









架构演化

-
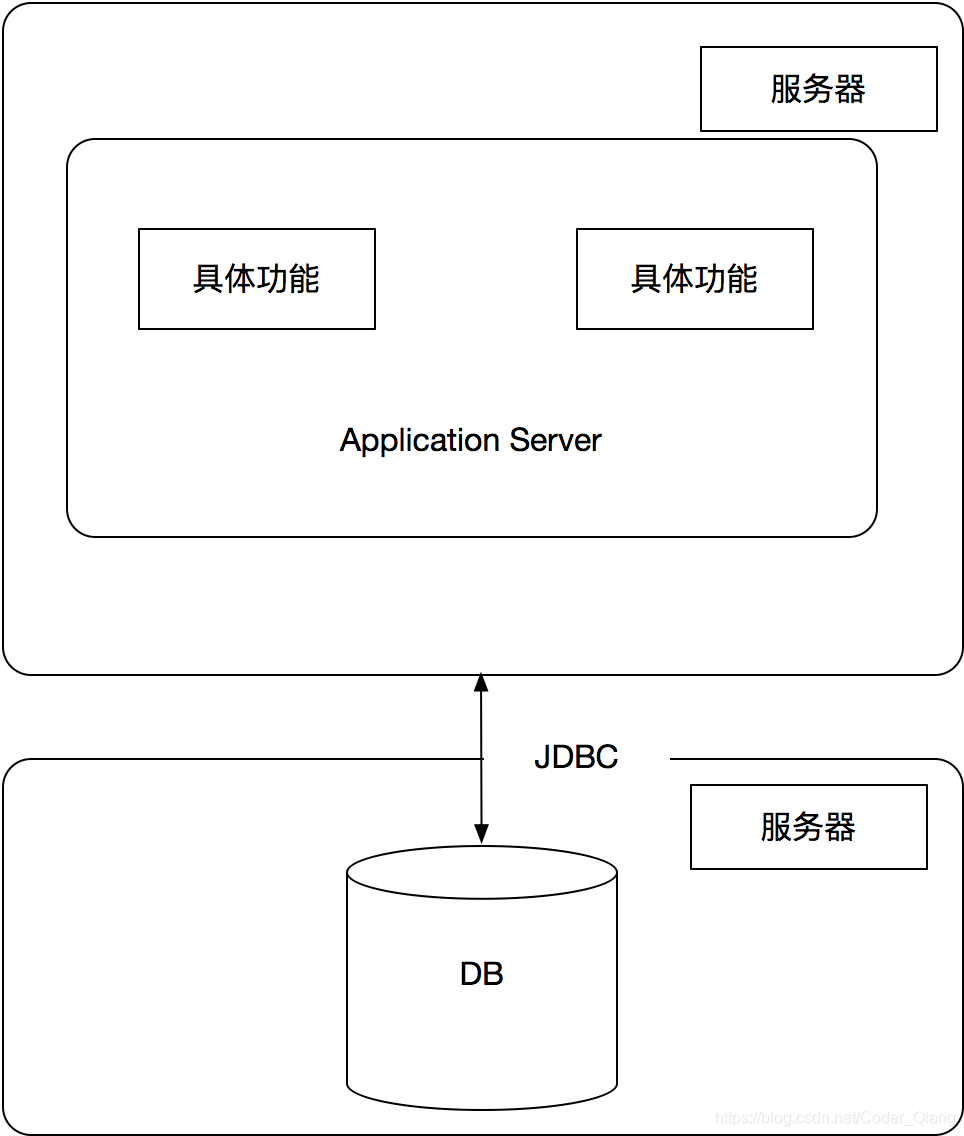
数据库与应用分离
当网站的访问量不断增大的时候,服务器的负载也就持续升高,造成访问缓慢,或者直接宕机,这时候就需要做一些改变,这时候,最容易也是改变最小的方案就是,数据库和应用分离。
-
应用集群
经过上面的应用和数据分离后,以后缓解了一下应用服务器的压力,但当访问量继续不断增大,应用服务器压力还是会越来越大。接下来就是要对引用服务器进行集群处理。当增加多台应用服务器的时候,用户对与服务器的选择就是一个问题,这边有2种解决方案:
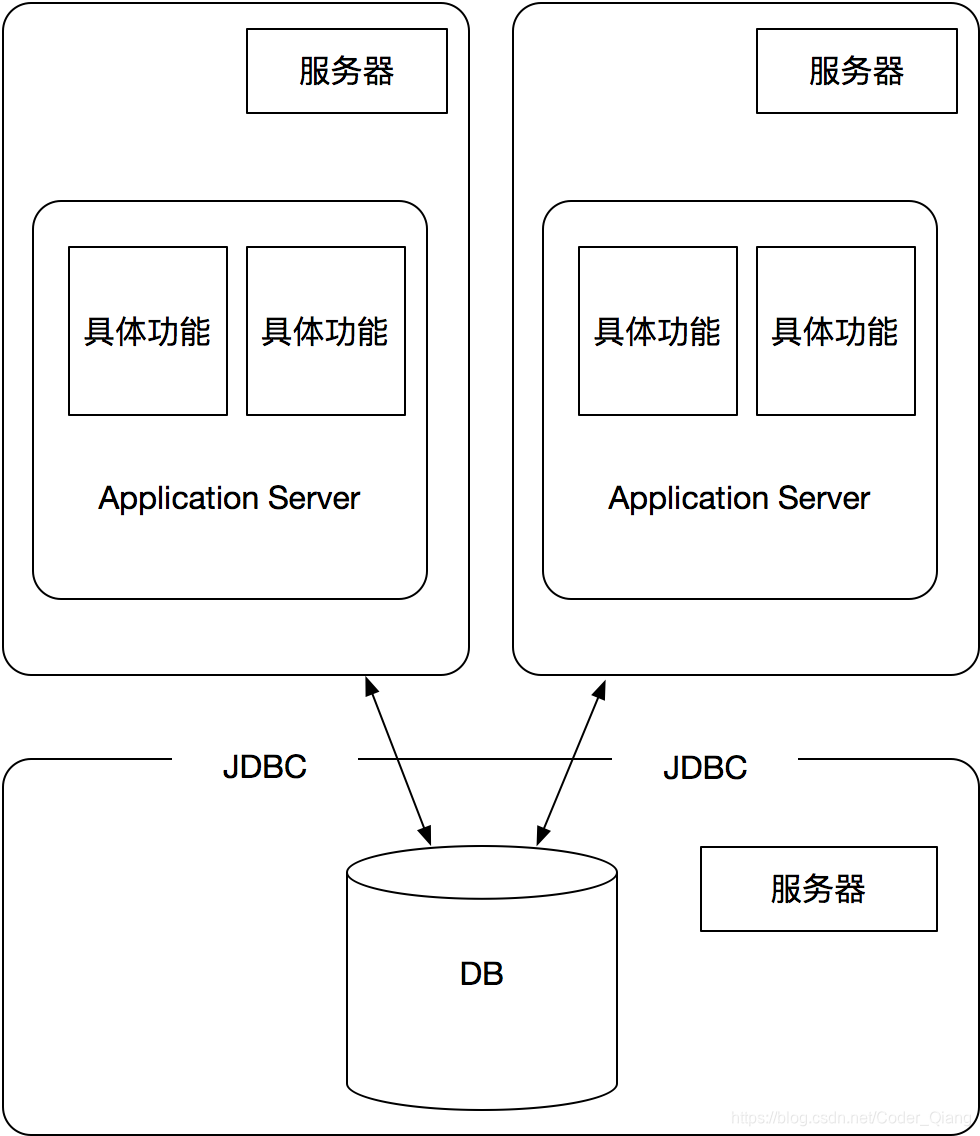
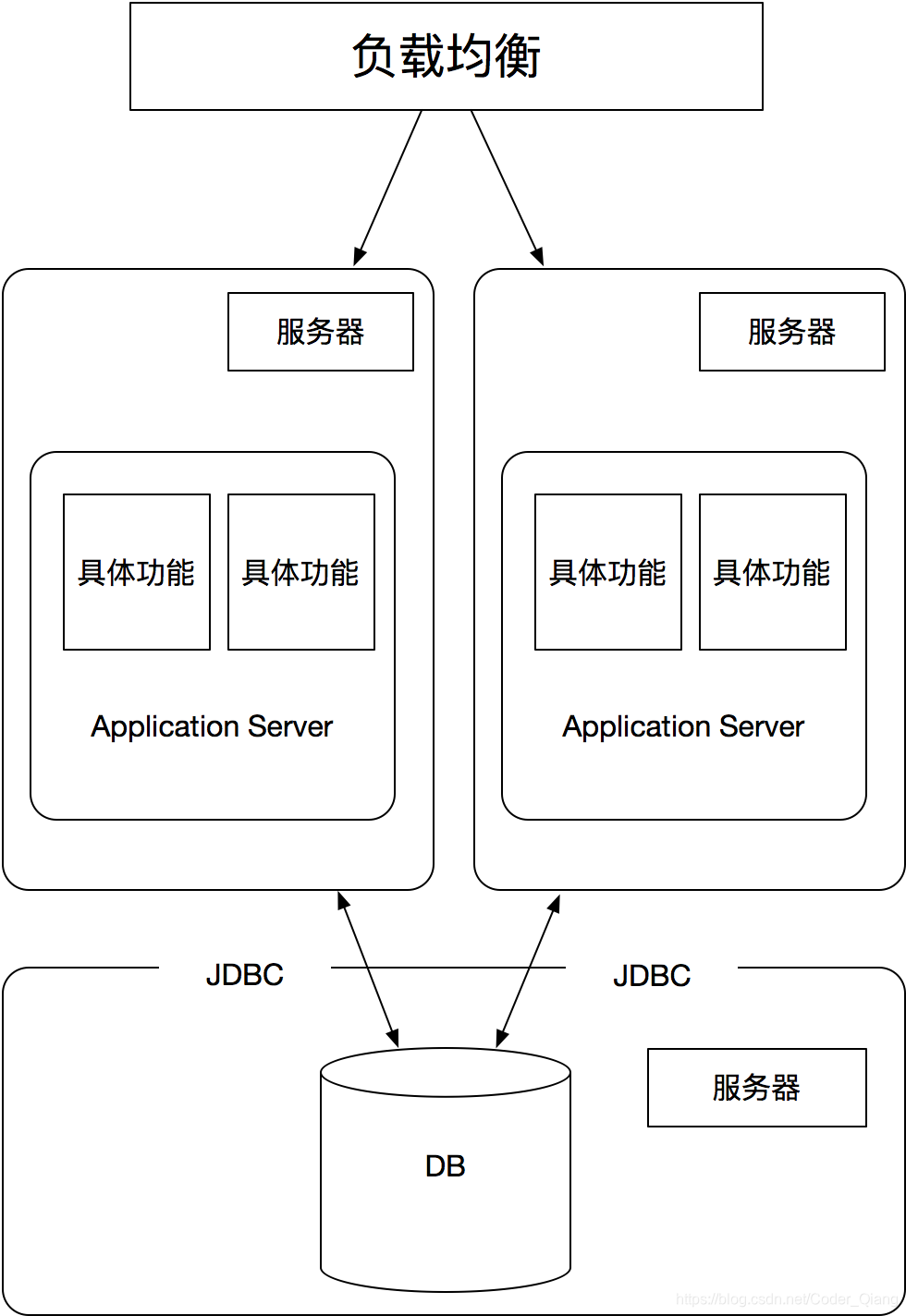
当架构从单体到集群的时候,就会遇到多台服务器一个session怎么共享的问题。
用户使用网站服务的时候,基本上需要浏览器与WEB服务器的多次交互,HTTP协议本事没有状态的,需要基于HTTP协议支持会话状态(Session State)机制。这种机制可以使Web服务器从多次单独的HTTP请求中可以识别这个请求来自于哪一个会话。(这个会话的作用就是可以让Web服务器识别HTTP请求使用户A发起的还是用户B发起的)具体的实现方式:在用户A第一次用浏览器和Web服务器进