







1. ThreadLocal
什么是ThreadLocal
ThreadLocal 是 Java 中的一个类,用于在多线程环境下为每个线程提供独立的变量副本。每个线程都可以访问自己的独立变量副本,而不会影响其他线程的副本。这种机制在某些情况下可以简化多线程程序的设计,特别是当多个线程需要访问一些共享的数据,但又需要保持数据的独立性时。
ThreadLocal 主要解决的问题是多线程共享变量的线程安全性。在多线程环境下,共享变量可能导致数据竞争和线程不安全问题,需要通过同步机制来保护。而使用 ThreadLocal,每个线程都可以独立地操作自己的变量副本,从而避免了共享变量的线程安全问。
如何使用ThreadLocal
举个栗子:
public class ThreadLocalExample {
private static ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
Runnable incrementTask = () -> {
int value = threadLocal.get();
value++;
threadLocal.set(value);
System.out.println("Thread " + Thread.currentThread().getId() + ": " + value);
};
Thread thread1 = new Thread(incrementTask);
Thread thread2 = new Thread(incrementTask);
thread1.start();
thread2.start();
}
}
运行代码后我们得到

两个线程中ThreadLocal 存的值都是1,这代表了我们ThreadLocal 在线程中是相互独立的,即在多线程环境下为每个线程提供独立的变量副本
应用场景举例
在 Spring 框架中,事务管理是一个重要的功能,它可以确保数据库操作的一致性和隔离性。在事务管理中,Spring 使用了 ThreadLocal 来管理事务上下文,以保证每个线程在执行数据库操作时都能够正确地参与到事务的管理中。
ThreadLocal 是 Java 提供的一个线程局部变量的机制,它可以在每个线程中存储不同的值,而不会被其他线程共享。在 Spring 的事务管理中,ThreadLocal 被用来存储当前线程的事务上下文,包括事务的隔离级别、事务的传播行为、连接对象等。
下面是一个简化的示例来理解 Spring 的事务管理中如何使用 ThreadLocal:
public class TransactionManager {
private static ThreadLocal<TransactionContext> transactionContext = new ThreadLocal<>();
public static void beginTransaction() {
TransactionContext context = new TransactionContext();
// 设置事务隔离级别、传播行为等属性到 context
transactionContext.set(context);
}
public static void commitTransaction() {
TransactionContext context = transactionContext.get();
// 提交事务
context.commit();
}
public static void rollbackTransaction() {
