






循环展开(Loop Unrolling)是优化代码的一种有效方法,通过减少循环控制开销和提高指令级并行性来充分利用现代处理器和存储器系统的设计。以下是如何应用循环展开,以及其背后的原理和示例代码。
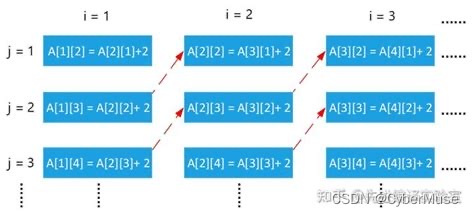
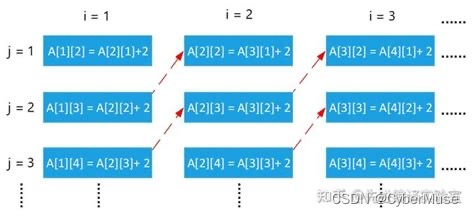
### 循环展开的原理
1. **减少循环控制开销**:每次循环迭代都会产生一些开销,如比较、跳转等指令。通过减少循环的总迭代次数,可以减少这些开销。
2. **提高指令级并行性**:现代处理器能够同时执行多条指令,通过展开循环,可以增加处理器的指令流水线中的指令数量,从而提高执行效率。
3. **提高数据局部性**:在某些情况下,循环展开可以提高数据的局部性,从而增加缓存命中率。
### 逐步解释和示例
#### 原始代码
```c
for (int i = 0; i < 1000; i++) {
array[i] = i * 2;
}
```
#### 优化后的代码:循环展开
```c
for (int i = 0; i < 1000; i += 4) {
array[i] = i * 2;
array[i + 1] = (i + 1) * 2;
array[i + 2] = (i + 2) * 2;
array[i + 3] = (i + 3) * 2;
}
```
### 逐步解释
1. **初始化循环控制变量**:
- 原始代码中,循环控制变量 `i` 每次递增1。
- 优化后的代码中,循环控制变量 `i` 每次递增4。
2. **减少循环控制开销**:
- 原始代码中的循环需要执行 1000 次比较和跳转操作。
- 优化后的代码中的循环只需要执行 250 次比较和跳转操作,因为每次迭代处理4个元素。
3. **增加指令级并行性**:
- 优化后的代码在每次循环迭代中执行了4次赋值操作,而不是1次。这可以更好地利用处理器的流水线能力,增加并行执行的指令数量。
### 适用范围和注意事项
1. **循环展开的程度**:循环展开的程度(每次展开多少次)应根据具体情况来决定,过度展开可能导致指令缓存溢出,反而降低性能。
2. **边界处理**:在实际应用中,需要处理数组长度不是展开次数整数倍的情况。例如,如果数组长度为1003,展开后的循环只能处理前1000个元素,剩余的3个元素需要单独处理。
3. **编译器优化**:现代编译器(如GCC、Clang)通常能自动进行某些循环展开优化,但手动展开可以更精细地控制优化过程,特别是在性能关键的代码路径中。
### 进一步优化
除了简单的循环展开,还可以结合其他优化技术,如:
1. **数据预取(Data Prefetching)**:提前加载将要访问的数据,提高缓存命中率。
2. **SIMD 指令**:使用单指令多数据(SIMD)指令集,如AVX、SSE等,进一步提高数据处理的并行性。
### 示例:结合SIMD指令的循环展开
```c
#include <immintrin.h> // 如果处理器支持AVX指令集
void optimized_function(int *array, int size) {
__m256i factor = _mm256_set1_epi32(2);
int i;
for (i = 0; i <= size - 8; i += 8) {
__m256i index = _mm256_setr_epi32(i, i+1, i+2, i+3, i+4, i+5, i+6, i+7);
__m256i result = _mm256_mullo_epi32(index, factor);
_mm256_storeu_si256((__m256i*)&array[i], result);
}
// 处理剩余的元素
for (; i < size; i++) {
array[i] = i * 2;
}
}
```
以下是对这段代码的逐行详细解释:
```c
#include <immintrin.h> // 如果处理器支持AVX指令集
```
- 这行代码包含了AVX指令集的头文件`immintrin.h`,该头文件定义了一组用于使用高级矢量扩展(AVX)的函数和数据类型。AVX是现代处理器的一种高级指令集,可以处理256位宽的数据寄存器。
```c
void optimized_function(int *array, int size) {
```
- 定义一个名为`optimized_function`的函数,该函数接收两个参数:一个指向整数数组的指针`array`以及数组的大小`size`。
```c
__m256i factor = _mm256_set1_epi32(2);
```
### `__m256i factor`
- **`__`**:这是一个双下划线前缀,表示这是一个编译器内建的特定数据类型(intrinsic type)。
- **`m`**:指的是“multimedia”,最初源自MMX(MultiMedia eXtension)技术。
- **`256`**:表示这个数据类型可以处理256位宽的数据。
- **`i`**:指的是“integer”,表示这个向量的数据类型是整数。