行交互的时候,Web会分配一个会话标示(SessionId),然后浏览器把这个标示存在Cookie中,然后再接下来用户A发出的所有请求中,浏览器会自动带上这个SessionId来请求Web服务器,Web服务器通过识别会话标示来确实这个请求是用户A发出的。如果浏览器禁用cookie的情况,一般浏览器会把这个标示放到URL参数中。
当用户A访问我们的应用时,因为我们的应用服务器时集群,通过负载均衡把用户A的第一次请求转发到应用1上。应用1返回给用户A一个会话标示a。当下次用户A再次请求的时候,正常情况负载均衡又把用户A的转发调度到应用2上了,而这时候应用2识别不了会话标示a,也就识别不了用户A,通常表现为用户A需要重新登陆。所以当架构到集群的时候,需要解决Session共享问题。
解决方法:
-
Session Sticky
负载均衡根据每一次的请求的会话来进行转发。就是用户A始终转发到应用1上。
问题:
- 如果集群中的一台服务器宕机,那这个服务器上的用户数据就会丢失,如果这些数据包含登陆数据,就会导致这些用户重新登陆
- 会话标示是应用层的信息,那么负载均衡如果要将同一个会话的请求保存到同一个服务器上,就需要进行会话解析,这个开销大
- 负载均衡变成了一个有状态的节点,和无状态的节点相比,内存开销大,容灾方面更麻烦
-
Session Replication
