







1. Spark Streaming基础知识
Spark Streaming是spark核心API的一个扩展,可以实现高吞吐量、有容错机制的实时流数据处理。
支持多种数据源获取数据:Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,进行处理后保存在HDFS、DataBase等。

Spark Streaming将接收的实时流数据,按照一定时间间隔,对数据进行批次划分,交给Spark Engine引擎处理,最终得到一批批的结果。

Dstream可以看做一组RDDs,即RDD的一个序列
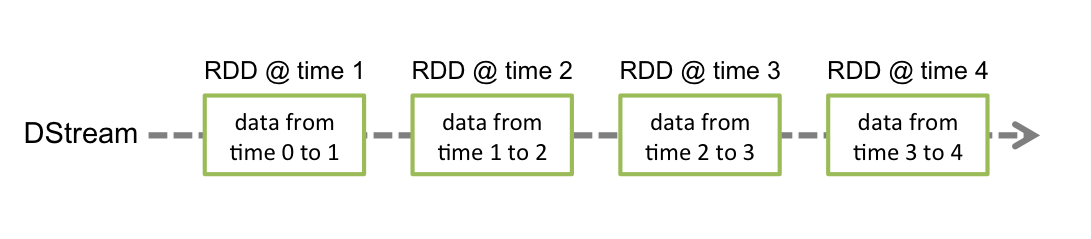
Dstream:Spark Streaming提供了表示连续数据流、高度抽象的被称为离散流的Dstream;
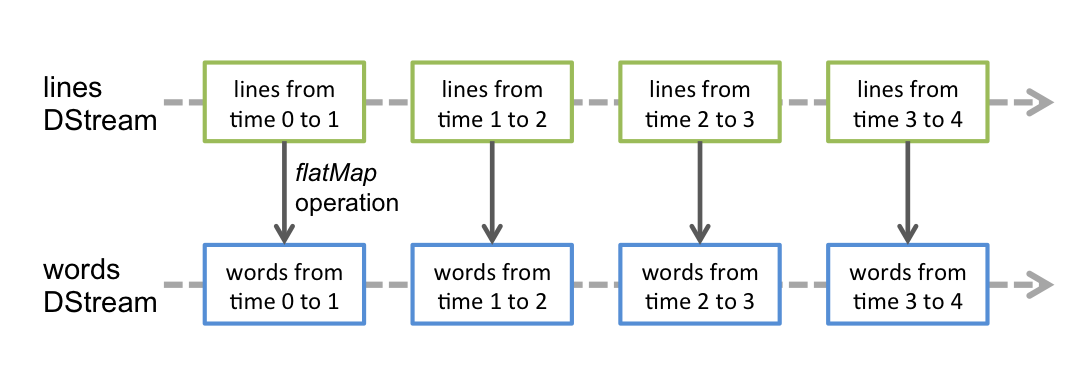
任何对Dstream的操作都会转变为对底层RDD的操作;
spark streaming任务的两个重要部分
- 一个静态的 RDD DAG 的模板,来表示处理逻辑;
- 一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD DAG 的实例,对数据片段进行处理;

我们在考虑的时候,可以认为,RDD 加上 batch 维度就是 DStream,DStream 去掉 batch 维度就是 RDD —— 就像 RDD = DStream at batch T。

Dstream之间的转换所形成的依赖关系全部保存在DstreamGraph中,DstreamGraph简化了DAG scheduler,去除了多余的关系,只保留有用的依赖关系。DstreamGraph是RDD Graph的模板。

整体架构由3个模块组成:
- Master:记录Dstream之间的依赖关系,并负责任务调度以生成新的RDD
- Worker:从网络接收数据并存储到executor 执行RDD计算
- Client:负责向Spark Streaming中传输数据