TransactionContext context = transactionContext.get();
// 回滚事务
context.rollback();
}
}
public class TransactionContext {
// 存储事务属性、连接对象等
// ...
}
// 使用事务
public class Service {
public void performDatabaseOperation() {
TransactionManager.beginTransaction();
try {
// 执行数据库操作
// ...
TransactionManager.commitTransaction();
} catch (Exception e) {
TransactionManager.rollbackTransaction();
}
}
}
在上述示例中,TransactionManager 类通过 ThreadLocal 来存储每个线程的事务上下文,以确保在执行数据库操作时能够正确地参与到事务的管理中。Service 类中的方法通过调用 TransactionManager 中的方法来处理事务。
总之,Spring 的事务管理中使用 ThreadLocal 来管理每个线程的事务上下文,确保在并发环境中不会出现交叉影响,从而实现了数据库操作的一致性和隔离性。
ThreadLocal的实现
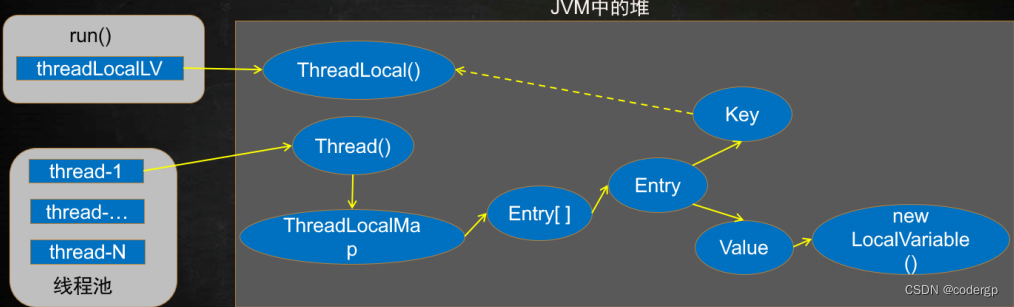
通过我们之前举得栗子,我们会产生一个疑问,为什么都是调用一个对象的get set 方法,但是却会存两份不同的ThreadLocal呢?于是,不得不扒拉下它的源码,见下图
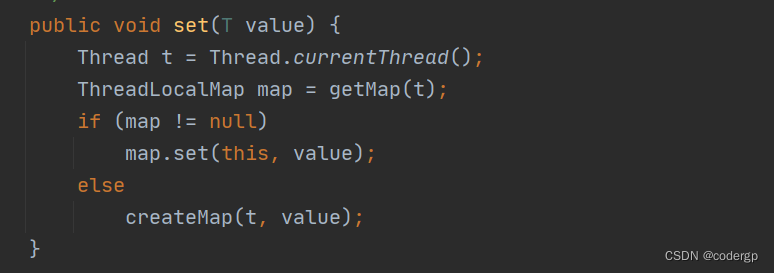
我们发现,这个set 方法中,是通过ThreadLocalMap ,来存数据的,而这个ThreadLocalMap是Thread 的一个静态变量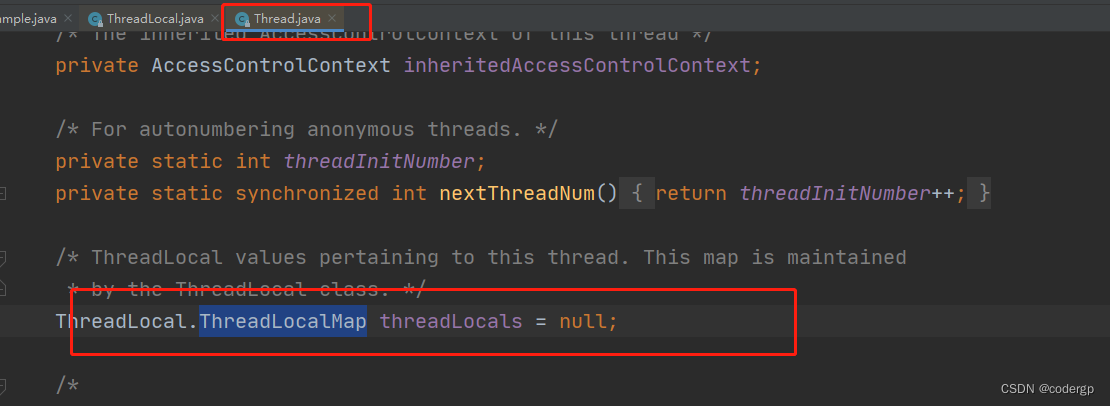
这就意味着,每一个Thread 都会有一个单独的ThreadLocalMap ,接下来我们再看ThreadLocalMap的源码,
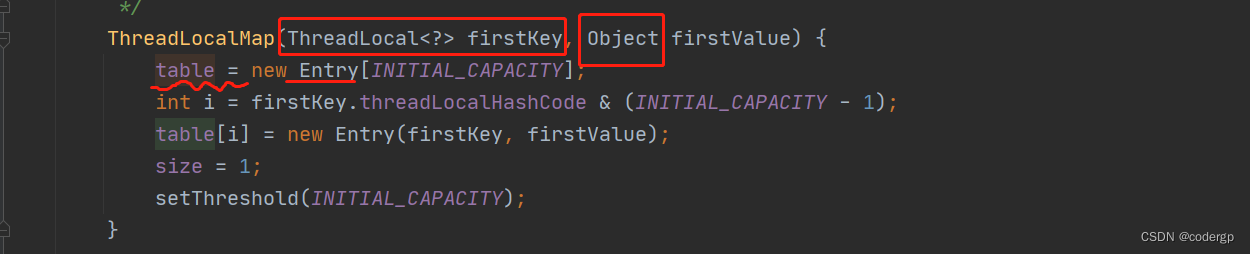
通过它的构造函数可以发现,他和普通的map一样,也是存的键值对Entry,需要注意的是,这个key是ThreadLocal(可以理解为主程序中ThreadLocal的副本),我们再看下这个Entry
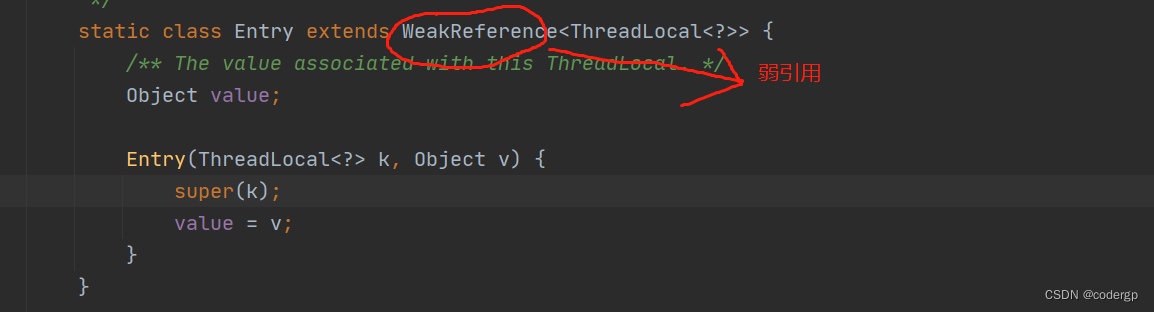
这样我们就知道了,每个线程都有自己的ThreadLoccalMap 属性,而这个Map存的是以不同的ThreadLocal 副本为key ,set 的值为 value的键值对,所以不同线程的数据不会相互干扰,下面我们写个栗子来运用多个ThreadLocal 来存数据
public class MultiThreadLocalExample {
private static ThreadLocal<Integer> integerThreadLocal = ThreadLocal.withInitial(() -> 0);
private static ThreadLocal<String> stringThreadLocal = ThreadLocal.withInitial(() -> "");
public static void main(String[] args) {
Thread thread = new Thread(() -> {
integerThreadLocal.set(42);