对于服务器上的会话进行同步,即集群中的应用服务器相互之间同步自己的会话数据。
问题:
- 同步Session 数据会造成网络开销,只要Session有变化,就需要同步所有的数据,如果集群数量大,同步带来的网络宽带开销就会越来越大。
- 每一台服务器都要保存所有的Session数据,如果用户量大的话,每台服务器Session数据占用比较严重。
-
Session 集中存储
问题:
- 读写Session数据引入了网络操作,这相对于本级读取增加了时延和不稳定性。但正常通信都发生在内网,影响小。
- 如果集中Session的机器或者集群有问题,会影响应用
对比上面3种,最终用的比较多的是第三种方式。
-
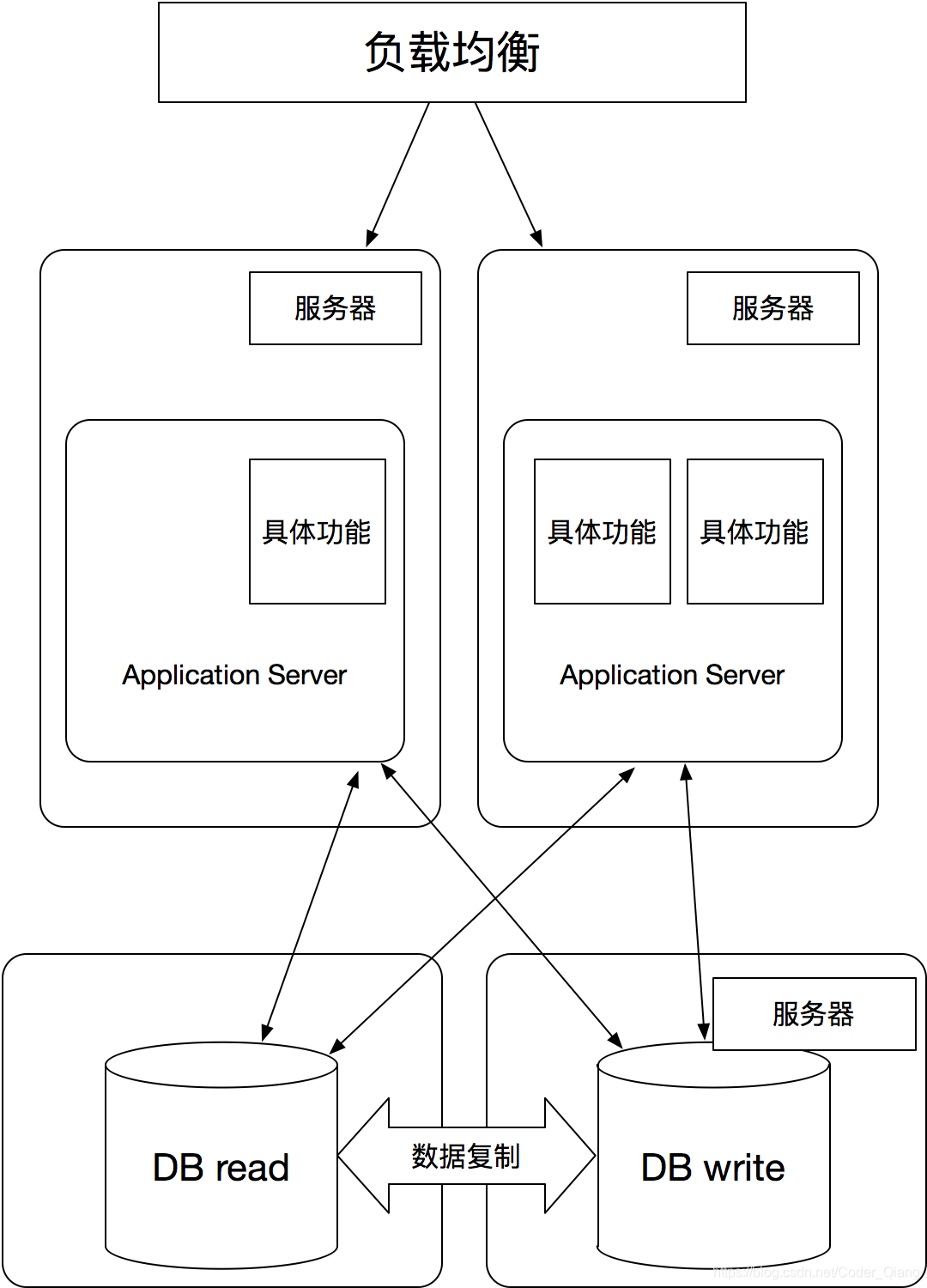
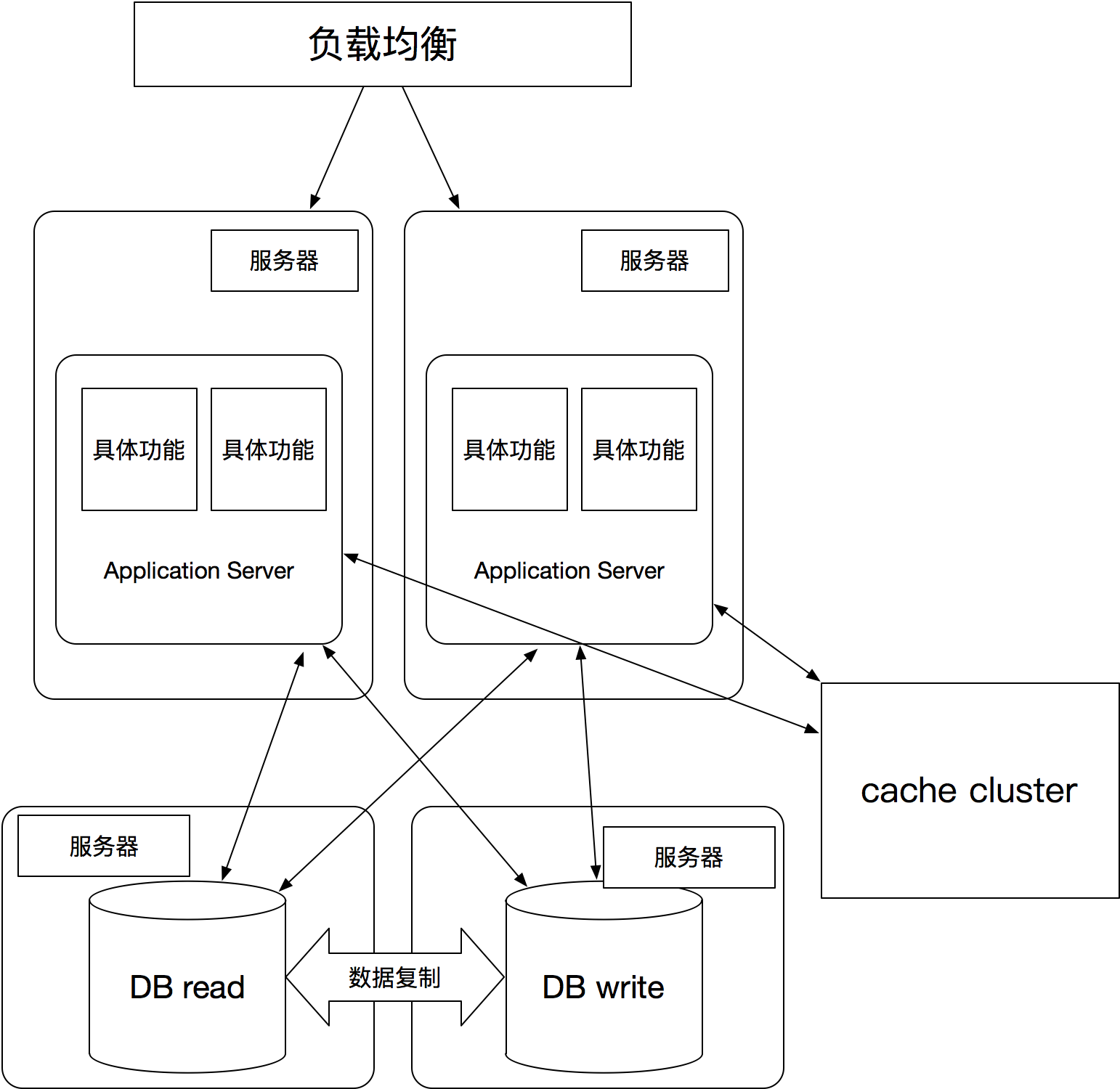
数据读写压力大,读写分离
经过上述应用的集群,解决应用的负载,下面会出现问题就是数据库方面,随着访问量和数据量都在增长,数据库的压力也随之变大,这个时候就可以考虑读写分离(另类的集群),通过增加一个读库,来分担数据库的读写压力。
-
缓存机制
根据28定律,80%的时候我只访问20%数据。所以为了加快对于读取速度,我们加入缓存机制,把热数据放入缓存中,因为缓存读取速度要大大快于数据库的读取的速度。
-