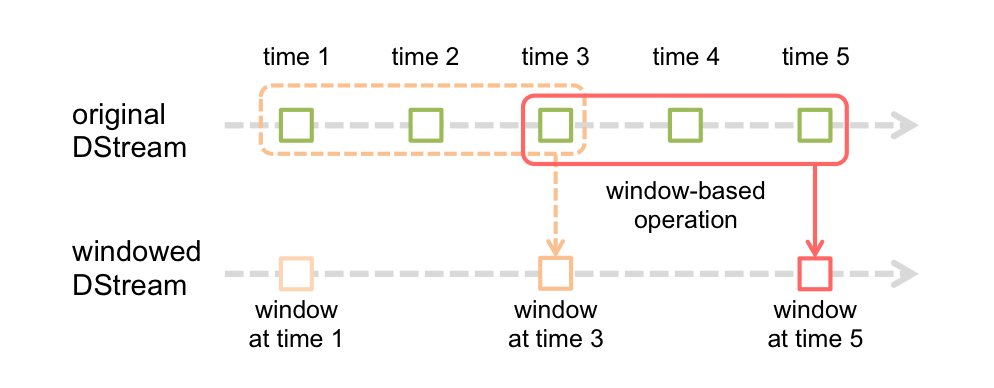
窗口操作
spark提供了一组窗口操作,通过滑动窗口技术对大规模数据的增量更新进行统计分析
Window Operation:定时进行一定时间段内的数据处理
全局统计量
全局统计量需要使用updataStateByKey算子,必须设置一个checkpoint目录,开启checkpoint机制以便在内存数据丢失的情况下可以从checkpoint中恢复数据。
2. 容错性
实时的流式处理系统必须是7*24运行的,同时可以从各种各样的系统错误中恢复,在设计之处,Spark Streaming就支持driver和worker节点的错误恢复。
- Worker容错:spark和rdd的设计保证了集群中worker节点的容错性。spark streaming构建在spark之上,所以它的worker节点也是同样的容错机制。
- Driver容错:依赖WAL机制持久化日志
2.1 Write Ahead Logs
WAL使用在文件系统和数据库中用于数据操作的持久性,先把数据写到一个持久化的日志中,然后对数据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。
值得注意的是WAL开启了以后会减少Spark Streaming处理数据的吞吐,因为所有接收的数据会被写到容错的文件系统上,这样文件系统的吞吐和网络带宽将成为瓶颈。
启动WAL需要做如下的配置
- 给streamingContext设置checkpoint的目录,该目录必须是Hadoop支持的文件系统hdfs,用来保存WAL和做Streaming的checkpoint
- spark.streaming.receiver.writeAheadLog.enable 设置为true (只有receiver方式才有WAL机制)
实现细节
下面讲解下WAL的工作原理。过一下Spark Streaming的架构
当一个Spark Streaming应用启动了(例如driver启动), 相应的StreamingContext使用SparkContet去启动receiver,receiver是一个长时间执行的作业,这些接收器接收并保存这些数据到Spark的executor进程的内存中,这些数据的生命周期如下图所示:

- 蓝色的箭头表示接收的数据,接收器把数据流打包成块,存储在executor的内存中,如果开启了WAL,将会把数据写入到存在容错文件系统的日志文件中
- 青色的箭头表示提醒driver, 接收到的数据块的元信息发送给driver中的StreamingContext, 这些元数据包括:executor内存中数据块的引用ID和日志文件中数据块的偏移信息
- 红色箭头表示处理数据,每一个批处理间隔,StreamingContext使用块信息用来生成RDD和jobs. SparkContext执行这些job用于处理executor内存中的数据块
- 黄色箭头表示checkpoint这些计算,以便于恢复。流式处理会周期的被checkpoint到文件中
当一个失败的driver重启以后,恢复流程如下

