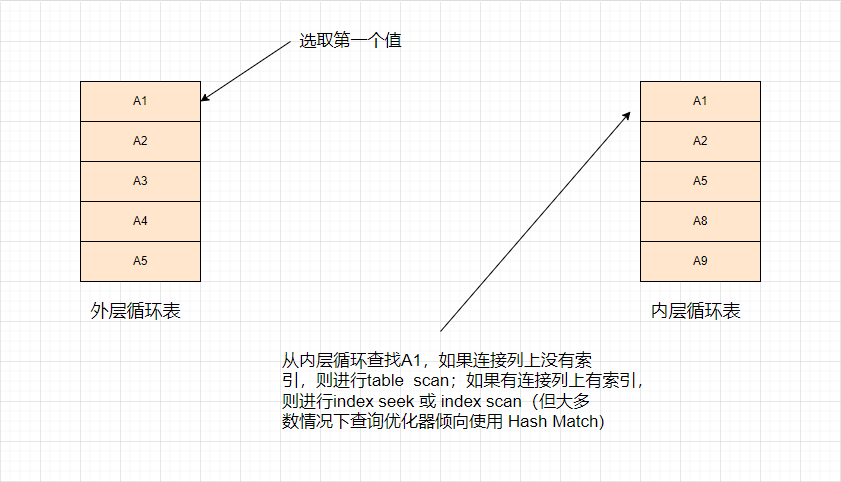
嵌套循环(Nested Loops)的优缺点:
- 优点:
实现简单,逻辑清晰。
对于小数据集或内部输入有索引支持的情况下非常高效。 - 缺点:
对于大规模数据集,效率较低,因为每个外部输入的记录都需要扫描整个内部输入集
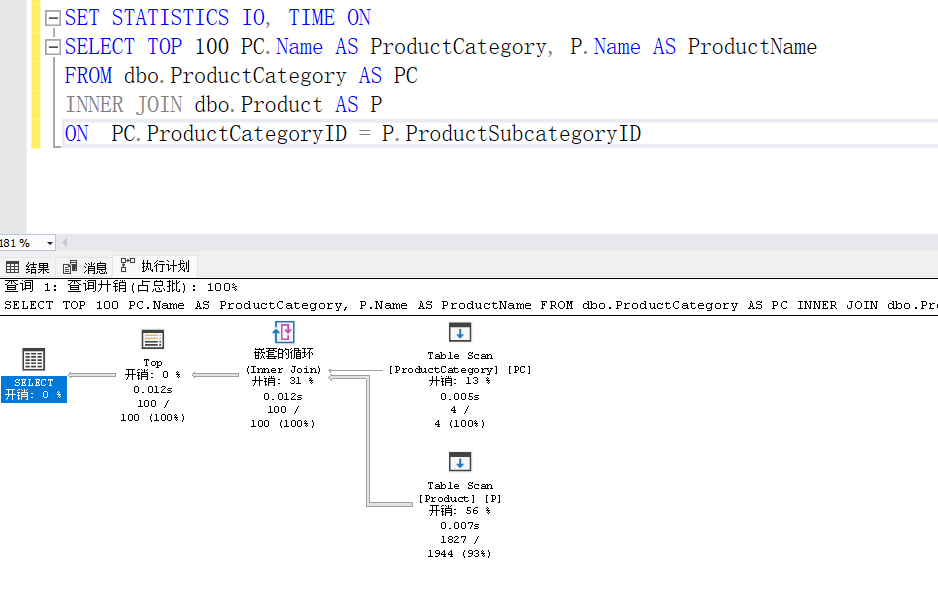
嵌套循环(Nested Loops)的测试
合并关联(Merge Join)
在 SQL Server 中,Merge Join(合并连接)是一种高效的连接算法,通常在以下条件下使用:
- 两个输入集都已经按连接键排序。
- 连接键的数据类型相同。
Merge Join 的示例
假设有两个表 TableA 和 TableB,分别包含 ID 列作为连接键。我们希望连接这两个表。数据如下:
TableA(已按 ID 排序):
ID | ValueA |
1 | A1 |
2 | A2 |
3 | A3 |
TableB(已按 ID 排序):
ID | ValueB |
1 | B1 |
2 | B2 |
4 | B4 |
执行以下查询:
在执行计划中,SQL Server 可能会选择使用 Merge Join 算法来执行这个连接操作。Merge Join 的执行过程如下:
- 初始化:
- 初始化两个指针,分别指向 TableA 和 TableB 的第一个记录。
- 合并阶段(Merge Phase):
- 比较
TableA的当前记录(1, A1)和TableB的当前记录(1, B1)的连接键:
- 两个连接键相等,将匹配的记录
(1, A1, B1)加入结果集。 - 移动两个指针到各自的下一个记录。
- 比较
TableA的当前记录(2, A2)和TableB的当前记录(2, B2)的连接键:
- 两个连接键相等,将匹配的记录
(2, A2, B2)加入结果集。 - 移动两个指针到各自的下一个记录。
- 比较
TableA的当前记录(3, A3)和TableB的当前记录(4, B4)的连接键:
3 < 4,移动TableA的指针到下一个记录。
TableA到达末尾,连接操作完成。
- 结束:
- 当其中一个输入集到达末尾时,连接操作完成。
Merge Join 的执行逻辑
- 排序阶段(如果需要):
- 如果输入数据没有按连接键排序,SQL Server 可能会先对输入数据进行排序。
- 如果输入数据已经按连接键排序,则跳过排序阶段。
- 合并阶段(Merge Phase):
- 初始化两个指针,分别指向两个输入集的第一个记录。
- 比较两个指针所指向记录的连接键。
- 根据连接键的比较结果,执行以下操作:
- 如果两个连接键相等,则将匹配的记录加入结果集,并移动两个指针到各自的下一个记录。
- 如果连接键不相等,则移动指向较小连接键的指针到下一个记录。
- 重复上述步骤,直到其中一个输入集到达末尾。
Merge Join 的优缺点
- 优点:
对于大规模数据集,排序后的数据能够高效地执行连接操作。
当数据已经排序时,Merge Join 是非常高效的。 - 缺点:
需要输入集按连接键排序。
在某些情况下,可能需要额外的排序操作,增加了额外的开销。
