






2024秋招又开始了,相信忙着找工作的同学都没忘记要背面试题。
那么,java 基础, Java 集合、Java 并发编程,JVM,Spring ,SpringBoot,微服务, Kafka ,分布式,Redis ,分布式事务,设计模式,算法,数据结构,MySQL ……这么多相关内容,你都背熟了吗?
我们整理了49道必背的Java面试题,并附上了详尽题解。需要扩展知识点和阅读其他知识题库的同学,欢迎使用我们的 面试鸭 ,现在已经有4000多道面试题了!网页和小程序双端都可以刷题!
我们接着上篇内容,继续刷题!
26.什么是 Java 泛型的上下界限定符?
上界限定符是 extends ,下界限定符是 super
<? extends T> 表示类型的上界,?这个类型要么是 T ,要么是 T 的子类
下面就是一个典型的例子:
// 定义一个泛型方法,接受任何继承自Number的类型
public <T extends Number> void processNumber(T number) {
// 在这个方法中,可以安全地调用Number的方法
double value = number.doubleValue();
// 其他操作...
}
<? super T> 表示类型的下界(也叫做超类型限定),?这个类型是 T 的超类型(父类型),直至 Object
下面也是一个典型的例子:
// 定义一个泛型方法,接受任何类型的List,并向其中添加元素
public <T> void addElements(List<? super T> list, T element) {
list.add(element);
// 其他操作...
}
我们在使用上下界通配符的时候,需要遵循 pecs 原则,即Producer Extends, Consumer Super;上界生产,下界消费。
什么意思呢?
如果要从集合中读取类型 T 的数据,并且不能写入,可以使用 ? extends 通配符;(Producer Extends),如上面的 processNumber 方法,我们是要从方法中得到 T 类型,也就是方法给我们生产。
如果要从集合中写入类型 T 的数据,并且不需要读取,可以使用 ? super 通配符;(Consumer Super),如上面的 addElements 方法,我们是要往方法中传入 T 类型,也就是方法帮我们消费。
27. Java 中的深拷贝和浅拷贝有什么区别?
深拷贝:完全拷贝一个对象,包括基本类型和引用类型,堆内的引用对象也会复制一份。
浅拷贝:仅拷贝基本类型和引用,堆内的引用对象和被拷贝的对象共享。
所以假如拷贝的对象成员间有一个 list,深拷贝之后堆内有 2 个 list,之间不会影响,而浅拷贝的话堆内还是只有一个 list。
比如现在有个 teacher 对象,然后成员里面有一个 student 列表。
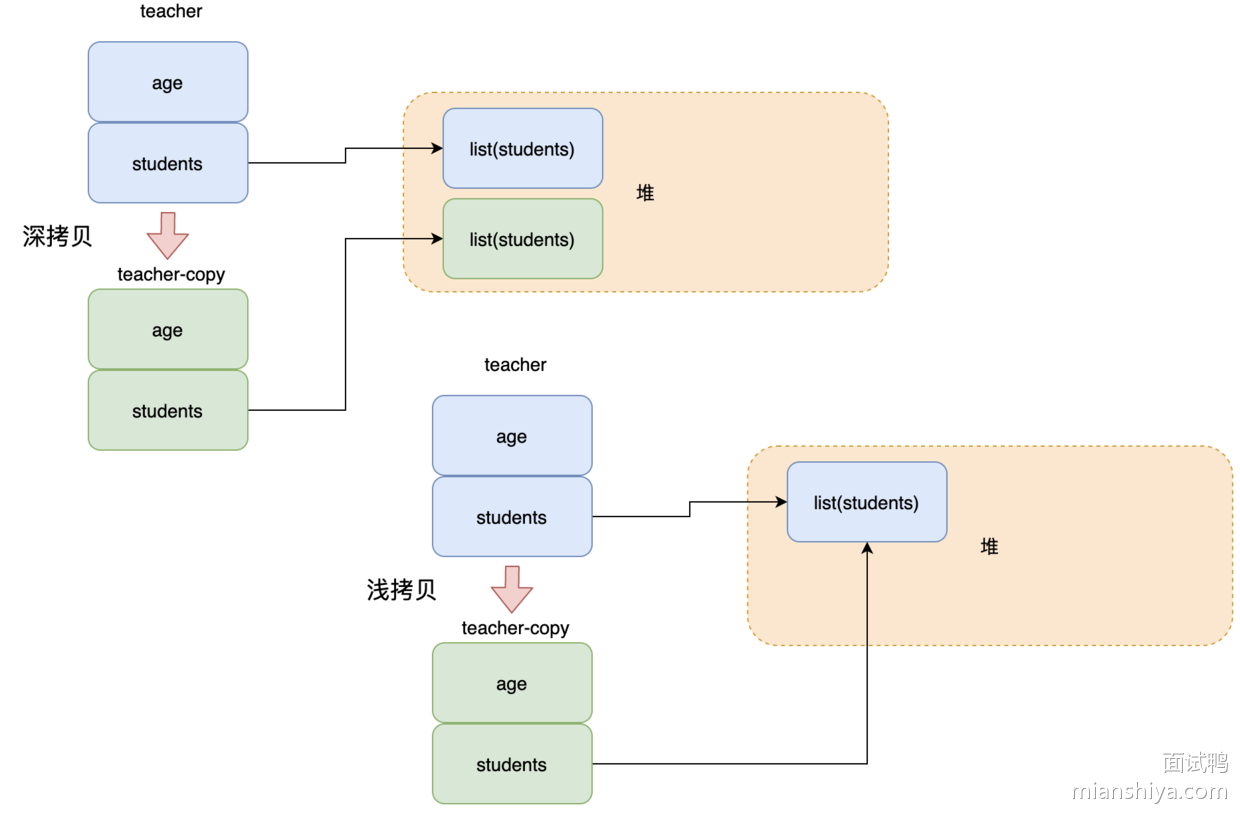
因此深拷贝是安全的,浅拷贝的话如果有引用对象则原先和拷贝对象修改引用对象的值会相互影响。
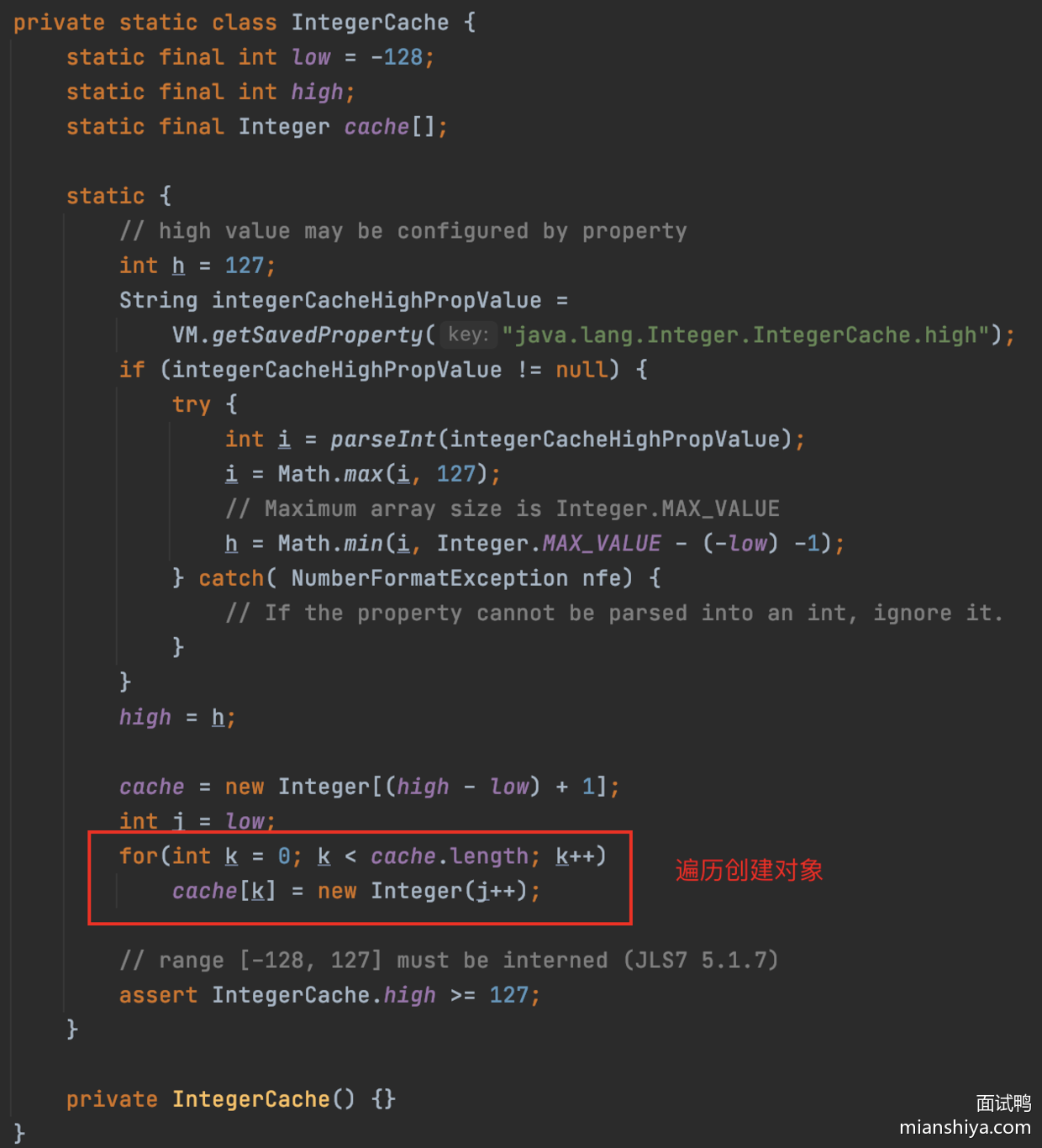
28.什么是 Java 的 Integer 缓存池?
根据实践发现大部分的数据操作都集中在值比较小的范围,因此 Integer 搞了个缓存池,默认范围是 -128 到 127,可以根据通过设置 JVM-XX:AutoBoxCacheMax=<size> 来修改缓存的最大值,最小值改不了。
