







HBase简介
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协调工具。
主键:Row Key
主键是用来检索记录的主键,访问hbase table中的行,只有三种方式
1. 通过单个row key访问
2. 通过row key的range
3. 全表扫描
列族:Column Family
列族在创建表的时候声明,一个列族可以包含多个列,列中的数据都是以二进制形式存在,没有数据类型。
时间戳:timestamp
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引
HBASE基础知识
表结构
HBase中有两张特殊的Table,-ROOT-和.META.
-ROOT- :记录了.META.表的Region信息,-ROOT-只有一个region
.META. :记录了用户创建的表的Region信息,.META.可以有多个regoin
Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问
物理存储
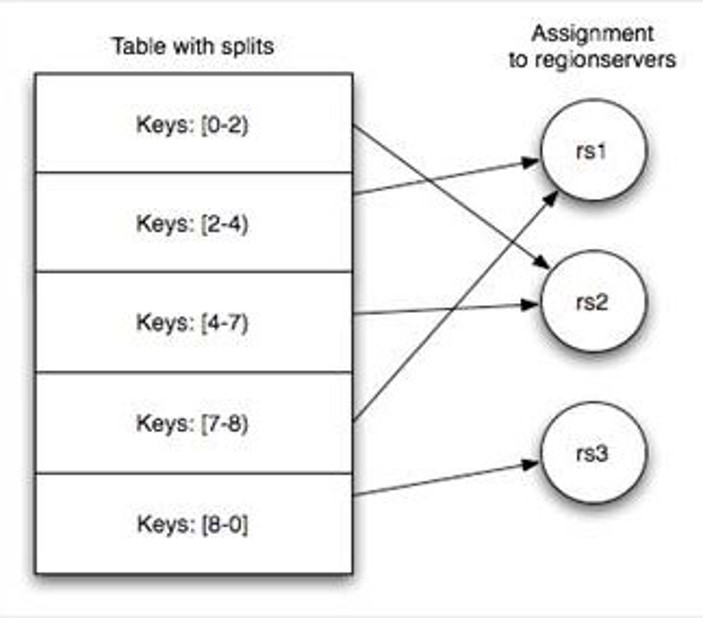
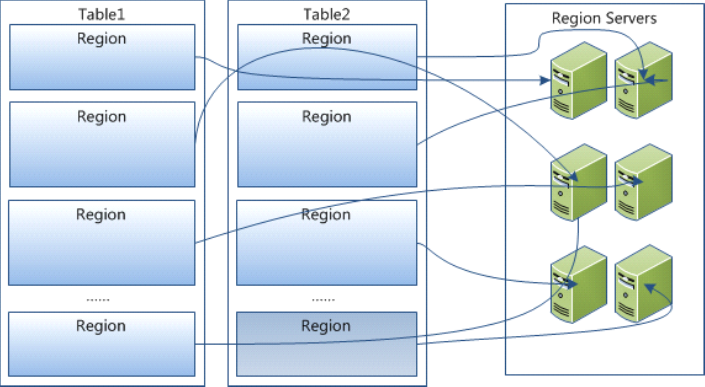
Table 在行的方向上分割为多个HRegion,一个region由[startkey,endkey)表示
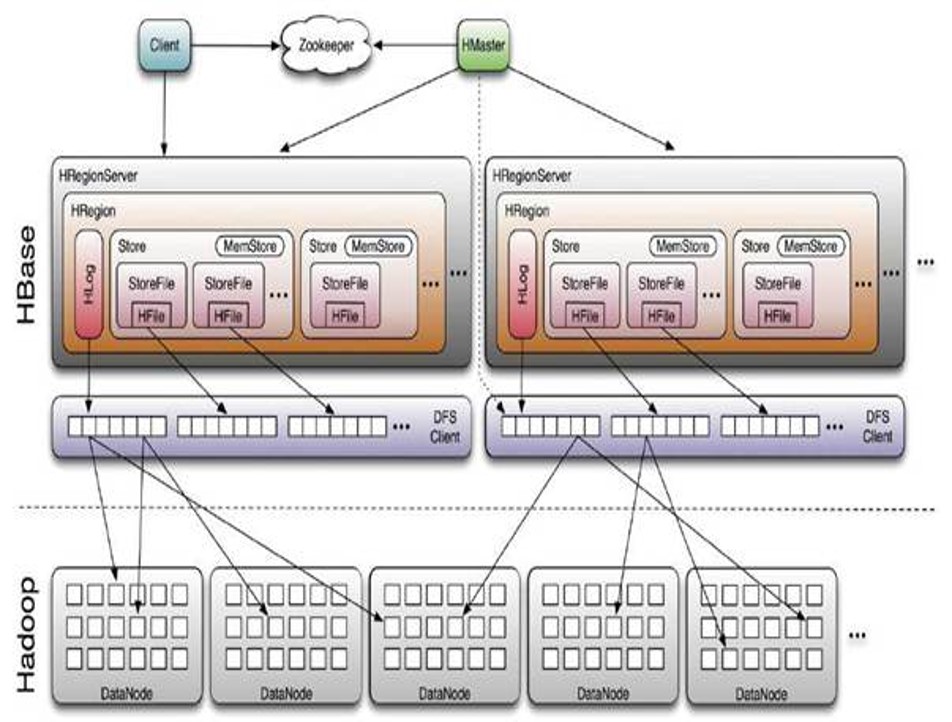
架构体系
◆ Client 包含访问hbase 的接口,client 维护着一些cache 来加快对hbase 的访问,比如regione 的位置信息
◆ Zookeeper
- 保证任何时候,集群中只有一个running master
- 存贮所有Region 的寻址入口
- 实时监控Region Server 的状态,将Region server 的上线和下线信息,实时通知给Master
- 存储Hbase 的schema,包括有哪些table,每个table 有哪些column family
◆ Master 可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行
- 为Region server 分配region
- 负责region server 的负载均衡
- 发现失效的region server 并重新分配其上的region
Region Server
- 维护Master 分配给它的region,处理对这些region 的IO 请求
- 负责切分在运行过程中变得过大的region
可以看出,client 访问hbase 上数据的过程并不需要master 参与,寻址访问先zookeeper再regionserver,数据读写访问regioneserver。HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HBase集群搭建
1.上传hbase安装包
2.解压
3.配置hbase集群,要修改3个文件(首先zk集群已经安装好了)
注意:要把hadoop的hdfs-site.xml和core-site.xml 放到hbase/conf下
- 3.1 修改hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_55
//告诉hbase使用外部的zk
export HBASE_MANAGES_ZK=false
vim hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave01:2181,slave02:2181</value>
</property>
</configuration>vim regionservers
slave01
slave02
- 3.2 拷贝hbase到其他节点
scp -r /home/elon/opt/modules/hbase-0.96.2-hadoop2/ slave01:/home/elon/opt/modules/
scp -r /home/elon/opt/modules/hbase-0.96.2-hadoop2/ slave02:/home/elon/opt/modules/4.将配置好的HBase拷贝到每一个节点并同步时间。
5.启动所有的hbase
- 分别启动zk
./zkServer.sh start - 启动hdfs集群
start-dfs.sh - 启动hbase,在主节点上运行
start-hbase.sh
6.通过浏览器访问hbase管理页面
192.168.1.80:60010
7.为保证集群的可靠性,要启动多个HMaster
hbase-daemon.sh start master
HBase Shell
进入hbase命令行
./hbase shell显示hbase中的表
list创建user表,包含info、data两个列族
create ‘user’, ‘info1’, ‘data1’
create ‘user’, {NAME => ‘info’, VERSIONS => ‘3’}向user表中插入信息,row key为rk0001,列族info中添加name列标示符,值为zhangsan
put ‘user’, ‘rk0001’, ‘info:name’, ‘zhangsan’向user表中插入信息,row key为rk0001,列族info中添加gender列标示符,值为female
put ‘user’, ‘rk0001’, ‘info:gender’, ‘female’向user表中插入信息,row key为rk0001,列族info中添加age列标示符,值为20
put ‘user’, ‘rk0001’, ‘info:age’, 20向user表中插入信息,row key为rk0001,列族data中添加pic列标示符,值为picture
put ‘user’, ‘rk0001’, ‘data:pic’, ‘picture’获取user表中row key为rk0001的所有信息
get ‘user’, ‘rk0001’获取user表中row key为rk0001,info列族的所有信息