- **`__m256i`**:这是一个数据类型,表示一个256位宽的整数向量类型。这个类型来自AVX(Advanced Vector Extensions)指令集,它允许处理256位的向量数据。
- **`factor`**:这是一个变量名,用于存储这个256位整数向量
使用`__m256i`数据类型的原因是为了利用现代处理器的SIMD(Single Instruction, Multiple Data)能力。SIMD允许在一个指令周期内同时对多个数据进行相同的操作,从而大大提高运算的并行性和效率。
- 使用AVX指令`_mm256_set1_epi32(2)`将整数值`2`广播到这个向量的所有8个32位整数元素中,并将结果存储在`factor`中。
- **`_mm`**:表示这是一个与X86相关的内在函数(intrinsic function)。这个缩写来自“multimedia”,最初是为MMX技术(MultiMedia eXtension)设计的。
- **`256`**:表示这是一个256位宽的操作。AVX(Advanced Vector Extensions)指令集支持256位的SIMD(Single Instruction, Multiple Data)操作。
- **`set1`**:表示设置向量中的所有元素为同一个值。这个缩写来自“set one”,即将一个值广播到向量的所有位置。
- **`epi32`**:表示操作的是32位的有符号整数(integer)。`epi`来自“extended packed integer”,而`32`则表示32位。
注:"Extended Packed Integer" 翻译为 “扩展打包整数”。
- **Extended**(扩展的):表示这是一个扩展或增强的版本,通常指的是处理器指令集的扩展功能。
- **Packed**(打包的):表示多个数据元素被打包在一个寄存器中进行并行处理。
- **Integer**(整数):表示数据类型是整数。
```c
for (i = 0; i <= size - 8; i += 8) {
```
- 开始一个`for`循环,循环变量`i`从0开始,每次增加8,直到`i`大于等于`size - 8`。这样做的目的是每次处理8个数组元素。
```c
__m256i index = _mm256_setr_epi32(i, i+1, i+2, i+3, i+4, i+5, i+6, i+7);
```
- 创建一个256位的整数向量`index`,其元素依次被设置为`i, i+1, i+2, i+3, i+4, i+5, i+6, i+7`。该操作使用了AVX指令`_mm256_setr_epi32`, "set register"。具体来说,它表示按给定的顺序将值设置到寄存器中。
指令会按照参数提供的顺序将值设置到AVX寄存器中的每个位置上。例如:
```c
__m256i index = _mm256_setr_epi32(0, 1, 2, 3, 4, 5, 6, 7);
```
这段代码会将寄存器 `index` 设置为包含 `[0, 1, 2, 3, 4, 5, 6, 7]` 的向量。
```c
__m256i result = _mm256_mullo_epi32(index, factor);
```
- 创建一个256位的整数向量`result`,其每个元素是`index`向量对应元素与`factor`向量对应元素的乘积。该操作使用了AVX指令`_mm256_mullo_epi32`,它执行整数向量的逐元素乘法,并返回结果向量。
`mullo`是指“Multiply Low”,表示低位乘法操作。具体来说,它通常用于AVX或SSE指令集中,用于执行元素级的整数乘法,并只保留结果的低位部分。
低位乘法操作(Low Multiplication Operation)指的是在执行多精度整数乘法时,仅保留乘积的低位部分,而忽略高位部分。这样可以避免溢出并且更高效地处理大规模数据运算。这个操作在SIMD指令集中很常见,尤其是在处理向量化数据时。
```c
_mm256_storeu_si256((__m256i*)&array[i], result);
```
- 将`result`向量中的数据存储到数组`array`中,从位置`i`开始。该操作使用了AVX指令`_mm256_storeu_si256`,它将256位向量数据存储到未对齐的内存地址(即`&array[i]`)中。
`storeu`是指“Store Unaligned”,表示不对齐存储操作。它用于将数据从向量寄存器存储到内存中,而不要求内存地址是对齐的。
```c
// 处理剩余的元素
for (; i < size; i++) {
array[i] = i * 2;
}
```
- 处理数组中剩余的元素(如果数组长度不是8的倍数)。这个`for`循环从`i`的当前值开始,继续到`size`。在循环体内,对每个剩余的数组元素进行逐个处理,将其设置为`i * 2`。
### 总结
这段代码的主要目的是通过使用AVX指令集来并行处理数组中的数据,从而提高处理效率。具体来说,它通过以下步骤实现了这一目标:
1. **广播因子**:使用`_mm256_set1_epi32`将乘数2广播到向量的所有元素。