实现的原理是int 在自动装箱的时候会调用Integer.valueOf,进而用到了 IntegerCache。

判断下值是否在范围之内,如果是的话去 IntegerCache 中取。
IntegerCache 在静态块中会初始化好缓存值。
29. Java的类加载过程是怎样的?
类加载顾名思义就是把类加载到 JVM 中,而输入一段二进制流到内存,之后经过一番解析、处理转化成可用的 class 类,这就是类加载要做的事情。
二进制流可以来源于 class 文件,或者通过字节码工具生成的字节码或者来自于网络都行,只要符合格式的二进制流,JVM 来者不拒。
类加载流程分为加载、连接、初始化三个阶段,连接还能拆分为:验证、准备、解析三个阶段。
所以总的来看可以分为 5 个阶段:
- 加载:将二进制流搞到内存中来,生成一个 Class 类。
- 验证:主要是验证加载进来的二进制流是否符合一定格式,是否规范,是否符合当前 JVM 版本等等之类的验证。
- 准备:为静态变量(类变量)赋初始值,也即为它们在方法区划分内存空间。这里注意是静态变量,并且是初始值,比如 int 的初始值是 0。
- 解析:将常量池的符号引用转化成直接引用。符号引用可以理解为只是个替代的标签,比如你此时要做一个计划,暂时还没有人选,你设定了个 A 去做这个事。然后等计划真的要落地的时候肯定要找到确定的人选,到时候就是小明去做一件事。解析就是把 A(符号引用) 替换成小明(直接引用)。符号引用就是一个字面量,没有什么实质性的意义,只是一个代表。直接引用指的是一个真实引用,在内存中可以通过这个引用查找到目标。
- 初始化:这时候就执行一些静态代码块,为静态变量赋值,这里的赋值才是代码里面的赋值,准备阶段只是设置初始值占个坑。
30.什么是 Java 的 BigDecimal ?
BigDecimal 是 Java 中提供的一个用于高精度计算的类,属于 java.math 包。它提供对浮点数和定点数的精确控制,特别适用于金融和科学计算等需要高精度的领域。
主要特点:
- 高精度:BigDecimal 可以处理任意精度的数值,而不像 float 和 double 存在精度限制。
- 不可变性:BigDecimal 是不可变类,所有的算术运算都会返回新的 BigDecimal 对象,而不会修改原有对象(所以要注意性能问题)。
- 丰富的功能:提供了加、减、乘、除、取余、舍入、比较等多种方法,并支持各种舍入模式。
通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
《阿里巴巴 Java 开发手册》中提到:浮点数之间的等值判断,基本数据类型不能用 == 来比较,包装数据类型不能用 equals 来判断。
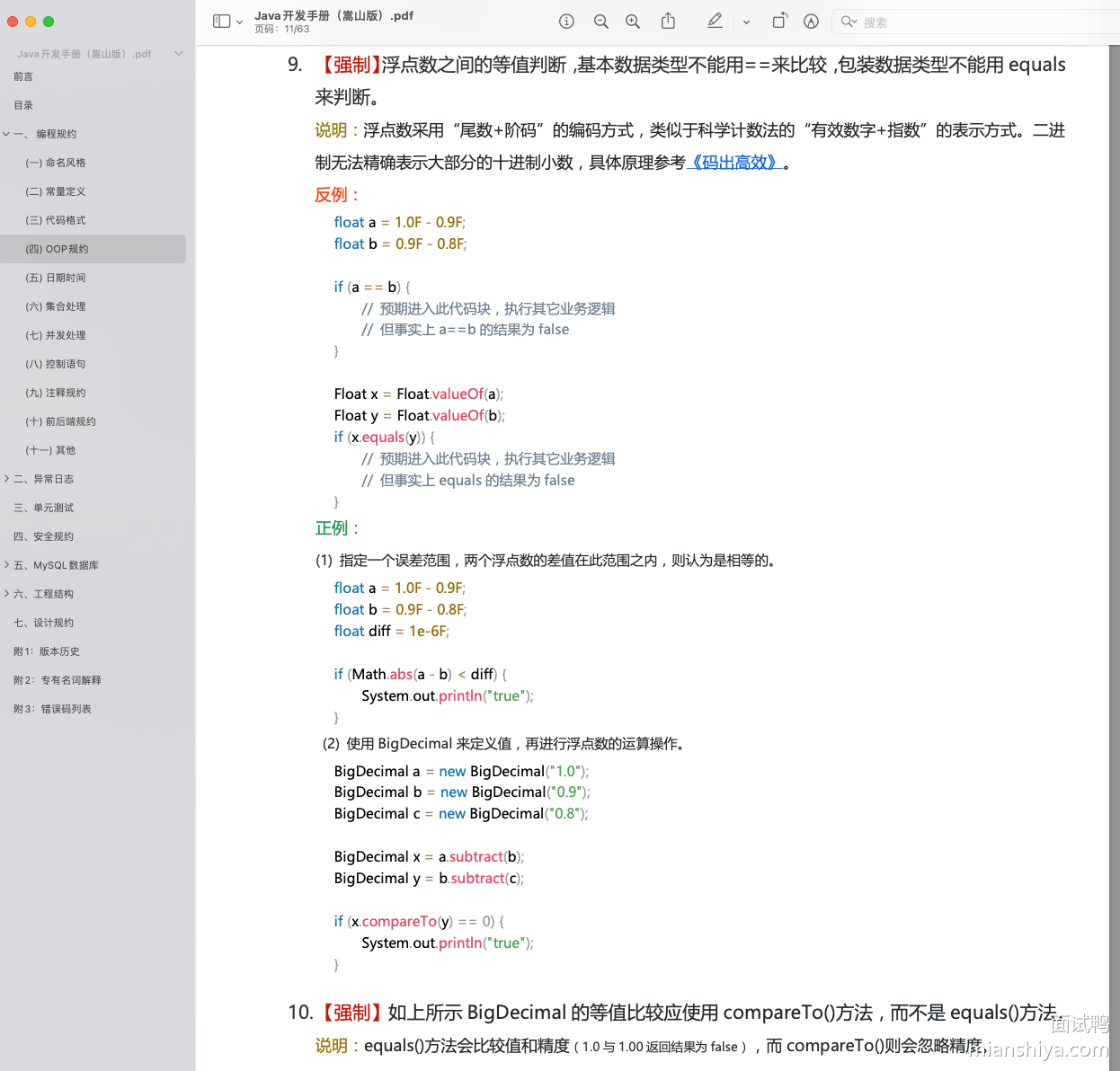
想要解决浮点数运算精度丢失这个问题,可以直接使用 BigDecimal 来定义浮点数的值,然后再进行浮点数的运算操作即可。
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(b);
BigDecimal y = b.subtract(c);
System.out.println(x.compareTo(y));// 0
31.使用 new String(“yupi”) 语句在 Java 中会创建多少个对象?
