







数据迁移简介
01典型场景与需求
在国产化浪潮下,数据库系统的国产化替代成为了一个日益重要的议题,有助于企业降低对外依赖,提升信息安全和自主性。
以Oracle、MySQL为代表的传统关系型数据库管理系统,在企业应用中占据了重要的地位。如何从异构的Oracle、MySQL等数据库将存量的数据迁移至国产数据库,是企业技术升级和国产化战略中不可或缺的一环。
以一个离线场景为例,通常以“可行性评估”→“方案设计”→“迁移实施”→“割接上线”四个步骤来完成一整个迁移过程。

图1 数据库离线迁移步骤
需要注意的是,在做离线迁移过程中,业务需要停机,等待迁移完成、割接清楚,再次上线。
02数据库迁移的要点
在迁移链路中,我们通常关注以下五大维度:
维度一:迁移评估
首先需要考虑迁移前对源端库和目标库的兼容性评估,这是为了判断数据及元数据能否迁移,以及二者兼容性如何?有多少对象是不兼容的。
对于异构数据库之间的迁移,数据库对象兼容性是一个非常重要的问题。即使目标库对源端库有较好的兼容性,但是因为架构的不同,在一些数据对象、数据类型等方面难免存在差异。
同时为了使表、索引、视图、触发器、序列、函数、包、存储过程、物化视图、同义词、自定义类型、DBLink等复杂对象能够完整、准确的迁移,我们会需要迁移工具具备强大的评估功能,能识别并解决潜在的兼容性问题。
此外,另一个重要的环节是在迁移工作正式展开之前,能够对整体迁移过程所需的时间进行较为精确的预估。
维度二:语法转换
第二个维度就是语法的转换,该维度是上一个维度的延伸。当遇到不兼容的对象时,能够有途径进行修改,甚至是自动完成转换。
这里我们一般认为兼容能力上可以分为3个层级,第一是原生兼容,比如源库的DDL不需要任何修改就可以直接在目标库进行使用。第二是自动转换后的兼容,即不需要人工介入,工具能帮助做一些语法的转换。第三则是手动的兼容,这个就是我们结合业务判断需要手动修改的部分。
维度三:高性能迁移
通常做数据库替换时,需要停掉业务系统对外的服务,所以一般时间窗口有限,要求迁移工具具备高效的数据传输能力,能够在短时间内完成迁移任务,尽量减少对业务连续性的干扰。
维度四:数据一致性校验
对于在数据迁移后怎么确保目的库的数据和源数据是否一致的问题,还需要对迁移后的数据进行全面、准确的校验,确保数据的一致性、完整性,确保迁移质量。
维度五:通用性和易用性
如果是针对一次迁移场景来编写大量的脚本,做定制化方案的成本比较高,且难以复用。因此,通过不断实践积累并提炼宝贵的经验与流程,确保迁移方案既具备通用性又易于使用,是尤为重要的。
常用的迁移手段
