







RabbitMQ的集群是指将多个RabbitMQ节点(服务器)组织在一起,以提供更高可用性、容错性和扩展性的机制。在RabbitMQ中,集群允许节点之间共享消息、队列和其他资源,从而使得消息可以在集群中的不同节点上进行处理。
当创建一个RabbitMQ集群时,集群中的每个节点都会共享相同的元数据,比如交换器(exchanges)、队列(queues)、绑定(bindings)和用户(users)等。但是,消息内容本身并不是在节点之间复制的,而是根据队列的配置和策略分布在不同的节点上。
RabbitMQ集群的主要特点包括:
- 高可用性(HA):通过将队列配置为镜像队列(mirrored queues),可以在集群中的多个节点上复制队列和消息,这样即使某个节点宕机,其他节点仍然可以处理消息,从而保证了服务的持续可用性。
- 负载均衡:集群可以根据策略在节点之间分配队列和消费者,从而实现负载均衡,提高整体的吞吐量和性能。
- 容错:如果集群中的一个节点失败,其他节点可以接管其工作,确保消息不会丢失,并且客户端可以继续发送和接收消息。
- 扩展性:通过向集群添加更多的节点,可以水平扩展RabbitMQ的处理能力,以应对更大的负载。
- 网络分区容忍:RabbitMQ集群设计为在网络分区发生时保持运行,尽管在这种情况下可能会有一些限制和权衡。
要创建RabbitMQ集群,通常需要在配置文件中设置集群节点,并确保节点之间可以通过网络相互通信。集群的形成通常涉及到节点的握手过程,以确保它们可以协同工作。在生产环境中,RabbitMQ集群通常会结合使用镜像队列和其他高级配置,以确保服务的稳定性和可靠性。
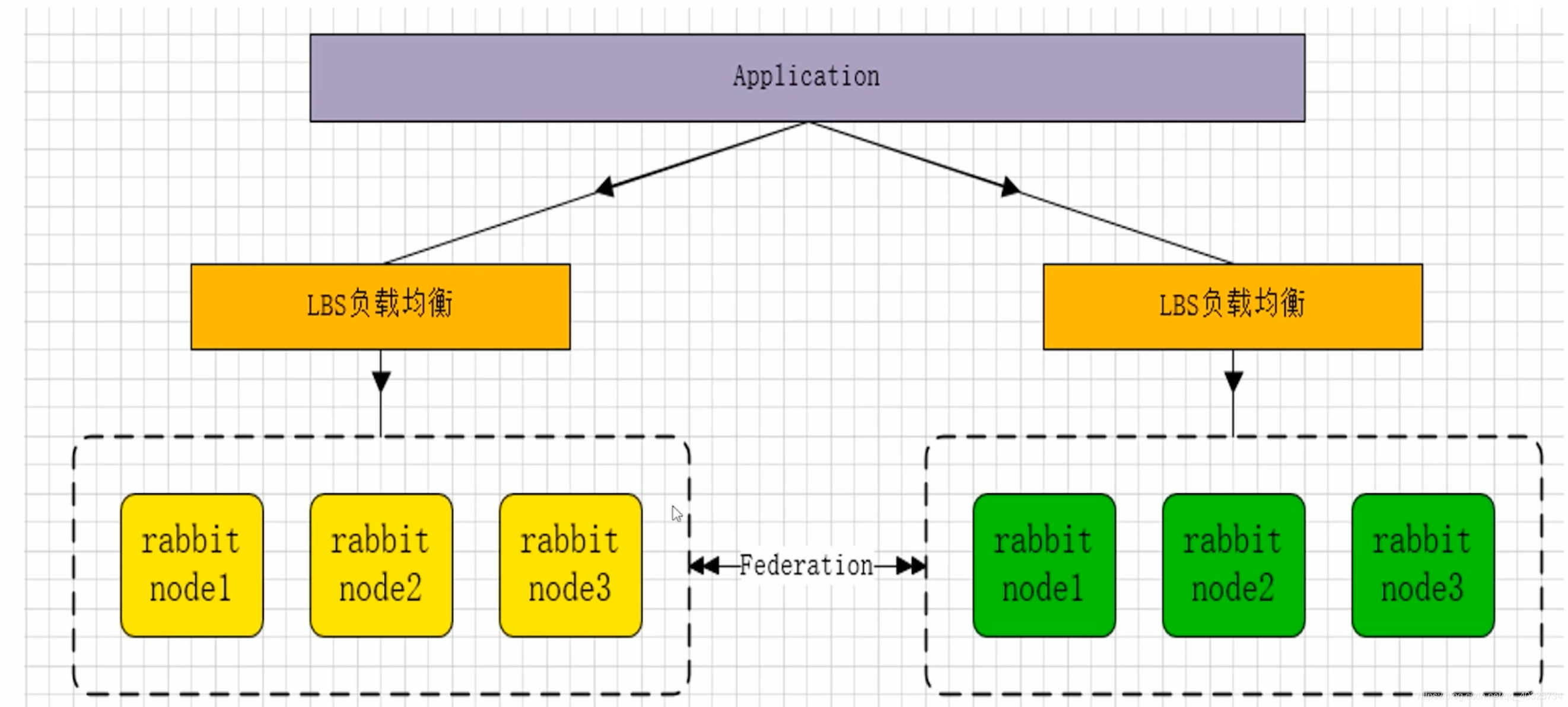
RabbitMQ 的集群是通过 Erlang/OTP 平台的分布式特性实现的。以下是 RabbitMQ 集群的实现方式和关键概念:
集群组件
- 节点:集群中的每个 RabbitMQ 服务器实例称为一个节点。所有节点必须运行相同版本的 RabbitMQ 和 Erlang。