会创建 1 或 2 个字符串对象。
主要有两种情况:
1、如果字符串常量池中不存在字符串对象“yupi”的引用,那么它会在堆上创建两个字符串对象,其中一个字符串对象的引用会被保存在字符串常量池中。
示例代码(JDK 1.8):
String s = new String("yupi");
对应的字节码:

ldc 命令用于判断字符串常量池中是否保存了对应的字符串对象的引用,如果保存了的话直接返回,如果没有保存的话,会在堆中创建对应的字符串对象并将该字符串对象的引用保存到字符串常量池中。
2、如果字符串常量池中已存在字符串对象“yupi”的引用,则只会在堆中创建 1 个字符串对象“yupi”。
示例代码(JDK 1.8):
// 字符串常量池中已存在字符串对象“yupi”的引用
String s1 = "yupi";
// 下面这段代码只会在堆中创建 1 个字符串对象“yupi”
String s2 = new String("yupi");
对应的字节码:
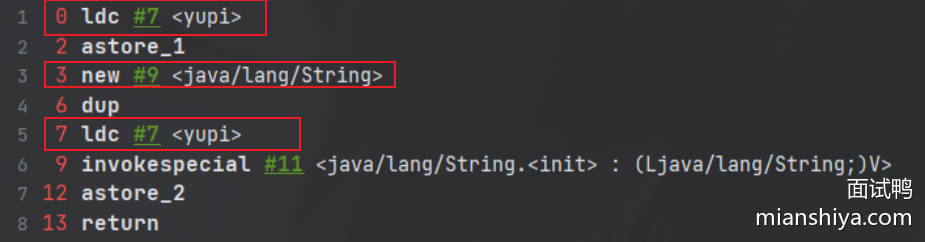
这里的过程与上面差不多,7 这个位置的 ldc 命令不会在堆中创建新的字符串对象 “yupi”,这是因为 0 这个位置已经执行了一次 ldc 命令,已经在堆中创建过一次字符串对象 “yupi” 了。 7 这个位置执行 ldc 命令会直接返回字符串常量池中字符串对象“yupi”对应的引用。
32. Java 中 final 、finally 和 finalize 各有什么区别?
- final:用于类、方法和变量,表示不可改变或不可继承。
- finally:用于 try-catch 块中,无论是否抛出异常,finally 块中的代码总会执行。
- finalize:是 Object 类中的方法,供垃圾收集器在回收对象之前调用,但由于其局限性和不确定性,不推荐使用。
扩展:final
final 是一个关键字,其可以用来修饰变量、方法以及类等,被修饰之后的部分不可变、不可以被重写或者不可以被继承。
扩展:finally
finally 是主要应用于异常处理,它经常和try、catch块一起搭配使用。无论是否捕获或处理异常,finally 块中的代码总是会执行(程序正常执行的情况)。通常用于关闭资源,如输入/输出流、数据库连接等。
try {
// 可能产生异常的代码
} catch (Exception e) {
// 异常处理代码
} finally {
// 正常情况下总是执行的代码块,常用于关闭资源
}
扩展:finalize
finalize 是 Object 类的一个方法,用于垃圾收集过程中的资源回收。在对象被垃圾收集器回收之前,finalize 方法会被调用,用于执行清理操作(例如释放资源)。然而,finalize 方法已经被弃用,且不推荐使用,因为它不保证及时执行,并且其使用可能导致性能问题和不可预测的行为。
protected void finalize() throws Throwable {
// 在对象被回收时执行清理工作
}
33.为什么在 Java 中编写代码时会遇到乱码问题?
很多人在编程的时候,都会遇到乱码问题。
那为什么会这样呢?
先了解下什么是编解码:
- 编码:将字符按照一定的格式转换成字节流的过程。
- 解码:就是将字节流解析成字符。
用专业的术语来说,乱码是因为编解码时使用的字符集不一致导致的。比如你将字符利用 UTF-8 编码后,传输给别人,然后这个人用 GBK 来解码,那解出来的不就是乱码吗?
就好比加密算法和解密算法对不上,那解出来的不就是一堆乱七八糟的东西。
那为什么要需要编解码呢?