get ‘user’, ‘rk0001’, ‘info’获取user表中row key为rk0001,info列族的name、age列标示符的信息
get ‘user’, ‘rk0001’, ‘info:name’, ‘info:age’获取user表中row key为rk0001,info、data列族的信息
get ‘user’, ‘rk0001’, ‘info’, ‘data’
get ‘user’, ‘rk0001’, {COLUMN => [‘info’, ‘data’]}
get ‘user’, ‘rk0001’, {COLUMN => [‘info:name’, ‘data:pic’]}获取user表中row key为rk0001,列族为info,版本号最新5个的信息
get ‘user’, ‘rk0001’, {COLUMN => ‘info’, VERSIONS => 2}
get ‘user’, ‘rk0001’, {COLUMN => ‘info:name’, VERSIONS => 5}
get ‘user’, ‘rk0001’, {COLUMN => ‘info:name’, VERSIONS => 5, TIMERANGE => [1392368783980, 1392380169184]}获取user表中row key为rk0001,cell的值为zhangsan的信息
get ‘people’, ‘rk0001’, {FILTER => “ValueFilter(=, ‘binary:图片’)”}获取user表中row key为rk0001,列标示符中含有a的信息
get ‘people’, ‘rk0001’, {FILTER => “(QualifierFilter(=,’substring:a’))”}
put ‘user’, ‘rk0002’, ‘info:name’, ‘fanbingbing’
put ‘user’, ‘rk0002’, ‘info:gender’, ‘female’
put ‘user’, ‘rk0002’, ‘info:nationality’, ‘中国’
get ‘user’, ‘rk0002’, {FILTER => “ValueFilter(=, ‘binary:中国’)”}
查询user表中的所有信息
scan ‘user’查询user表中列族为info的信息
scan ‘user’, {COLUMNS => ‘info’}
scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 5}
scan ‘persion’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 3}查询user表中列族为info和data的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’]}
scan ‘user’, {COLUMNS => [‘info:name’, ‘data:pic’]}查询user表中列族为info、列标示符为name的信息
scan ‘user’, {COLUMNS => ‘info:name’}查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
scan ‘user’, {COLUMNS => ‘info:name’, VERSIONS => 5}查询user表中列族为info和data且列标示符中含有a字符的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’], FILTER => “(QualifierFilter(=,’substring:a’))”}查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan ‘people’, {COLUMNS => ‘info’, STARTROW => ‘rk0001’, ENDROW => ‘rk0003’}查询user表中row key以rk字符开头的
scan ‘user’,{FILTER=>”PrefixFilter(‘rk’)”}查询user表中指定范围的数据
scan ‘user’, {TIMERANGE => [1392368783980, 1392380169184]}删除数据
- 删除user表row key为rk0001,列标示符为info:name的数据
delete ‘people’, ‘rk0001’, ‘info:name’ - 删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
delete ‘user’, ‘rk0001’, ‘info:name’, 1392383705316
- 删除user表row key为rk0001,列标示符为info:name的数据
清空user表中的数据
truncate ‘people’修改表结构
- 首先停用user表(新版本不用)
disable ‘user’ - 添加两个列族f1和f2
alter ‘people’, NAME => ‘f1’
alter ‘user’, NAME => ‘f2’ - 启用表
enable ‘user’
- 首先停用user表(新版本不用)
disable 'user'(新版本不用)
- 删除一个列族
alter ‘user’, NAME => ‘f1’, METHOD => ‘delete’ 或 alter ‘user’, ‘delete’ => ‘f1’
添加列族f1同时删除列族f2
alter ‘user’, {NAME => ‘f1’}, {NAME => ‘f2’, METHOD => ‘delete’}将user表的f1列族版本号改为5
alter ‘people’, NAME => ‘info’, VERSIONS => 5启用表
enable ‘user’删除表
disable ‘user’
drop ‘user’
get 'person', 'rk0001', {FILTER => "ValueFilter(=, 'binary:中国')"}
get 'person', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