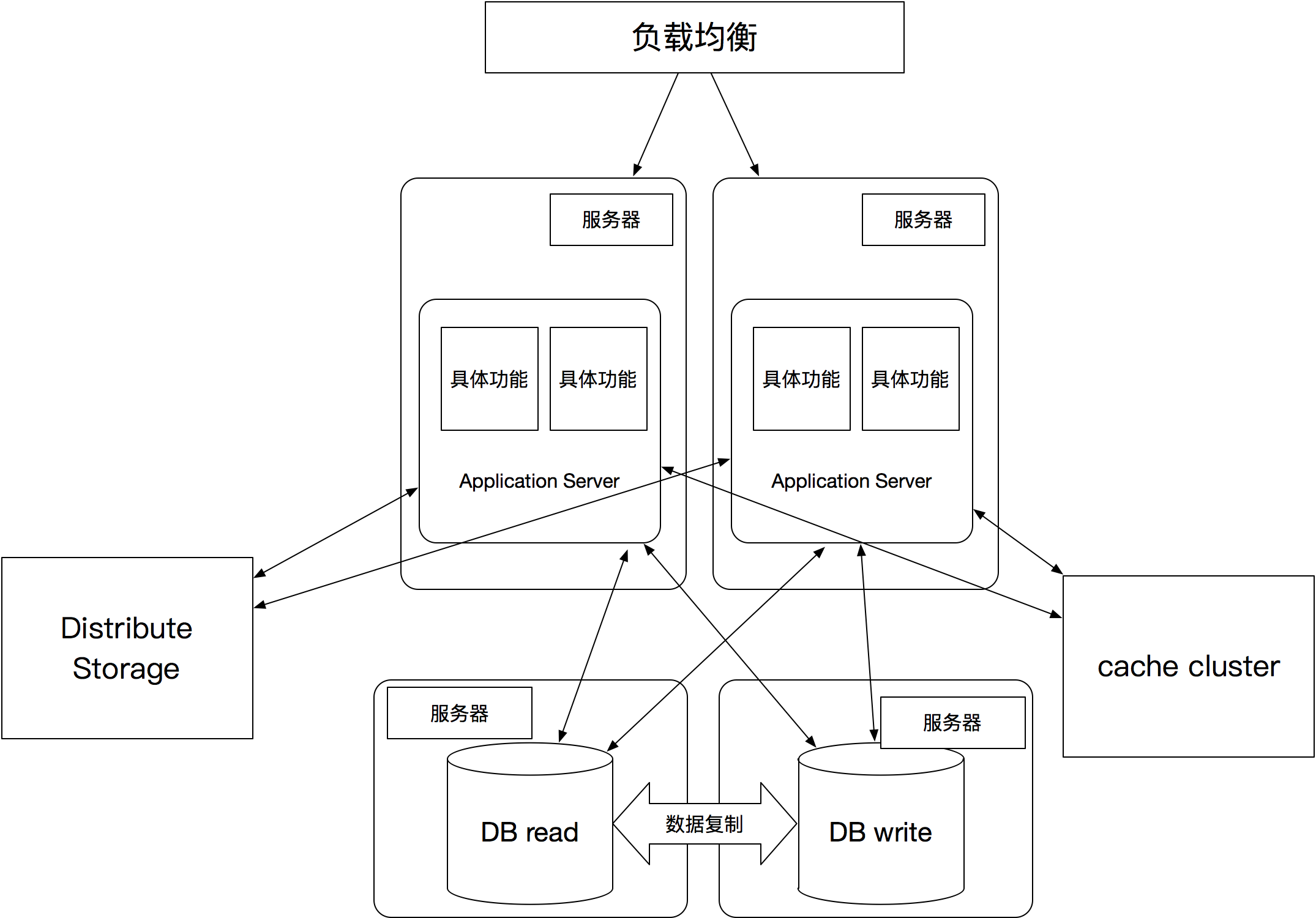
分布式存储系统
弥补关系型数据库的不足,引入分布式存储系统,例如:分布式文件系统,分布式key-value系统,分布式数据库。
-
垂直拆分/水平拆分
对着业务的增加,读写分离也慢慢遇到的瓶颈,这个时候就有垂直拆分/水平拆分两种方式来进一步缓解压力
-
垂直拆分
就是把不同的业务的数据拆分到不同的数据库中,例如电子商务中,商品,用户,交易就可以拆分开。
这种拆分在程序上就需要配置多个数据源,同时还需要考虑业务的事务处理。
-
水平拆分
就是把一个表的数据拆到2个数据库中。一般是是某一个业务的数据表的数据量或者更新量达到单个数据库的瓶颈的时候,会把一个表的数据拆到2个数据库。