因为计算机底层的存储都是 0101,它可不认识什么字符。所以我们需要告诉计算机什么数字代表什么字符。
比如告诉它 0000 代表 面试,0001 代表 鸭 ,这样我输入 0000 0001 后,计算机就可以展示面试鸭三个字了。
这样的一套对应规则就是字符集,所以编解码用的字符集不同,就会导致乱码。
扩展:标准字符编码
ASCII 是美国国家标准协会 ANSI 就制定的一个标准规定了常用字符集的集合和对应的数字编号
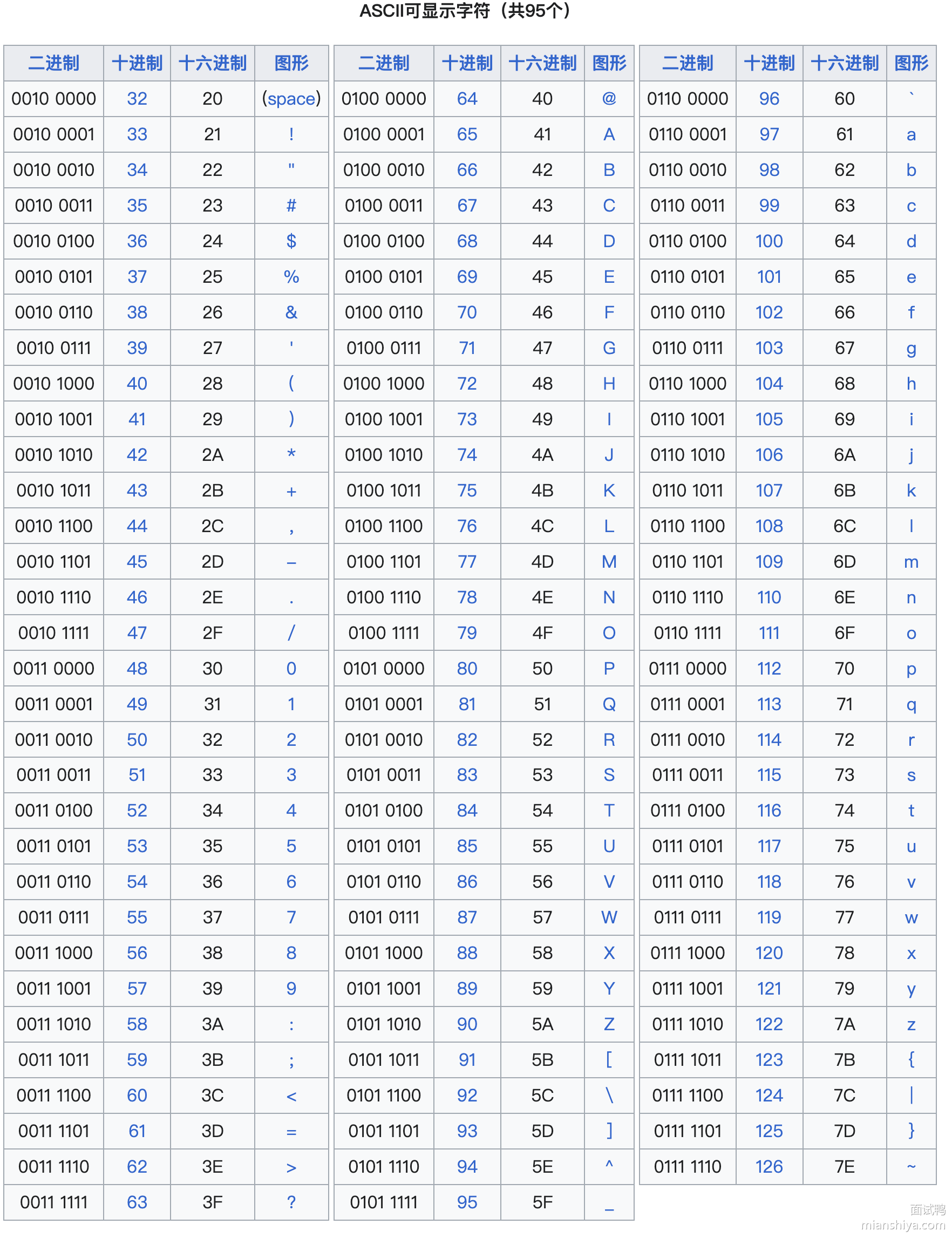
从图可以看到,共 8 位,但是第一位都是 0,实际上就用了 7 位。可以看到完全就是美国标准,中文啥的完全没有。
所以我们中国制定了 GB2312 字符集,后续由发布了 GBK,基于 GB2312 增加了一些繁体字等字符,这里的 K 是扩展的意思。
扩展:Unicode
中国需要中国的字符编码,美国需要美国的,韩国还需要韩国的,所以每个国家都弄一个无法统一。
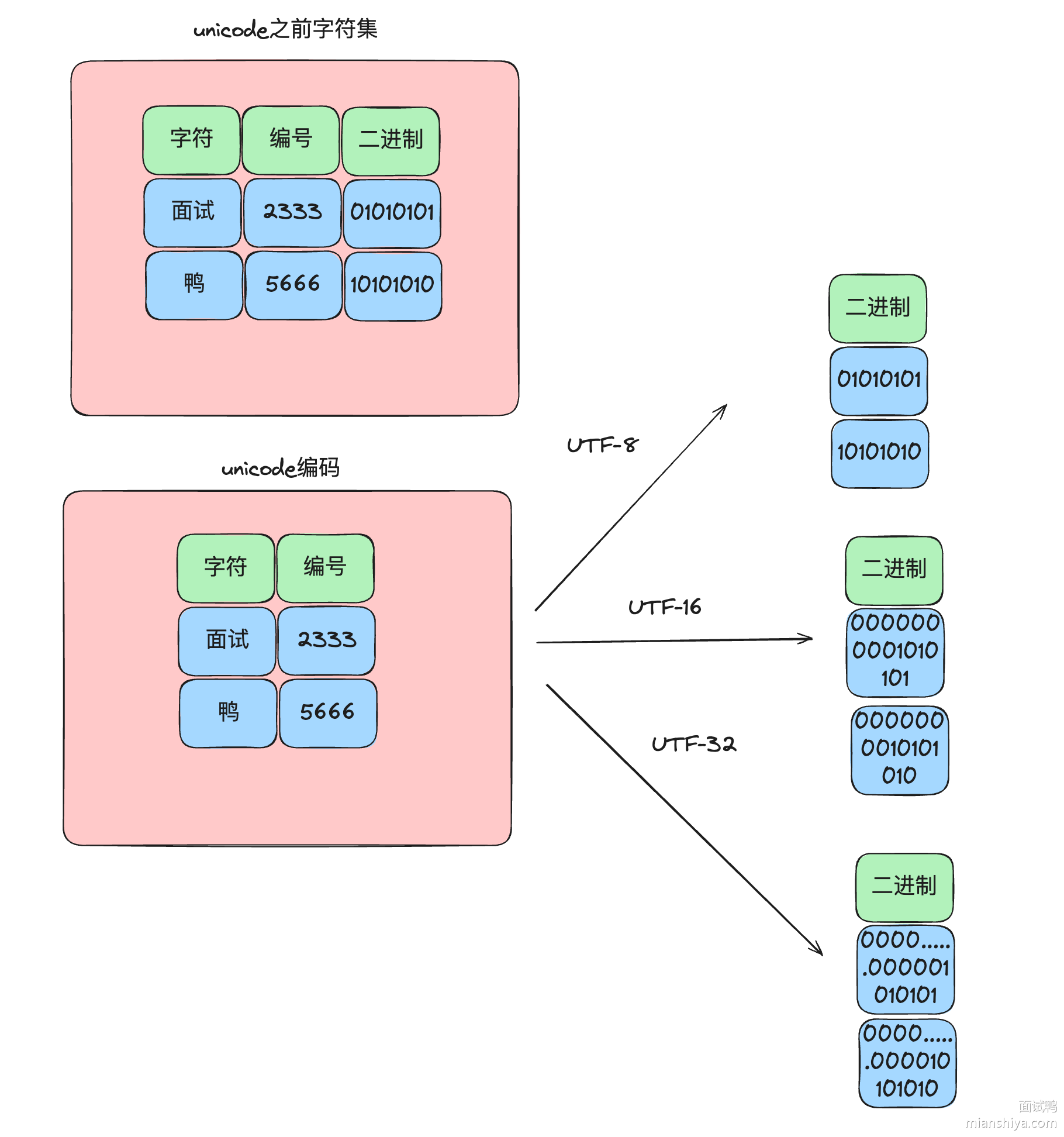
所以就指定了一个统一码 Unicode,又译作万国码、统一字符码、统一字符编码,是信息技术领域的业界标准,其整理、编码了世界上大部分的文字系统,使得电脑能以通用划一的字符集来处理和显示文字,不但减轻在不同编码系统间切换和转换的困扰,更提供了一种跨平台的乱码问题解决方案!
Unicode 和之前的编码不太一样,它将字符集和编码实现解耦了。
来看下这张图就理解了:
34.为什么 JDK 9 中将 String 的 char 数组改为 byte 数组?