YashanDB在进行Oracle、MySQL等异构数据库迁移到YashanDB时,主要采用以下两种常用迁移手段:
01使用YashanDB自带的工具,如yasldr
先采用源库导出工具导出成csv,再使用YashanDB官方导入工具yasldr导入:
- 优势1:高度灵活性。无须关注源库,只需要导出成csv文件;
- 优势2:资源最大化利用。可灵活调整导出/导入进程配比,资源利用最大化;
- 不足:自带的工具可能无法完全自动化处理复杂的DDL差异和数据类型的映射,需要需要用户手动干预或编写脚本。虽然在操作上较为直观,但在界面友好性、任务调度、错误处理、进度监控等方面无法满足需求。
02 使用开源工具,如Kettle、DBeaver等进行迁移
采用ETL工具(如Kettle)或IDE工具(如DBeaver)的数据迁移:
- 优势:易用性高。对于端到端迁移,不需要序列化与落盘,格式兼容性比文件导入导出要更好;
- 不足:一是Kettle无法迁移表结构、每张表都需要单独配置;二是开源工具通常针对各类数据库提供通用解决方案,对于具体的端到端数据库兼容支持上需要用户投入大量时间和精力进行定制化调整,比如特殊类型的适配,大对象的支持(较大LOB导致内存溢出)。
鉴于上述两种常用手段存在的局限性,YashanDB依据迁移链路中五大关键维度的实际经验,推出了更好用、更易用,且可复用、易追溯的迁移方案——采用崖山迁移平台(Yashan Migration Platform,YMP)迁移。
产品已在官网 下载中心开放下载
YMP迁移方案及特性
崖山迁移平台YMP支持Oracle、MySQL等数据库到YashanDB的迁移评估、离线迁移、数据校验的能力。同时YMP提供可视化服务,用户只需通过简单的界面操作,即可完成从评估到迁移到校验整个流程的执行与监控,轻松实现低门槛、低成本、高效率的异构数据库迁移实施。
YMP五大关键特性
01 精准评估

图2 YMP评估流程图
YMP的评估流程大致如下:从源端采集元数据,然后根据预设好的规则,进行语法的转换,在YashanDB内置库进行回放模拟,如果有不兼容的语句提供改写和改写后再次验证的能力,最后输出评估报告。
YMP对评估覆盖的对象范围较广,包括但不限于:表、索引、视图、触发器、序列、函数、包等。
对于评估的准确性,市面上大部分的工具做评估的时候都会采取预设好的规则来进行判断,但是YMP除了实现上面的功能外,还会把规则应用后的语句在YMP的内置YashanDB数据库进行模拟执行,内置库可以用于模拟评估的库和最终迁移的目标库版本是否一致,使用起来既保证了评估结果的正确性又比较灵活。