-
-
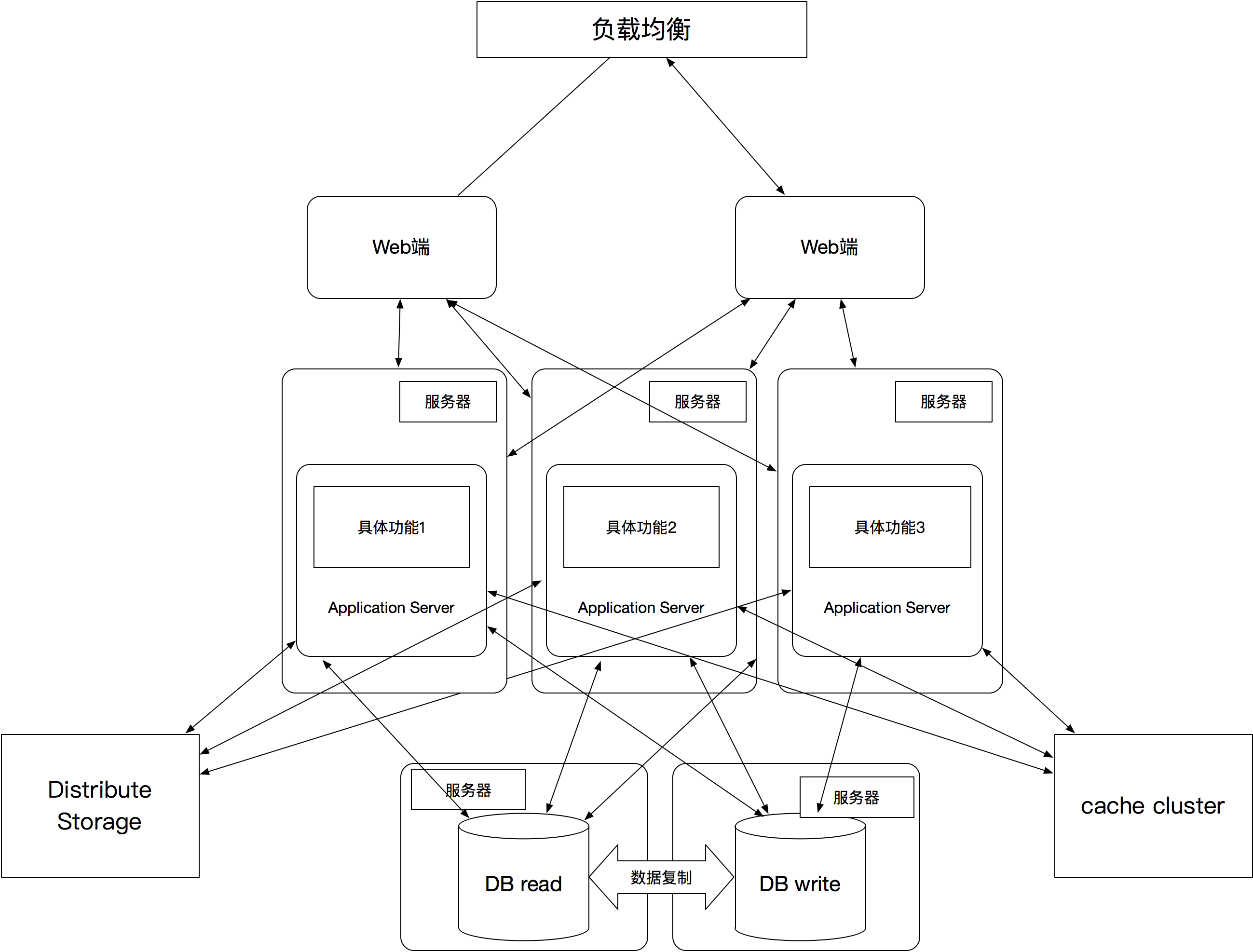
应用拆分
随着读写分离,分布式存储,数据垂直拆分,数据水平拆分的引入,数据方面的问题基本上可以解决。对着业务的增长,应用的功能也越来越多,,应用也越来越大。这时候就可以考虑把应用拆分,拆分几个模块,几个模块直接通过RPC来链接(Dubbo/Spring Cloud)















 1853
1853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