这个题目的答案其实非常简单:这个操作主要是为了节省内存空间,提高内存利用率。
在 JDK 9 之前,String 类是基于 char[] 实现的,内部采用 UTF-16 编码,每个字符占用两个字节。
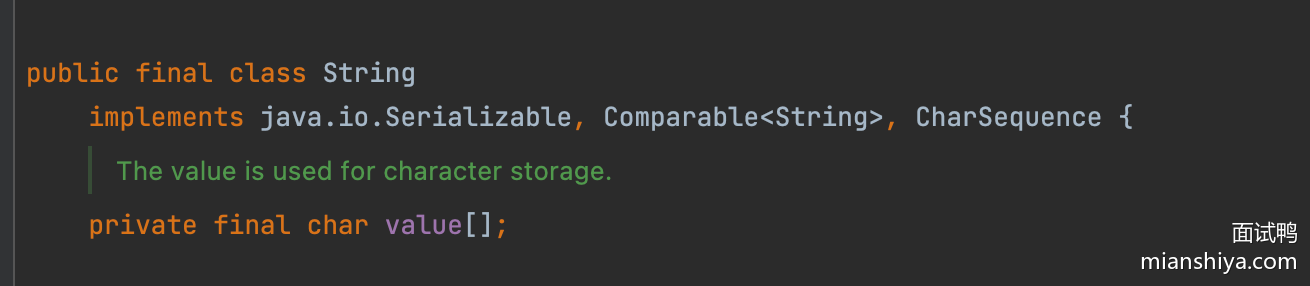
但是,如果当前的字符仅需一个字节的空间,这就造成了浪费。例如一些 Latin-1 字符用一个字节即可表示。
因此 JDK 9 做了优化采用 byte 数组来实现:
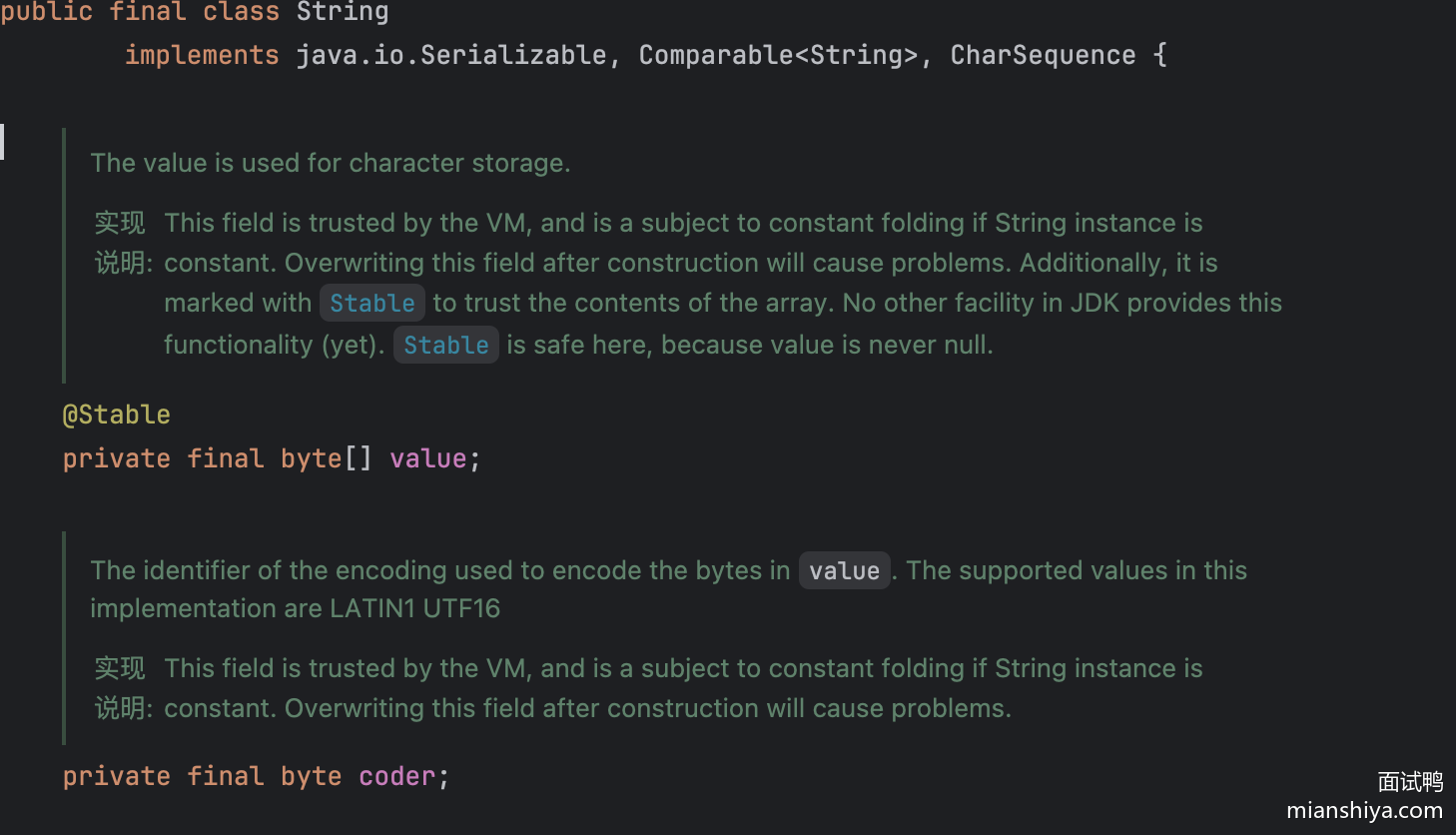
并引入了 coder 变量来标识编码方式(Latin-1 或 UTF-16)。对于大多数只包含 Latin-1 字符(即每个字符可以用一个字节表示)的字符串,内存使用量减半。
35.如何在 Java 中调用外部可执行程序或系统命令?
