






大家好,我是鸭鸭!
这个面试题就是count(*) 、count(1)和count(字段名)的区别!很多同学可能都背过,但是一段时间过后又忘了,这次让我们一起记住它!
此答案节选自鸭鸭最近弄的✏️ 面试刷题神器:面试鸭 ,更多大厂常问面试题,可以点击下面的小程序进行阅读哈!
我们回到面试题上,在 MySQL 中,count(*) 、count(1)和count(字段名) 都是用来统计行数的聚合函数,但它们有些许的区别,我们先从功能和效率两个方面来进行分析。
功能上
1)count(*) 会统计表中所有行的数量,包括 null 值(不会忽略任何一行数据)。由于只是计算行数,不需要对具体的列进行处理,因此性能通常较高。
2)count(1) 和 count(*) 几乎没差别,也会统计表中所有行的数量,包括 null 值。
3)count(字段名) 会统计指定字段不为 null 的行数。这种写法会对指定的字段进行计数,只会统计字段值不为 null 的行。
效率上:
关于这个效率,网上众说纷纭,公说公有理婆说婆有理。
记住啦!count(1) 和 count(*) 效率一致,依据是什么呢?
让我们看官网!
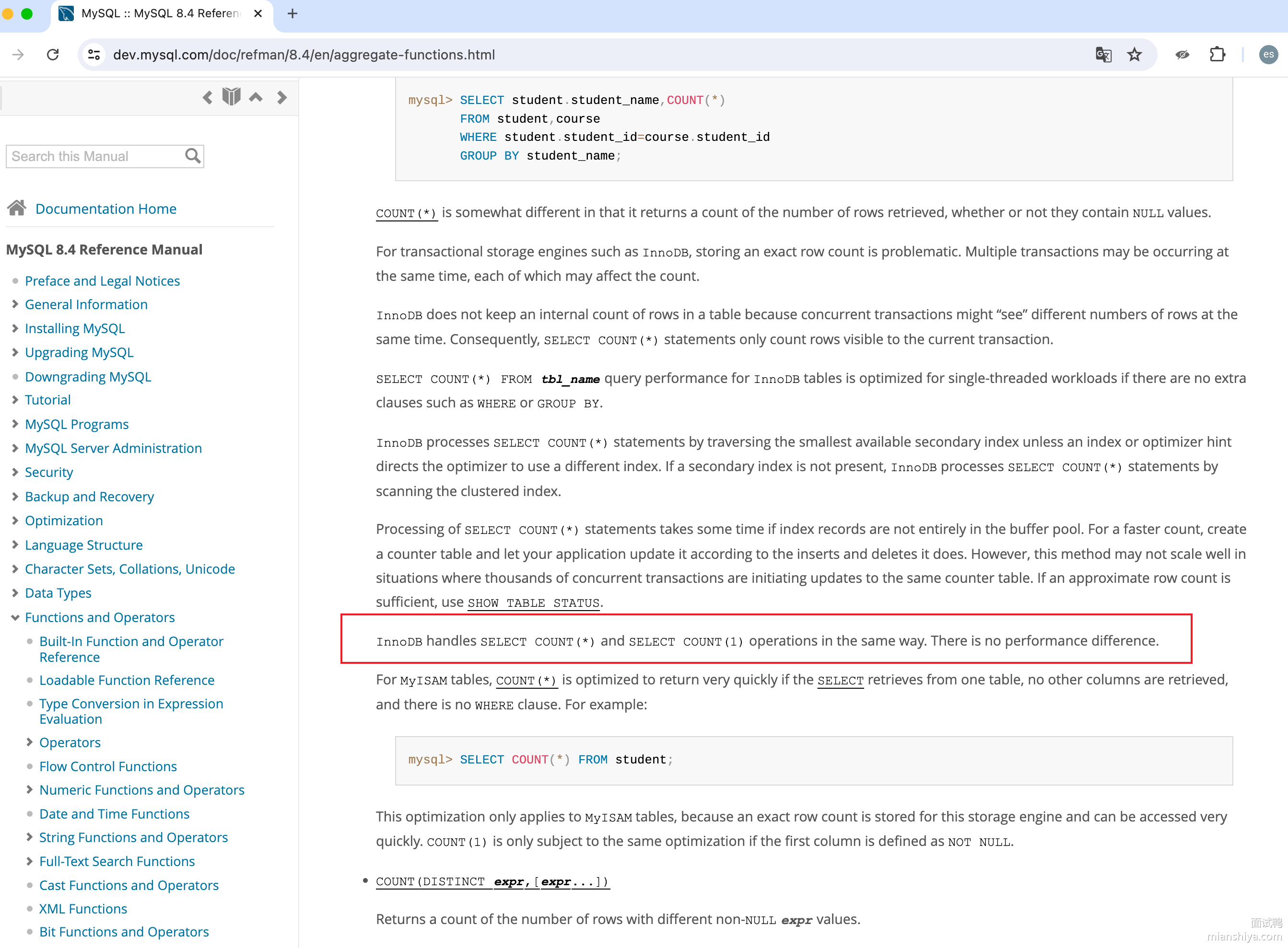
大家看到没?There is no performance difference. 没有差异的!
至于 count(字段) 的查询其实就是全表扫描。
正常情况下它还需要判断字段是否是 null 值,因此理论上会比 count(1) 和 count(*) 慢。
所以我们就得到这个公式: count(*) = count(1) count(字段) 。
但是!
如果字段不为 null,例如是主键,那么理论它们的效率也差不多。
而且本质上它们的统计功能不一样,在需要统计 null 的时候,只能用 count(1) 和 count(*),不需要统计 null 的时候只能用count(字段),所以也不用太纠结性能问题。
不同引擎的区别
一般情况下,我们谈论 MySQL 默认指的是 InnoDB 引擎。但是别忘了它还有 MyISAM 呢,所以在面试过程中,我们还需要向面试官提一嘴不同引擎的实现,这就叫啥?

在 MyISAM 中,由于只有表锁,因此它把每张表的总数单独记录维护(表锁使得对表的修改是串行,因此能维护总数),所以 count(*) 非常快,因为等于直接返回一个字段。当然,前提是不需要条件过滤而是直接返回整表数据。
而 InnoDB 由于支持行锁,所以会有很多并发来修改表的数据,因此无法维护记录总数,但是 InnoDB 对count(*)和count(1)也做了一定的优化。
count 需要扫描全表,如果扫的是主键索引,由于主键索引保存的是整行记录,占据的空间和内存都比较大,此时选择二级索引扫描则成本会更低。
因此 InnoDB 会评估这个成本选择合适的索引扫描。当然,这个前提也是不能有对应的条件过滤等功能。
最后
最后最近鸭鸭整了一个✏️ 面试刷题神器:面试鸭 ,已经有近 1500 道面试题目啦,欢迎大家来阅读!如果大家有不会的面试题,也可以在小程序内反馈!鸭鸭会第一时间为大家解答!
我是鸭鸭,我们下期见~















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