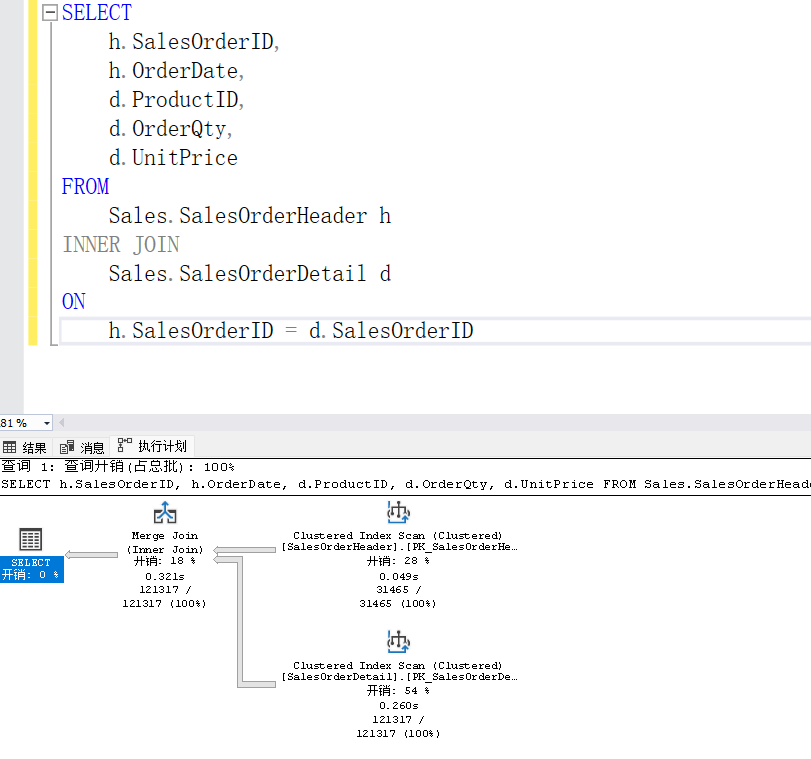
Merge Join 的测试
Hash Match 连接
Hash Match(哈希匹配)连接是一种高效的连接算法,特别适用于大规模数据集且连接键没有预排序的情况。Hash Match 连接主要分为两个阶段:构建阶段(Build Phase)和探测阶段(Probe Phase)。
Hash Match 连接的示例
假设有两个表 TableA 和 TableB,分别包含 ID 列作为连接键。我们希望连接这两个表。数据如下:
TableA:
ID | ValueA |
1 | A1 |
2 | A2 |
3 | A3 |
TableB:
ID | ValueB |
1 | B1 |
2 | B2 |
4 | B4 |
5 | B5 |
执行以下查询:
在执行计划中,SQL Server 可能会选择使用 Hash Match 算法来执行这个连接操作。Hash Match 连接的执行过程如下:
- 构建阶段(Build Phase):
- 选择较小的 TableA 作为构建输入。
- 遍历 TableA 的所有记录,根据 ID 列计算哈希值并将记录插入哈希表:
- 记录 (1, A1) 计算哈希值后插入哈希桶。
- 记录 (2, A2) 计算哈希值后插入哈希桶。
- 记录 (3, A3) 计算哈希值后插入哈希桶。
- 探测阶段(Probe Phase):
- 遍历较大的 TableB 的所有记录,计算 ID 列的哈希值并在哈希表中查找匹配记录:
- 记录 (1, B1) 计算哈希值后查找哈希表,找到匹配的 (1, A1),结果集加入 (1, A1, B1)。
- 记录 (2, B2) 计算哈希值后查找哈希表,找到匹配的 (2, A2),结果集加入 (2, A2, B2)。
- 记录 (4, B4) 计算哈希值后查找哈希表,没有找到匹配记录,不加入结果集。
- 记录 (5, B5) 计算哈希值后查找哈希表,没有找到匹配记录,不加入结果集。
- 结束:
当所有TableB的记录都处理完毕,连接操作完成。
Hash Match 连接的执行逻辑
- 构建阶段(Build Phase):
- 从两个输入集(通常称为构建输入和探测输入)中选择较小的输入集作为构建输入。
- 遍历构建输入的所有记录,并根据连接键计算每个记录的哈希值。
- 根据哈希值将记录插入到哈希表的适当桶中。
- 探测阶段(Probe Phase):
- 遍历较大的输入集(探测输入)的所有记录。
- 对每个探测输入的记录,计算其连接键的哈希值。
- 使用计算出的哈希值,在哈希表中查找匹配的桶。
- 如果找到匹配的记录,则将其加入结果集中。
Hash Match 连接的优缺点:
- 优点:
- 不需要输入数据排序,因此在数据未排序且数据量较大的情况下非常高效。
- 能够处理大规模数据集并行化。
- 缺点:
- 在构建哈希表时可能需要消耗大量内存。
- 当数据量特别大时,可能需要将哈希表部分存储到磁盘,导致性能下降
Hash Match 连接的测试















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