在 Java 中,可以使用 Runtime 类或 ProcessBuilder 类来调用外部可执行程序或执行系统命令。这两种方法都能创建一个子进程来执行指定的命令或程序。接下来就是这两个类的简单使用:
1)使用 Runtime.exec()
Runtime 类提供了 exec() 方法,它允许你执行外部命令。相对于 ProcessBuilder 比较简单。
使用例子如下:
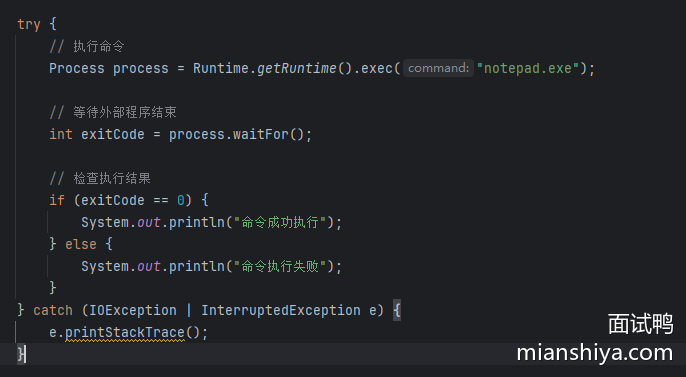
如果还需要获取返回的内容,可以通过 Process 对象中的 getInputStream 方法来获取字符输入流对象。
简单解释一下:
- 执行命令:使用
Runtime.getRuntime().exec方法执行命令。 - 等待进程结束:使用
waitFor方法等待进程结束并获取退出码。
2)使用 ProcessBuilder
ProcessBuilder 类提供了一个更灵活和强大的方式来管理外部进程。它允许你设置环境变量、工作目录,以及重定向输入和输出流。
使用 ProcessBuilder 的例子:
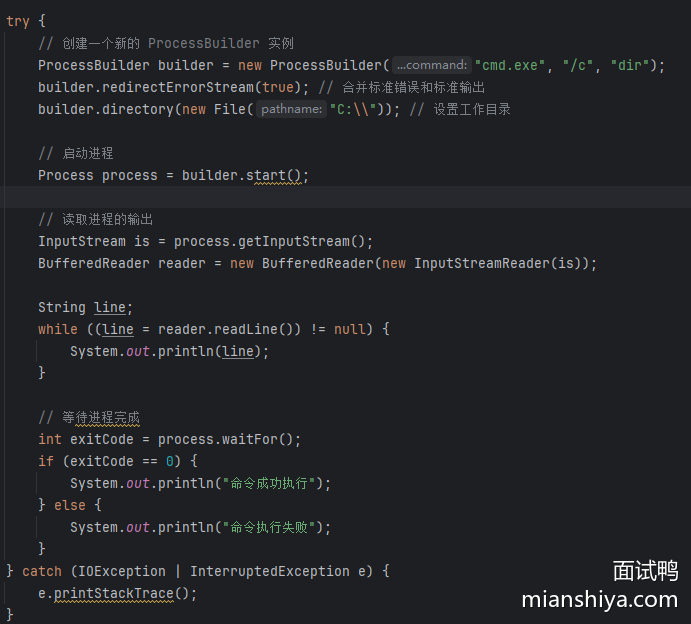
简单解释一下:
- 创建 ProcessBuilder 实例:使用 ProcessBuilder 创建一个新的进程。
- 设置命令:通过 command 方法指定要执行的命令及其参数或像例子直接在构造函数内写入。
- 启动进程:使用 start 方法启动进程。
- 读取输出:通过 getInputStream 获取进程的输入流,并读取输出。
- 等待进程结束:使用 waitFor 方法等待进程结束并获取退出码。
36.如果一个线程在 Java 中被两次调用 start() 方法,会发生什么?
会报错。
因为在 Java 中,一个线程只能被启动一次。所以尝试第二次调用 start() 方法时,会抛出 IllegalThreadStateException 异常。
这是因为一旦线程已经开始执行,它的状态不能再回到初始状态。线程的生命周期不允许它从终止状态回到可运行状态。
补充线程的生命周期
在 Java 中,线程的生命周期可以细化为以下几个状态:
- New(初始状态):线程对象创建后,但未调用 start() 方法。
- Runnable(可运行状态):调用 start() 方法后,线程进入就绪状态,等待 CPU 调度。
- Blocked(阻塞状态):线程试图获取一个对象锁而被阻塞。
- Waiting(等待状态):线程进入等待状态,需要被显式唤醒才能继续执行。
- Timed Waiting(含等待时间的等待状态):线程进入等待状态,但指定了等待时间,超时后会被唤醒。
- Terminated(终止状态):线程执行完成或因异常退出。
而 Blocked、Waiting、Timed Waiting 其实都属于休眠状态。
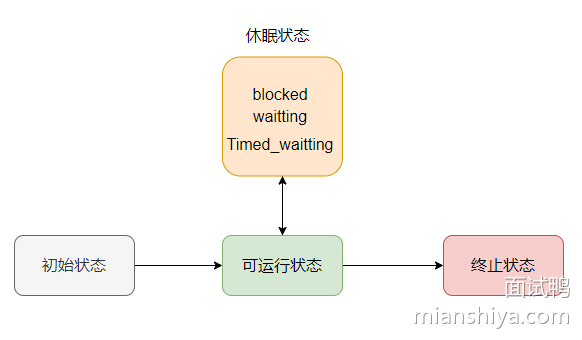
一开始线程新建的时候就是初始状态,还未 start。
调用可运行状态就是可以运行。可能正在运行,也可能正在等 CPU 时间片。
造成线程等待的操作有:Object.wait、Thread.join、LockSupport.park。
含等待时间的等待就是上面这些操作设置了 timeout 参数的方法,例如Object.wait(1000)。
37.栈和队列在 Java 中的区别是什么?
1)顺序不同:队列是先进先出(FIFO)而栈是先进后出(LIFO)。
2)操作位置不同: 栈的操作仅限于栈顶,而队列的添加操作发生在队尾,删除操作发生在队头。
3)用途不同: 队列通常用于处理需要按顺序处理的任务;栈通常用于处理具有最近相关性的任务,如函数调用、撤销操作等。
38. Java 的 Optional 类是什么?它有什么用?
Optional 是 Java 8 引入的一个容器类,它用来表示一个值可能存在或不存在。
常见的使用方式如下:
Optional<User> userOption = Optional.ofNullable(userService.getUser(...));
if (!userOption.isPresent()) {....}
Optional 设计出来的意图是什么, Java 语言架构师 Brian Goetz 是这么说的:
Our intention was to provide a limited mechanism for library method return types where there needed to be a clear way to represent “no result”, and using null for such was overwhelmingly likely to cause errors.
意思就是:Optional 可以给返回结果提供了一个表示无结果的值,而不是返回 null。
网上比较流行的说法是 Optional 可以避免空指针,我不太赞同这种说法。因为最终的目的是拿到 Optional 里面存储的值,如果这个值是 null,不做额外的判断,直接使用还是会有空指针的问题。
我认为 Optional 的好处在于可以简化平日里一系列判断 null 的操作,使得用起来的时候看着不需要判断 null,表现出来好像用 Optional 就不需要关心空指针的情况。
而事实上是 Optional 在替我们负重前行,该有的判断它替我们完成了,而且用了 Optional 最后拿结果的时候还是小心的,盲目 get 一样会抛错,Brian Goetz 说 get 应该叫 getOrElseThrowNoSuchElementException。
我们来看一下代码就很清楚 Optional 的好处在哪儿了。比如现在有个 yesSerivce 能 get 一个 Yes,此时需要输出 Yes 所在的省,此时的代码是这样的:
Yes yes = getYes();
if (yes != null) {
Address yesAddress = yes.getAddress();
if (yesAddress != null) {
Province province = yesAddress.getProvince();
System.out.println(province.getName());
}
}
throw new NoSuchElementException(); //如果没找到就抛错
如果用 Optional 的话,那就变成下面这样:
Optional.ofNullable(getYes())
.map(a -> a.getAddress())
.map(p -> p.getProvince())
.map(n -> n.getName())
.orElseThrow(NoSuchElementException::new);
可以看到,如果用了 Optional,代码里不需要判空的操作,即使 address 、province 为空的话,也不会产生空指针错误。
39. Java 的 I/O 流是什么?
Java 的 I/O 流(Input/Output Streams)是用于处理输入和输出操作的类和接口,主要用于读取和写入数据,可以处理不同类型的数据源和目标,如文件、网络连接、内存缓冲区等等。
首先需要了解 I/O 流分为两类:
- 输入流(Input Stream):用于读取数据的流。
- 输出流(Output Stream):用于写入数据的流。
基于这两种输入输出的类型,按照处理的数据类型还可以进行分类:
1)字节流(Byte Streams):用于处理字节数据,适用于所有类型的 I/O 操作。
输入流:InputStream,常用以下几个输入流:
- FileInputStream:从文件中读取字节数据。
- BufferedInputStream:为输入流提供缓冲功能,提高读取性能。
- DataInputStream:读取基本数据类型的数据。
输出流:OutputStream,常用以下几个输出流:
- FileOutputStream:将字节数据写入文件。
- BufferedOutputStream:为输出流提供缓冲功能,提高写入性能。
- DataOutputStream:写入基本数据类型的数据。
2)字符流(Character Streams):用于处理字符数据,适用于文本文件。
输入流:Reader,常用以下几个输入流:
- FileReader:从文件中读取字符数据。
- BufferedReader:为字符输入流提供缓冲功能,提高读取性能。
- InputStreamReader:将字节流转换为字符流。
输出流:Writer,常用以下几个输出流:
- FileWriter:将字符数据写入文件。
- BufferedWriter:为字符输出流提供缓冲功能,提高写入性能。
- OutputStreamWriter:将字符流转换为字节流。
40.什么是 Java 的网络编程?