- 元数据:集群的元数据包括队列定义、交换器、绑定、用户和权限等。这些元数据在集群中的节点之间共享。
- 数据:消息数据本身是存储在节点上的,默认情况下不会在集群节点间复制。
集群配置步骤
- 启动节点:首先,你需要启动每个 RabbitMQ 节点。节点启动时默认是独立的。
- 加入集群:要将节点加入集群,可以使用
rabbitmqctl命令的join_cluster子命令。第一个节点将成为集群的引导节点,后续节点将加入这个引导节点。
- 配置集群:确保所有节点都能够相互通信。通常需要配置 Erlang 分布式端口(默认为 25672)和网络防火墙规则。
- 同步元数据:一旦节点加入集群,它们将开始同步元数据。
集群特性
- 数据复制:RabbitMQ 支持镜像队列(Mirrored Queues),可以在多个节点之间复制队列内容,以提高可用性。这不是默认设置,需要手动配置。
- 故障转移:如果一个节点失败,拥有镜像队列的其它节点可以接管队列,继续处理消息。
- 负载均衡:集群可以分发消息到不同的节点,从而实现负载均衡。
- 扩展性:可以轻松地向集群添加更多节点以增加处理能力。
注意事项
- 脑裂问题:在网络分区的情况下,RabbitMQ 集群可能会发生脑裂,导致集群分裂成多个部分。RabbitMQ 提供了策略来处理这种情况,例如“ignore”或“pause_minority”。
- 数据一致性和持久化:确保消息持久化时,需要在所有镜像队列节点上配置合适的磁盘空间和性能,以避免写入瓶颈。
- 网络配置:集群节点之间的网络延迟应该尽可能低,以保证良好的性能。
- 集群大小:理论上,RabbitMQ 集群可以扩展到数百个节点,但实际操作中,节点数量通常保持在较小的规模,以简化管理和维护。 通过以上步骤和概念,你可以配置并运行一个 RabbitMQ 集群,以实现高可用性和可扩展性的消息传递系统。















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