scan 'person', {COLUMNS => 'info:name'}
scan 'person', {COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"}
scan 'person', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
scan 'person', {COLUMNS => 'info', STARTROW => '20140201', ENDROW => '20140301'}
scan 'person', {COLUMNS => 'info:name', TIMERANGE => [1395978233636, 1395987769587]}
delete 'person', 'rk0001', 'info:name'
alter 'person', NAME => 'ffff'
alter 'person', NAME => 'info', VERSIONS => 10
get 'user', 'rk0002', {COLUMN => ['info:name', 'data:pic']}HBase的Java API
// hbase操作必备
private static Configuration getConfiguration() {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.rootdir", "hdfs://hadoop0:9000/hbase");
//使用eclipse时必须添加这个,否则无法定位
conf.set("hbase.zookeeper.quorum", "hadoop0");
return conf;
}
// 创建一张表
public static void create(String tableName, String columnFamily) throws IOException{
HBaseAdmin admin = new HBaseAdmin(getConfiguration());
if (admin.tableExists(tableName)) {
System.out.println("table exists!");
}else{
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
tableDesc.addFamily(new HColumnDescriptor(columnFamily));
admin.createTable(tableDesc);
System.out.println("create table success!");
}
}
// 添加一条记录
public static void put(String tableName, String row, String columnFamily, String column, String data) throws IOException{
HTable table = new HTable(getConfiguration(), tableName);
Put p1 = new Put(Bytes.toBytes(row));
p1.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(data));
table.put(p1);
System.out.println("put'"+row+"',"+columnFamily+":"+column+"','"+data+"'");
}
// 读取一条记录
public static void get(String tableName, String row) throws IOException{
HTable table = new HTable(getConfiguration(), tableName);
Get get = new Get(Bytes.toBytes(row));
Result result = table.get(get);
System.out.println("Get: "+result);
}
// 显示所有数据
public static void scan(String tableName) throws IOException{
HTable table = new HTable(getConfiguration(), tableName);
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println("Scan: "+result);
}
}
// 删除表
public static void delete(String tableName) throws IOException{
HBaseAdmin admin = new HBaseAdmin(getConfiguration());
if(admin.tableExists(tableName)){
try {
admin.disableTable(tableName);
admin.deleteTable(tableName);
} catch (IOException e) {
e.printStackTrace();
System.out.println("Delete "+tableName+" 失败");
}
}
System.out.println("Delete "+tableName+" 成功");
}
// main函数
public static void main(String[] args) throws IOException {
String tableName="hbase_tb";
String columnFamily="cf";
HBaseTestCase.create(tableName, columnFamily);
HBaseTestCase.put(tableName, "row1", columnFamily, "cl1", "data");
HBaseTestCase.get(tableName, "row1");
HBaseTestCase.scan(tableName);