Java 的网络编程主要利用 java.net 包,它提供了用于网络通信的基本类和接口。
Java 网络编程的基本概念:
- IP 地址:用于标识网络中的计算机。
- 端口号:用于标识计算机上的具体应用程序或进程。
- Socket(套接字):网络通信的基本单位,通过 IP 地址和端口号标识。
- 协议:网络通信的规则,如 TCP(传输控制协议)和 UDP(用户数据报协议)。
Java 网络编程的核心类:
- Socket:用于创建客户端套接字。
- ServerSocket:用于创建服务器套接字。
- DatagramSocket:用于创建支持 UDP 协议的套接字。
- URL:用于处理统一资源定位符。
- URLConnection:用于读取和写入 URL 引用的资源。
示例代码参考(以下代码时基于 TCP 通信的,一般笔试考察的都是 TCP):
服务端代码:
import java.io.*;
import java.net.*;
public class TCPServer {
public static void main(String[] args) {
try (ServerSocket serverSocket = new ServerSocket(8080)) {
System.out.println("Server is listening on port 8080");
while (true) {
Socket socket = serverSocket.accept();
//异步处理,优化可以用线程池
new ServerThread(socket).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
class ServerThread extends Thread {
private Socket socket;
public ServerThread(Socket socket) {
this.socket = socket;
}
public void run() {
try (PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {
// 读取客户端消息
String message = in.readLine();
System.out.println("Received: " + message);
// 响应客户端
out.println("Hello, client!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
客户端代码:
import java.io.*;
import java.net.*;
public class TCPClient {
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080);
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {
// 发送消息给服务器
out.println("Hello, server!");
// 接收服务器的响应
String response = in.readLine();
System.out.println("Server response: " + response);
} catch (IOException e) {
e.printStackTrace();
}
}
}
41. Java 中的基本数据类型有哪些?
Java 中的数据类型可以分为两大类:基本数据类型和引用数据类型。
基本数据类型是 Java 中的原始数据类型,而引用数据类型则是对象引用。
1)基本数据类型(Primitive Data Types):
整型:byte(8位有符号整数)、short(16位有符号整数)、int(32位有符号整数)、long(64位有符号整数,后缀 L 或 l)。
浮点型:float(32位浮点数,后缀 F 或 f)、double(64位浮点数,后缀 D 或 d)。
字符型:char(16位 Unicode 字符)。
布尔型:boolean(只有两个可能的值:true 或 false)。
2)引用数据类型(Reference Data Types):
类(Class):用户自定义的类或 Java 内置的类。
接口(Interface):定义了类必须实现的方法的契约。
数组(Array):一种容器对象,可以包含固定数量的单一类型值。
枚举(Enumeration):用于表示一组预定义的常量,使代码更加简洁、可读。
注解(Annotation):修饰方法或者类或者属性。
42.什么是 Java 中的自动装箱和拆箱?
自动装箱(Autoboxing)和拆箱(Unboxing)是 Java 语言中的一种特性,它们允许自动地在基本数据类型和相应的包装类之间进行转换。极大地简化了代码,使得基本类型和包装类之间的转换更加透明和自然。
1)自动装箱(Autoboxing):
自动装箱是指 Java 编译器自动将基本数据类型转换为对应的包装类。
以下是一个示例:
public class AutoboxingExample {
public static void main(String[] args) {
// 自动装箱:int 转换为 Integer
Integer integerObject = 10;
System.out.println("Integer object: " + integerObject);
}
}
10 是一个 int 类型的值,但它被自动转换为 Integer 对象。这种转换在代码中是隐式完成的,无需显式调用 Integer.valueOf(int) 方法。
2)自动拆箱(Unboxing):
自动拆箱是指 Java 编译器自动将包装类转换为对应的基本数据类型。
以下是一个示例:
public class UnboxingExample {
public static void main(String[] args) {
// 自动拆箱:Integer 转换为 int
Integer integerObject = 10;
int intValue = integerObject;
System.out.println("int value: " + intValue);
}
}
integerObject 是一个 Integer 对象,但它被自动转换为 int 类型的值。这种转换在代码中也是隐式完成的,无需显式调用 Integer.intValue() 方法。
需要注意的事项:
1)性能影响:虽然自动装箱和拆箱提供了方便,但它们会产生额外的对象创建和拆箱操作,可能会影响性能,尤其是在循环或频繁使用的场景中。
2)NullPointerException:在进行拆箱操作时,如果包装类对象为 null,会抛出 NullPointerException。
43.什么是 Java 中的迭代器(Iterator)?
迭代器(Iterator)其实是一种设计模式,用于遍历集合(例如 List、Set、Map 等)中的元素,而不需要暴露集合的内部实现,即不需要了解集合的底层结构。
在 Java 中 Iterator 是一个接口,在 java.util 包中的,常用的方法是:
- hasNext():如果迭代器还有更多的元素可以迭代,则返回 true,否则返回 false。
- next():返回迭代器的下一个元素。如果没有更多元素,调用该方法将抛出 NoSuchElementException。
- remove():从底层集合中移除 next() 方法返回的上一个元素。这个方法是可选的,不是所有的实现都支持该操作。如果不支持,调用时会抛出 UnsupportedOperationException。
简单示例代码如下:
public class IteratorExample {
public static void main(String[] args) {
// 创建一个 List 集合
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Cherry");
// 获取集合的迭代器
Iterator<String> iterator = list.iterator();
// 使用迭代器遍历集合
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
// 移除集合中的元素
iterator = list.iterator(); // 重新获取迭代器
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("Banana")) {
iterator.remove();
}
}
// 再次遍历集合,确认元素已被移除
System.out.println("After removal:");
iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
迭代器模式带来了很多好处:
1)封装性:它将集合遍历行为和具体的实现分离,使得使用者不需要了解集合具体的内部实现。
2)一致性:所有的集合都实现了 Iterator 接口,因此对于不同集合的遍历代码都是一致的。
3)灵活性:因为遍历接口一致,使得可以很灵活的替换底层实现的集合而不需要改变上层的遍历代码。
Iterator 提供了单向遍历方法,如果需要支持双向遍历,可以使用 ListIterator 接口。
44. Java 运行时异常和编译时异常之间的区别是什么?
在 Java 中其实分了两大类异常,受检异常(checked exception)和非受检异常(unchecked exception),它们之间的差别主要在于是否是编译时检查。
受检异常(checked exception)其实就是编译时异常,继承自 Exception,即在编译阶段检查代码中可能会出现的异常,需要开发者显式的捕获(catch)或声明抛出(throw)这种异常,否则编译就会报错,这是一种强制性规范。
常见的有:IOException、SQLException、FileNotFoundException 等等。
非受检异常(unchecked exception)就是运行时异常,继承自 RuntimeException 类。是指在运行期间可能会抛出的异常,编译期不强制要求处理,之所以不强制是因为它可以通过完善代码避免报错。
常见的有:NullPointerException、ArrayIndexOutOfBoundsException、ArithmeticException 等等。
45.什么是 Java 中的继承机制?
