







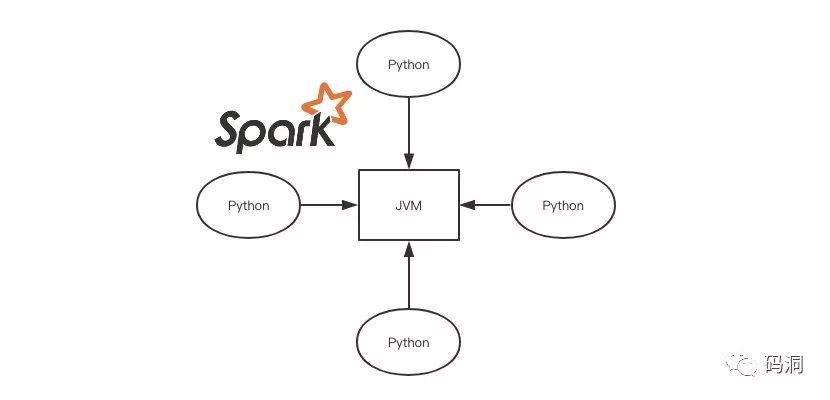
我们知道Spark平台是用Scala进行开发的,但是使用Spark的时候最流行的语言却不是Java和Scala,而是Python。原因当然是因为Python写代码效率更高,但是Scala是跑在JVM之上的,JVM和Python之间又是如何进行交互的呢?
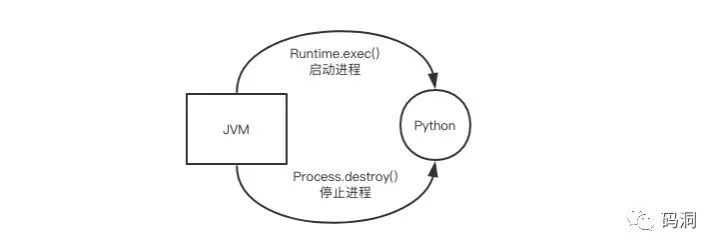
在实际运行过程中,JVM并不会直接和Python进行交互,JVM只负责启停Python脚本,而不会向Python发送任何特殊指令。启动脚本同执行外部任意进程的方法是一样的,就是调用Runtime.exec(command)生成python子进程。停止Python进行就是调用Process.destroy()和Process.destroyForcibly()杀死子进程,destroy方法使用SIGTERM信号通知Python进程主动退出,如果Python一段时间不响应,就会使用destroyForcibly方法发送SIGKIL信号强制杀死Python进程。
Pyspark玄妙的地方在于Python在运行的过程中需要调用Spark的API,这些API的实现在JVM虚拟机里面,也就是说python脚本运行的进程同Spark的API实现不在一个进程里,当我们在Python里面调用SparkAPI的时候,实际的动作执行确是在JVM里面,这是如何做到的?
答案就是远程过程调用,也就是我们经常听到的词汇RPC。
在Pyspark中,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