为了保障规则转换评估语句的可靠性,YMP在真正执行元数据对象迁移前,就已经在相同版本的内置库执行了一次,并模拟出真实环境执行的结果,最大程度降低迁移时的兼容性风险。
02 SQL自动转换
YMP支持将源库的SQL语句智能转换成YashanDB的SQL语句。它的原理是将源库的SQL解析成语法树然后根据词法、语法转换规则转换成目标库的语法树,最后对短语进行重组,输出目标库的SQL语句。
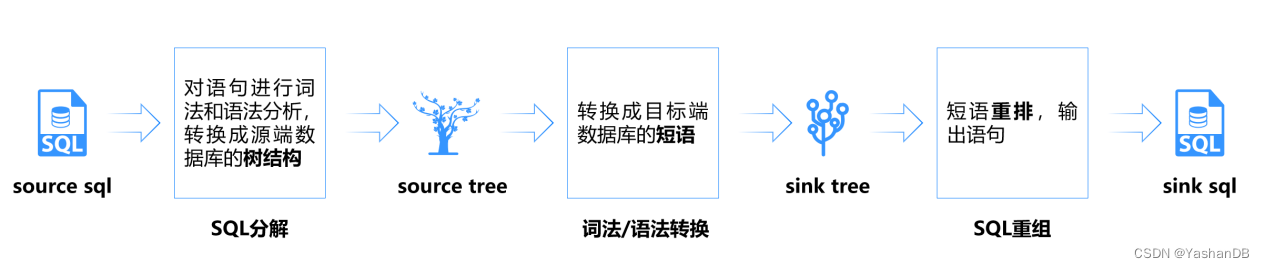
图3 YMP语法转换步骤图
对于转换过程中无法自动转换的语法,YMP提供了修改窗口,可以进行手动的编辑和验证。
下面以一个实际的数据库系统迁移为例:总共评估对象3587个,其中原生兼容的对象有2912个,占比81.18%,自动兼容的有675个,占比18.82%;整体兼容率达到100%。
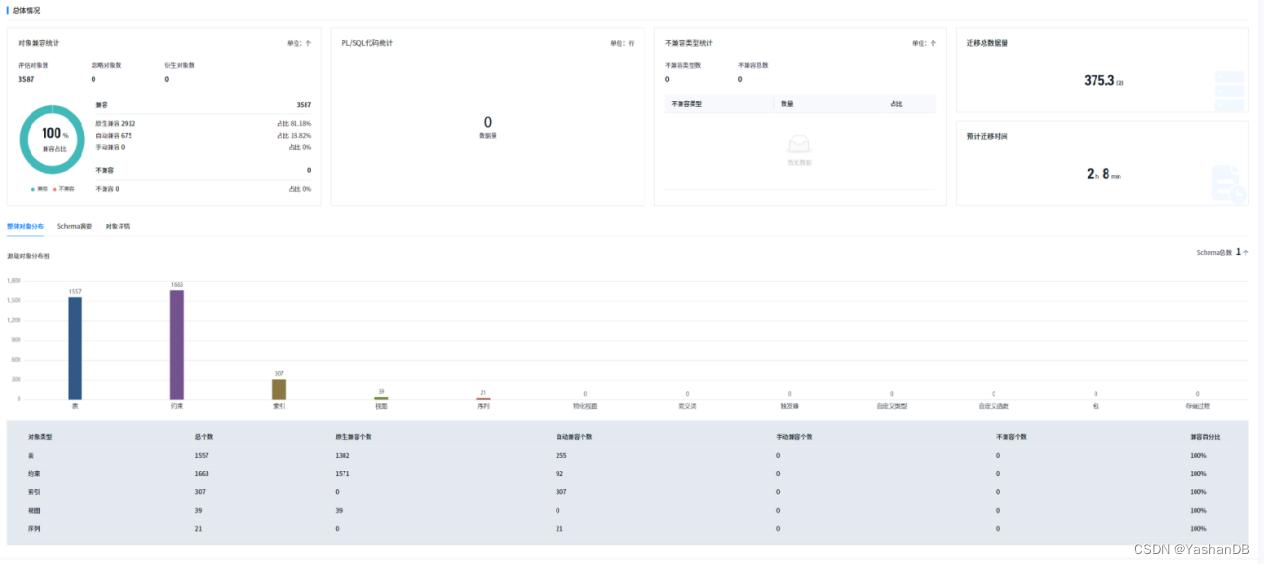
图4 YMP迁移评估报告
03 对象智能迁移
YMP支持一键整合所有对象元数据迁移,采用端到端性能最优的执行策略。
- 元数据分段迁移:合理编排迁移顺序,优化性能;
- 对象依赖梳理:评估时从源库获取对象依赖关系,对象间依赖关系正确不遗漏;
- 并行参数优化:支持针对索引、约束等在大数据量下迁移耗时较大的对象设置并行度等优化参数。
04 数据高性能迁移
YMP基于数据库原生高性能导入导出能力,采用流水线多级并行方式,实现高性能数据迁移。满足大规模数据迁移的性能需求,减少迁移时间。
- 满足大数据量场景的迁移性能要求(100MB~1GB/s);
- 灵活调整两端读、写任务配比,实现资源利用最大化;
- 特殊类型做针对性适配,例如对较大LOB,支持分段迁移,避免内存溢出。
图5 YMP高性能迁移总架构
05 灵活校验
YMP支持多种不同校验方式,包括全量校验和统计校验,范围上能一次选择整库或者批量选择对象来校验,来确保数据一致性和完整性。
- 全量校验:抽取两端的数据,遍历全表逐行比对,这样可以完整地校验所有数据,当然,在数据量较大的情况下,它的耗时也会相较更多;
- 统计校验:更轻量级的校验,通过对比源库和目标库表的行数来快速确认数据是否完整。
崖山迁移平台YMP是YashanDB目前推荐的数据库迁移的解决方案,以标准化、流程化的步骤,高效稳定地完成数据迁移任务。接下来,我们将继续优化和完善YMP迁移平台的功能、性能和易用性,满足更多企业级的迁移需求。















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