HBaseTestCase.delete(tableName);
}HBASE结合MapReduce批量导入
static class BatchImportMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
SimpleDateFormat dateformat1=new SimpleDateFormat("yyyyMMddHHmmss");
Text v2 = new Text();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException ,InterruptedException {
final String[] splited = value.toString().split("\t");
try {
final Date date = new Date(Long.parseLong(splited[0].trim()));
final String dateFormat = dateformat1.format(date);
String rowKey = splited[1]+":"+dateFormat;
v2.set(rowKey+"\t"+value.toString());
context.write(key, v2);
} catch (NumberFormatException e) {
final Counter counter = context.getCounter("BatchImport", "ErrorFormat");
counter.increment(1L);
System.out.println("出错了"+splited[0]+" "+e.getMessage());
}
};
}
static class BatchImportReducer extends TableReducer<LongWritable, Text, NullWritable>{
protected void reduce(LongWritable key, java.lang.Iterable<Text> values, Context context) throws java.io.IOException ,InterruptedException {
for (Text text : values) {
final String[] splited = text.toString().split("\t");
final Put put = new Put(Bytes.toBytes(splited[0]));
put.add(Bytes.toBytes("cf"), Bytes.toBytes("date"), Bytes.toBytes(splited[1]));
//省略其他字段,调用put.add(....)即可
context.write(NullWritable.get(), put);
}
};
}
public static void main(String[] args) throws Exception {
final Configuration configuration = new Configuration();
//设置zookeeper
configuration.set("hbase.zookeeper.quorum", "hadoop0");
//设置hbase表名称
configuration.set(TableOutputFormat.OUTPUT_TABLE, "wlan_log");
//将该值改大,防止hbase超时退出
configuration.set("dfs.socket.timeout", "180000");
final Job job = new Job(configuration, "HBaseBatchImport");
job.setMapperClass(BatchImportMapper.class);
job.setReducerClass(BatchImportReducer.class);
//设置map的输出,不设置reduce的输出类型
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
//不再设置输出路径,而是设置输出格式类型
job.setOutputFormatClass(TableOutputFormat.class);
FileInputFormat.setInputPaths(job, "hdfs://hadoop0:9000/input");
job.waitForCompletion(true);
}思考题
- HBASE是什么数据库,与普通RDBMS有什么区别
Hbase和RDBMS(关系数据库管理系统)区别 https://www.cnblogs.com/zhangXingSheng/p/6277445.html HBASE的结构
Hbase表的结构 http://blog.csdn.net/codestinity/article/details/6981278lHBASE的常用命令
Hbase shell 常用命令 http://blog.csdn.net/scutshuxue/article/details/6988348
参考链接
- hbase使用遇到 Class path contains multiple SLF4J bindings.错误解决方案 http://www.aboutyun.com/thread-7737-1-1.html
- 分布式系统、集群的时间同步 http://blog.csdn.net/xuejingfu1/article/details/52274143
扩展链接
- HBase Java API类介绍 http://www.cnblogs.com/ggjucheng/p/3380267.html
- HBase 官方文档中文版 http://abloz.com/hbase/book.html
- HBase简介(很好的梳理资料) ghttp://jiajun.iteye.com/blog/899632















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