- 黄色的箭头用于恢复计算,checkpointed的信息是用于重启driver,重新构造上下文和重启所有的receiver
- 青色箭头恢复块元数据信息,所有的块信息对已恢复计算很重要
- 重新生成未完成的job(红色箭头),会使用到2恢复的元数据信息
- 读取保存在日志中的块(蓝色箭头),当job重新执行的时候,块数据将会直接从日志中读取,
- 重发没有确认的数据(紫色的箭头)。缓冲的数据没有写到WAL中去将会被重新发送。
2.2 checkpoint机制
Spark Streaming周期性的把应用数据存储在HDFS/S3这样的可靠存储系统中以供恢复时使用的机制被称为检查点机制
3. Spark Streaming接收数据的两种方式
3.1 Receiver-based Approach
Receiver-based的Kafka读取方式是基于Kafka高阶(high-level) api来实现对Kafka数据的消费。kafka数据流由Receiver来接收,首先读入到executor进程的memory中,开启WAL机制后数据会被预写持久化到日志中(HDFS)。然后将数据块的元信息发送到driver中,同样的,元信息会预写到HDFS中,streaming context会将Dstream Graph和元数据信息相结合转化为一个streaming任务逻辑任务并被checkpoint机制记录在本地文件系统HDFS中以保证容错性。接下来,streaming任务被转化为一个spark context任务,由底层的spark来执行,将spark任务发送到指定的worker上开始运行任务。存储在zookeeper中,由Receiver来维护。当通过WAL机制将数据成功预写到HDFS之后,Receivers会相应更新ZooKeeper的offsets。

3.2 Direct Approach
Direct方式采用Kafka简单的consumer api方式来读取数据,无需经由ZooKeeper,此种方式不再需要Receiver来持续不断读取数据。kafka看做一个底层文件系统,当batch数据的offsetRange(topic、partition、fromOffset、untilOffset)元数据传送给spark driver之后,batch任务被触发,由Executor使用pull模式拉取相应offset range范围的数据,并参与其他Executor的数据计算。offset由kafka自己来维护,driver来决定读取多少offsets,并将offsets交由checkpoints来维护。从此过程可以发现Direct方式无需Receiver读取数据,而是需要计算时再读取数据。

- Direct的方式直接操作kafka底层的元数据信息
- 由于直接操作的是kafka,kafka相当于底层的文件系统
- 由于底层是直接读数据,没有所谓的Receiver,直接是周期性的查询kafka,处理数据的时候,我们会使用基于kafka原生的Consumer api来获取kafka特定offset范围的数据
- 读取多少个kafka partition,Spark也会创建相应的RDD的partition。RDD的partition和kafka的partition是一一对应的。
- 不需要开启WAL机制,从数据丢失的角度来看,极大地提升了效率,节省磁盘空间。从kafka获取数据,比从hdfs获取数据,速度更快(zero-copy)

3.3 kafka partition和RDD的partition之间的关系
Receiver方式:Topic中partition负载均衡平均分配到读入到consumer group并将partition的数据读入到executor进程中,然后,为每一个partition分配一个或多个task线程
Direct方式:Topic中partition负载均衡平均分配到读入到consumer group。kafka partition和RDD的partition是一一对应关系。每一个partition由一个task线程来执行,相应的partition产生对应的offset,偏移量被记录在ZooKeeper。

Topic每一个partition对应的offset目录为:/consumers/group_test/offsets/badou/0

4. 从容错性角度分析
Receiver:失败的情况下,有些数据很可能会被不止一次的接收。接收的数据通过WAL机制被保存到HDFS中,但是还没来得及更新zookeeper中的对应partition的offset就发生故障,导致数据不一致性。streaming知道数据被接收,但是kafka认为数据没有被接收。当系统恢复正常时,kafka会重新发送这些数据。(at least once)
Direct:给出每个batch范围需要读取的偏移量,每个batch的job被运行时,对应offset range的数据会被拉取,数据处理完成后,offset信息被可靠地存储(checkpoint)。失败后重新恢复时可以直接读取这些偏移量信息。(exactly once)















 2320
2320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