stringThreadLocal.set("Hello, ThreadLocal!");
System.out.println("Integer value: " + integerThreadLocal.get());
System.out.println("String value: " + stringThreadLocal.get());
integerThreadLocal.remove();
stringThreadLocal.remove();
});
thread.start();
}
}
需要注意的是,ThreadLocalMap 和我们 熟知的 HashMap 是有区别的,我们知道当Hash产生冲
突时,HashMap 采用的是 链地址法,即将形同hash 存在一个链表中,但是ThreadLocalMap 并不
是这样的,它用的是开放地址法,与链地址法相对。在开放地址法中,当哈希冲突发生时,新元素
会被插入到哈希表的其他位置,而不是链表中。开放地址法的基本思想是,通过一系列探测方法,
线性地探测哈希表的下一个可用位置,直到找到一个空闲的位置或者达到一定的尝试次数。具体的
探测方法包括线性探测、二次探测、双重哈希等。因为ThreadLocalMap 的设计是为了在保持简单
性和高性能的同时,能够满足多线程环境下的要求。通过线性探测法,ThreadLocalMap 在处理哈
希冲突时能够快速找到下一个可用的槽位,从而避免链地址法所带来的额外开销。
ThreadLocal带来的内存泄漏问题
首先我们需要知道一个概念:
垃圾回收的时机是由垃圾回收器决定的,它是允许一些浮动垃圾等到下次回收时再清理,之前的三
色标记算法中又说到过;而线程终止的处理可能需要一些时间,这些因素都可能导致线程结束后
ThreadLocalMap 不会立即被回收。
上图展示了 Thread 的引用链。虚线表示弱引用,实线表示强引用。之前提到过 Entry 的源代码,
我们了解到 ThreadLocal 使用弱引用。因为 ThreadLocal 使用了弱引用,所以当线程结束后,
ThreadLocal 会被直接回收。这种设计避免了我们手动清理 ThreadLocal 的需求。然而,当
ThreadLocal 被回收后,ThreadLocalMap 仍然存在于引用链中。Entry 对 value 仍然是一个强引
用,导致 Entry 中存在着键为 null,值为 value 的这种键值对。这会导致部分空间不能被立即回
收,只有在下次垃圾回收时才会被回收,或者重新启动线程再次调用 ThreadLocalMap ,这样就产
生了内存泄漏的问题,所以我们需要再使用的时候加上remove进行手动清理。虽说,随着时间的
推移和垃圾回收器的工作,这些无用的ThreadLocalMap 实例最终会被回收,不会一直占用内存,
但是还是建议手动清理,不要浪费gc的资源。
举个栗子:
public class ThreadLocalExample {
private static ThreadLocal<String> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
threadLocal.set("Hello, ThreadLocal!");
// Perform some work using the ThreadLocal value
// After using the ThreadLocal value, remove it
threadLocal.remove();
// Now the ThreadLocal value is cleaned up
}
}
2.CAS和Atomic
什么是并发中的原子性(原子操作)?
