










持续分享:机器学习、深度学习、python相关内容、日常BUG解决方法及Windows&Linux实践小技巧。
如发现文章有误,麻烦请指出,我会及时去纠正。有其他需要可以私信我或者发我邮箱:zhilong666@foxmail.com
机器学习是目前科技领域中最热门的领域之一,其核心技术之一即为机器学习算法。人们经过长期的探索和研究,发现了许多有效的机器学习算法,其中kNN算法就是其中之一。
本文将详细讲解机器学习十大算法之一 “KNN”

目录
一、简介
KNN(k-nearest neighbors)算法是一种监督学习算法,也是机器学习中比较基础的算法之一。它主要应用于分类和回归。KNN算法的基本思想是在训练集中搜索k个距离测试样本最近的样本,并对这些邻居样本中的大多数进行分类或回归。KNN算法是一种非参数算法,不需要对数据分布进行任何假设,具有很强的鲁棒性和普适性。KNN算法可以用于图像识别、语音识别、推荐系统等常见的机器学习应用领域。
KNN算法在实际应用中具有很高的可扩展性,几乎可以应用于任何领域。由于它不需要复杂的模型和训练过程,因此KNN算法的很容易理解和实现,是入门机器学习的一个很好的选择。
二、发展史
KNN算法最初是由留日学者Fix在1962年提出的。当时,在统计学和模式识别领域,已经有其他一些基于实例的学习算法,如自组织映射(self-organizing map, SOM),但Fix认为这些算法并不完善,存在一些问题。他提出了一种改进的基于实例的算法,即KNN算法。
在KNN算法的提出后的几十年里,人们在KNN算法的基础上做了很多改进和扩展。其中最重要的一次改进是在1991年,Cover和Hart发表了《Nearest Neighbor Pattern Classification》一文,提出了KDT(k-dimensional tree)和LRU(least recently used)两个算法,去加速KNN算法的速度,并且证明:KNN算法在处理高维度的数据时,其速度会非常慢,而使用KDT和LRU,可以大大提高算法的效率。
三、算法公式
KNN算法的数学表达式非常简单。它的核心思想是寻找离测试样本最近的k个训练数据点,并基于这些邻居的信息进行分类或回归预测。根据不同的问题,KNN算法有不同的公式表达方式。
对于KNN分类问题,假设测试样本为x,其所属类别为y,训练样本为(xi,yi)∣i=1,2,...,N。则KNN算法的数学表达式如下:
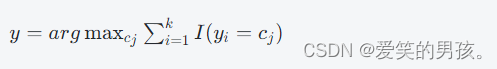
其中,cj代表候选类,k代表近邻的个数,I为指示函数。在KNN算法中,我们通常使用欧几里德距离来衡量两个数据点之间的距离。假设xi和xj是两个数据点,我们可以使用以下公式计算它们之间的距离:

其中,d代表数据维度。
对于KNN回归问题,假设测试样本为x,其真实值为y,训练样本为(xi,yi)∣i=1,2,...,N。则KNN算法的数学表达式如下:

其中,k代表近邻的个数。
四、算法原理详解
KNN算法的基本原理是“近朱者赤,近墨者黑”,即利用相似对象的分类结果推断新对象的分类。具体来说,KNN算法分为以下几个步骤:
1.获取数据集:包含了训练数据和测试数据;
2.计算距离:通过不同的距离函数计算新对象与训练数据之间的距离;
3.确定K值:K指的是在距离最近的K个数据对象中,占比最多的标签代表新对象的标签。K的大小是一个超参数,需要在算法中设定;
4.分类预测:根据最后统计出的K中标签的占比,得出新对象的预测标签。
其中,距离函数的选择是KNN的核心问题。常用距离函数包括欧氏距离、曼哈顿距离、明可夫斯基距离等。具体的距离计算方法如下:
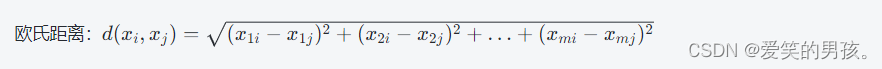
其中,xi和xj分别是两个数据对象,m为数据属性个数。
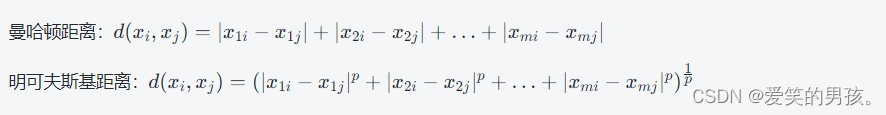
其中,p为一个超参数,当p=1时为曼哈顿距离,p=2时为欧氏距离。
五、算法功能详解
KNN算法主要包括KNN分类和KNN回归两种算法。接下来具体讲解这两种算法的功能。
1. KNN分类算法
在KNN分类算法中,给定一个测试样例,该算法会在训练集中寻找和测试样例距离最近的K个训练样例。通过统计这K个样例的类别,KNN算法最终将测试样例归入其中出现最多的类别中。
KNN分类算法的工作流程如下:
- 首先,将新的数据点标记为要预测的类别;
- 然后,计算新的数据点和训练数据集中每个数据点之间的距离;
- 选取距离最近的K个训练数据点,并找出它们的类别;
- 统计这K个数据点中各类别出现的次数;
- 返回出现次数最多的类别作为预测结果。
2. KNN回归算法
KNN回归算法与KNN分类算法的区别在于:
- 在KNN回归算法中,给定一个测试样例x,该算法寻找和测试样例距离最近的K个训练样例,并假设这K个训练样例的输出为y1,y2,…,yk;
- KNN回归算法使用这K个训练样例的输出变量的平均值来预测测试样例的输出变量。
KNN回归算法的工作流程如下:
- 首先,将新的数据点标记为要预测的目标变量;
- 然后,计算新的数据点和训练数据集中每个数据点之间的距离;
- 选取距离最近的K个训练数据点;
- 计算这K个数据点目标变量的平均值;
- 返回平均值作为预测结果。
3. KNN算法的优缺点
KNN算法的优点:
1、无需训练时间,训练效果好;
2、适用于各类数据源,可以用来解决许多问题;
3、准确率高,尤其应用于简单分类问题时效果很好。
KNN算法的缺点:
1、计算量大,在处理大数据时速度会变慢;
2、决策不可解释;
3、对数据维数较高时,容易出现维数灾难问题。
六、示例代码
1. KNN分类算法
使用sklearn库实现KNN分类算法,以鸢尾花(iris)数据集为例:
# -*- coding: utf-8 -*-
# 引入所需的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
# 分割数据集,划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
# 定义KNN分类器
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
运行结果:Accuracy: 0.9666666666666667
2. KNN回归算法
使用sklearn库实现KNN回归算法,以波士顿房价(boston)数据集为例:
# -*- coding: utf-8 -*-
# 引入所需的库
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
# 分割数据集,划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2)
# 定义KNN回归器
knn = KNeighborsRegressor(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算均方差(MSE)
mse = mean_squared_error(y_test, y_pred)
print("MSE:", mse)
运行结果:MSE: 36.23794117647059
以上代码示例中,均采用默认的距离度量算法(欧式距离),实际应用中可以根据具体情况选择其他距离度量算法。
七、总结
KNN算法是一种简单而有效的算法,可以用于各种分类和回归问题。它的核心思想是找到距离测试数据最近的k个训练数据点,然后使用它们的标签或真实值来预测未知的标签或值。在KNN算法中,我们使用欧几里德距离来衡量数据点之间的距离。在处理大型数据集时,KNN分类和回归问题的计算复杂度比较高,因为需要计算测试数据与每个训练数据点的距离。但是,KNN算法的简单性和可解释性,以及良好的准确性,在实际应用中,使其成为一个重要的算法。

















 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