2. **设置索引向量**:在循环中使用`_mm256_setr_epi32`设置包含当前索引的向量。
3. **执行乘法**:使用`_mm256_mullo_epi32`执行向量化的逐元素乘法。
4. **存储结果**:使用`_mm256_storeu_si256`将结果存储到数组中。
5. **处理剩余元素**:处理数组中可能剩余的元素,这些元素不够形成一个完整的256位向量。
通过这些步骤,代码能够充分利用现代处理器的并行计算能力和存储器系统的设计,从而提高性能。
进一步优化:
3. 数据预取(Data Prefetching)
数据预取技术允许我们提前加载将要访问的数据,以提高缓存命中率。我们可以在循环中添加数据预取指令:
```c
#include <immintrin.h>
void optimized_function(int *array, int size) {
__m256i factor = _mm256_set1_epi32(2);
int i;
for (i = 0; i <= size - 8; i += 8) {
// 预取未来数据到缓存
_mm_prefetch((char*)&array[i + 16], _MM_HINT_T0);
__m256i data = _mm256_loadu_si256((__m256i*)&array[i]);
__m256i result = _mm256_mullo_epi32(data, factor);
_mm256_storeu_si256((__m256i*)&array[i], result);
}
for (; i < size; i++) {
array[i] = array[i] * 2;
}
}
```
### 解释
1. **`_mm256_set1_epi32(2)`**: 创建一个包含8个元素都为2的AVX寄存器,用于乘法操作。
2. **`_mm_prefetch((char*)&array[i + 16], _MM_HINT_T0)`**: 提前将未来的数组数据加载到缓存,`_MM_HINT_T0` 是一个提示,表示数据将很快被使用。
2.1. **`_mm_prefetch`**:
- 这是一个内建函数,用于预取数据到缓存。通过预取,可以减少内存访问延迟,提高程序性能。
2.2. **`(char*)&array[i + 16]`**:
- 这是函数的第一个参数,它表示要预取的内存地址。
- **`(char*)`**: 强制类型转换,将指向整数的指针转换为指向字符的指针。因为`_mm_prefetch`函数需要一个字符指针。
- **`&array[i + 16]`**: 获取数组中第`i + 16`个元素的地址。通过提前预取稍后会用到的数据,可以提高缓存命中率。
2.3. **`_MM_HINT_T0`**:
- 这是函数的第二个参数,是一个预取提示(hint)。`_MM_HINT_T0`表示最高优先级的预取,意味着数据将很快被访问,尽快加载到最近的缓存层(通常是L1缓存)。
3. **`_mm256_loadu_si256((__m256i*)&array[i])`**: 从内存中加载256位(8个32位整数)数据到AVX寄存器。
3.1. **`__m256i`**:
- 这是一个256位的整数向量类型,用于存储AVX寄存器中的数据。
3.2. **`data`**:
- 这是一个变量名,用于存储从内存加载的数据。
3.3. **`_mm256_loadu_si256`**:
- 这是一个内建函数,用于从内存中加载256位(即8个32位整数)的数据到一个AVX寄存器。`loadu`中的`u`表示不要求内存地址对齐(unaligned)。
3.4. **`(__m256i*)&array[i]`**:
- 这是函数的参数,表示要加载的数据的内存地址。
- **`(__m256i*)`**: 强制类型转换,将指向整数的指针转换为指向256位整数向量的指针。因为`_mm256_loadu_si256`函数需要一个指向256位整数向量的指针。
- **`&array[i]`**: 获取数组中第`i`个元素的地址。
4. **`_mm256_mullo_epi32(data, factor)`**: 执行向量化的整数乘法操作。
5. **`_mm256_storeu_si256((__m256i*)&array[i], result)`**: 将计算结果存回内存。
通过结合循环展开、AVX指令和数据预取技术,我们能够显著提高处理大数组时的性能。这种优化不仅减少了循环控制的开销,还充分利用了现代CPU的并行处理能力和缓存机制。希望这个例子能帮助你更好地理解这些优化技术,并应用到实际项目中。
### 总结
循环展开是一种有效的优化技术,可以通过减少循环控制开销和提高指令级并行性来优化代码性能。结合其他优化技术,如数据预取和SIMD指令,可以进一步提高性能。这些优化需要根据具体情况和硬件特性进行调整和测试,确保获得最佳的性能提升。

















 4202
4202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