原子操作是指在多线程环境下执行的一个不可分割的、不可中断的操作。这意味着无论有多少个线
程同时执行原子操作,它们的执行顺序和结果都是一致的,不会出现竞态条件或数据不一致的问
题。原子操作可以保证线程安全和数据一致性。简单解释下,我们直接拿run方法来说,对于线程
的 run 方法来说,确保其原子性的含义是,在一个线程的 run 方法执行过程中,不会被其他线程中
断或干扰,直到 run 方法中的所有代码执行完毕。这样可以避免多个线程在执行过程中交叉干扰,
导致不确定的结果。
举个原子操作的栗子:
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerExample {
public static void main(String[] args) {
AtomicInteger counter = new AtomicInteger(0);
// 多个线程同时对 counter 进行自增操作
Runnable task = () -> {
for (int i = 0; i < 5; i++) {
int currentValue = counter.incrementAndGet(); // 原子自增操作
System.out.println(Thread.currentThread().getName() + " - Value: " + currentValue);
}
};
Thread thread1 = new Thread(task, "Thread 1");
Thread thread2 = new Thread(task, "Thread 2");
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Final Value: " + counter.get());
}
}
计算结果为10 ,如果不适用AtomicInteger那么结果就会小于等于10 了
Java原子操作的实现
那么原子操作是靠什么实现的呢?答案就是CAS!那么CAS是什么呢?
CAS 即 Compare and Swap 比较后替换 ,它是一种基于硬件指令的操作,它可以在一个原子性
的步骤中比较某个内存位置的值和一个期望值,如果相等则替换为新的值,如果发现当前内存位置
的值不符合预期值,就会进入一个循环(自旋),不断地尝试进行 CAS 操作,每次失败后它都会
获取到最新的期望值,然后再次尝试直到操作成功为止,或者达到一定的尝试次数限制。
CAS 机制的优势在于它不需要使用锁,避免了锁的开销和线程切换的开销,因此在一些高并发的
情况下,使用 CAS 可以提供更好的性能。然而,CAS 也有一些问题,比如 ABA 问题和循环时间
长等,需要注意在使用时进行适当的处理。
ABA问题:
举个例子来解释 ABA 问题:
- 初始时,共享变量的值为 A。
- 线程 T1 将共享变量的值从 A 修改为 B。
- 线程 T1 又将共享变量的值从 B 修改回 A。
在上述操作中,如果一个线程 T2 在操作过程中使用 CAS 判断共享变量的值是否为 A,由于经过了一轮操作后共享变量的值确实变回了 A,所以 CAS 操作可能会成功,尽管实际上中间发生了变化。
解决 ABA 问题的常见方法是使用版本号(或时间戳)来追踪共享变量的变化。每次进行 CAS 操作时,不仅比较共享变量的值是否与预期值相等,还要比较版本号。当共享变量发生变化时,版本号也会随之改变。这样,即使共享变量的值在操作过程中发生了变化,只要版本号不一致,CAS 操作仍会失败。
Java 并发包中的原子类,比如 AtomicStampedReference,提供了解决 ABA 问题的实现。它使用了版本号来确保 CAS 操作的正确性,从而避免了 ABA 问题的发生。
循环时间:
循环时间问题就是线程太多了,一直在自旋,这样会十分消耗资源,效率会变慢,甚至不如
synchronize,那如何解决呢?目前提供两个简单的方案:
调整自旋次数:可以设置一个合理的自旋次数限制,超过限制后放弃自旋,采取其他策略。
自适应自旋:根据当前系统的负载情况,动态地调整自旋次数,避免在高负载时过长的自旋。
只能保证一个变量个共享原子操作:
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享
变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。还有一个取巧的办法,
就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量 i=2,j=a,合并一下
ij=2a,然后用 CAS 来操作 ij。从 Java 1.5 开始,JDK 提供了 AtomicReference 类来保证引用对
象之间的原子性,就可以把多个变量放在一个对象里来进行 CAS 操作。















 6286
6286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