Java 中的继承是面向对象编程(OOP)的一个核心概念,它允许新创建的类(称为子类或派生类)继承现有类(称为父类或基类)的属性和方法。
通过继承,子类可以复用、扩展和修改父类的行为,提高了代码的复用性,实现了多态。
简单举例看下代码就了解了,在 Java 中主要通过 extends 实现继承:
class Animal {
void breathe() {
System.out.println("Breathing");
}
}
class Dog extends Animal {
void bark() {
System.out.println("Barking");
}
@Override
void breathe() {
System.out.println("Breathing through lungs");
}
}
public class InheritanceExample {
public static void main(String[] args) {
Animal myAnimal = new Dog(); // 多态性
myAnimal.breathe(); // 调用 Dog 类的 breathe 方法
((Dog) myAnimal).bark(); // 向下转型并调用 Dog 类的 bark 方法
}
}
重写使用 @Override 注释来标明,并且方法签名(方法名称、方法参数类型与顺序)必须与父类中的方法相同。
Java 只支持单继承,即一个类只能继承一个直接父类。但是,通过接口(interfaces),Java 实现了多继承的功能。
46.什么是 Java 的封装特性?
封装(Encapsulation)是面向对象编程(OOP)的核心概念之一,它指的是将对象的数据(属性)和行为(方法)组合在一起,并隐藏内部的实现细节。
public class Car {
private String model; // 私有属性,外部无法直接访问
private int year;
// 构造方法
public Car(String model, int year) {
this.model = model;
this.year = year;
}
// getter 方法
public String getModel() {
return model;
}
// setter 方法
public void setModel(String model) {
this.model = model;
}
// 行为方法
public void startEngine() {
System.out.println("Engine started for " + model);
}
}
public class EncapsulationExample {
public static void main(String[] args) {
Car myCar = new Car("Toyota", 2021);
myCar.startEngine(); // 使用公共方法
// 使用 getter 和 setter 方法访问和更新属性
System.out.println("Car model: " + myCar.getModel());
myCar.setModel("Honda");
}
}
关键点
1)数据隐藏:
封装允许对象隐藏其内部状态和实现细节,只暴露出一个可以被外界访问和操作的接口。
2)访问控制:
通过使用访问修饰符(如 private、protected、public),封装可以限制对类成员的访问权限。
3)创建对象:
封装使得创建具有复杂内部结构的对象变得简单,因为用户只需要通过公共接口与之交互。
4)接口与实现分离:
封装将对象的接口与其实现分离,这样即使实现改变,接口保持不变,对使用对象的客户代码影响较小。
5)数据抽象:
封装提供了一种抽象,只显示必要的信息,隐藏不必要的实现细节。
47. Java 中的访问修饰符有哪些?
Java 中的访问修饰符用于控制类、方法和变量的访问级别。主要有四种访问修饰符:public、protected、默认(包级访问)和 private。
1)public:
public 是最宽松的访问级别,可以被任何其他类访问。
适用范围:类、接口、字段、方法、构造函数。
2)protected:
protected 类型的成员可以在同一个包中的其他类以及不同包中的子类中访问。
适用范围:字段、方法、构造函数。不适用于顶级类。
3)default(无修饰符):
如果没有指定访问修饰符(即默认访问级别),那么类成员只能在同一个包内被访问,不同包中的类不能访问。
适用范围:类、字段、方法、构造函数。
4)private:
private 是最严格的访问级别,类成员只能在定义它的类内部访问。
适用范围:字段、方法、构造函数。不适用于顶级类。
表格对比如下:
| 修饰符 | 当前类 | 同一包内 | 子类(不同包) | 其他包 |
|---|---|---|---|---|
| public | 是 | 是 | 是 | 是 |
| protected | 是 | 是 | 是 | 否 |
| 默认 | 是 | 是 | 否 | 否 |
| private | 是 | 否 | 否 | 否 |
小结修饰符适用范围:
1)顶级类(即不是内部类)不能是 protected 或 private。
2)接口和类可以是 public 或 default。
3)方法和构造函数可以是 public、protected、default 或 private。
4)变量(字段)可以是 public、protected、default 或 private。
48. Java 中静态方法和实例方法的区别是什么?
静态方法
1)使用 static 关键字声明的方法。
2)属于类,而不是类的实例。
3)可以通过类名直接调用,也可以通过对象调用,但这种方式不推荐,因为它暗示了实例相关性。
4)可以访问类的静态变量和静态方法。不能直接访问实例变量和实例方法(因为实例变量和实例方法属于对象)。
5)随着类的加载而加载,随着类的卸载而消失。
典型用途:
- 工具类方法,如 Math 类中的静态方法 Math.sqrt(), Math.random().
- 工厂方法,用于返回类的实例。
实例方法
1)不使用 static 关键字声明的方法。
2)属于类的实例。
3)必须通过对象来调用。
4)可以访问实例变量和实例方法。也可以访问类的静态变量和静态方法。
5)随着对象的创建而存在,随着对象的销毁而消失。
典型用途:
- 操作或修改对象的实例变量。
- 执行与对象状态相关的操作。
表格总结:
| 特性 | 静态方法 | 实例方法 |
|---|---|---|
| 关键字 | static | 无 |
| 归属 | 类 | 对象 |
| 调用方式 | 通过类名或对象调用 | 通过对象调用 |
| 访问权限 | 只能访问静态变量和静态方法 | 可以访问实例变量、实例方法、静态变量和静态方法 |
| 典型用途 | 工具类方法、工厂方法 | 操作对象实例变量、与对象状态相关的操作 |
| 生命周期 | 类加载时存在,类卸载时消失 | 对象创建时存在,对象销毁时消失 |
扩展:注意事项
1)静态方法中不能使用 this 关键字,因为 this 代表当前对象实例,而静态方法属于类,不属于任何实例。
2)静态方法可以被重载(同类中方法名相同,但参数不同),但不能被子类重写(因为方法绑定在编译时已确定)。实例方法可以被重载,也可以被子类重写。
3)实例方法中可以直接调用静态方法和访问静态变量。
4)静态方法不具有多态性,即不支持方法的运行时动态绑定。
49. Java 中 for 循环与 foreach 循环的区别是什么?
for
传统的 for 循环具有更大的灵活性和控制力。
主要特点:
- 灵活性:可以控制循环的初始值、终止条件和步进方式。可以使用任何条件和任何步进表达式,还可以通过多种变量进行复杂的控制。
- 适用于数组:可以通过索引访问数组的元素。
- 支持修改集合:可以在循环体中修改集合中的元素。
foreach
它提供了一种更简洁的语法来遍历数组和集合。
主要特点:
- 简洁性:语法更简单,减少了初始化、条件检查和更新的样板代码。适合用于遍历数组和实现了 Iterable 接口的集合。
- 只读访问:不提供对当前索引的访问,因此不适合需要根据索引进行复杂操作的场景。
- 安全性:在遍历过程中不能修改集合的结构(例如,不能在遍历 List 的同时添加或删除元素),否则会抛出 ConcurrentModificationException。
总结:
- 使用 for 循环:当需要对集合进行复杂的控制和操作时,例如根据索引进行操作、反向遍历、跳步遍历。或者需要访问当前索引时。
- 使用 foreach 循环:当需要简单遍历数组或集合,并且不需要访问当前索引时。
最后再推荐下鸭鸭目前努力在做面试神器面试鸭,已经有 4000 多道面试题目啦,欢迎大家来阅读!如果大家有不会的面试题,也可以在小程序内反馈!鸭鸭会第一时间为大家解答!















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









