




 本文介绍了聚类算法的目的和概念,包括层次聚类、基于原型的聚类和基于密度的聚类。重点讨论了k-Means、模糊c均值(FCM)、凝聚层次聚类和DBSCAN算法,分析了它们的基本思想、优缺点以及适用场景,并提供了Python代码示例。
本文介绍了聚类算法的目的和概念,包括层次聚类、基于原型的聚类和基于密度的聚类。重点讨论了k-Means、模糊c均值(FCM)、凝聚层次聚类和DBSCAN算法,分析了它们的基本思想、优缺点以及适用场景,并提供了Python代码示例。
欢迎光临我的博客:HaoyuHu’s Blog
参考自初识聚类算法:K均值、凝聚层次聚类和DBSCAN,模糊聚类FCM算法。
近期做完了labmu的tunet3.0,总算有时间学习一些东西了。目前想学的有聚类分析、图像识别算法和计算机网络方面的知识。在暑假实习期间,开始着手游戏编程。
聚类的目的
将数据划分为若干个簇,簇内相似性大,簇间相似性小,聚类效果好。用于从数据中提取信息和规律。
聚类的概念
- 层次与划分:当允许存在子簇时,将数据按照层次划分,最终得到的是一颗树。树中包含的层次关系即为聚类划分的层次关系。各个子簇不重叠,每个元素都隶属于某个level的子簇中。
- 互斥、重叠与模糊:这个概念的核心在于,所有集合元素都不完全隶属于任何一个簇,而是按照一定隶属度归属于所有簇。对于任意一个元素,其隶属度和一般为1。
- 完全与部分:完全聚类要求所有数据元素都必须有隶属,而部分聚类则允许噪音存在,不隶属于任何簇。
簇的分类
- 明显分离:不同簇间任意元素距离都大于簇内元素距离。从图像上观察是明显分离类型的簇。
- 基于原型:任意元素与它所隶属的簇的簇中心(簇内元素集合的质心)的距离大于到其他簇中心的距离。
- 基于图:图中节点为对象,弧权值为距离。类似于明显分离的定义或基于原型的定义,只是用弧权值代替了人为规定的距离。
- 基于密度:基于密度的簇分类是较为常用,也是应用范围最为广泛的一种分类方法。元素的稠密程度决定了簇的分布。当存在并希望分辨噪声时,或簇形状不规则时,往往采用基于密度的簇分类。
常用的聚类分析算法
- 基本k均值:即k-means算法。簇的分类是基于原型的。用于已知簇个数的情况,且要求簇的形状基本满足圆形,不能区分噪声。
- 凝聚层次聚类:起初各个点为一个簇,而后按照距离最近凝聚,知道凝聚得到的簇个数满足用户要求。
- DBscan:基于密度和划分的聚类方法。
聚类算法的基本思想
(1) 基本k均值聚类(hard c-means, HCM)
方法很简单,首先给出初始的几个簇中心。将所有元素按照到簇中心最近的归属原则,归属到各个簇。然后对各个簇求解新的簇中心(元素集合质心)。重复上述步骤直到质心不再明显变化后,即完成聚类。
采用何种距离可按照数据性质或项目要求。距离的分类可以参考A-star算法概述及其在游戏开发中的应用分析中提到的曼哈顿距离、对角线距离、欧几里得距离等。实际上相当于求解一个全局状态函数的最小值问题,状态函数是各个元素到最近簇中心的距离之和。
该算法的特点有如下几点:
- 其一,不一定得到全局最优解,当初始簇中心不满足要求时,可能只能得到局部最优解,当然有学者通过一定的预处理使得得到的初始簇中心满足一定条件,从而能够得到全局最优解,并将方法名改为k-means++。
- 其二,不能排除噪声点对聚类的影响。
- 其三,要求簇形状接近圆形。
- 要求完全聚类的情况。
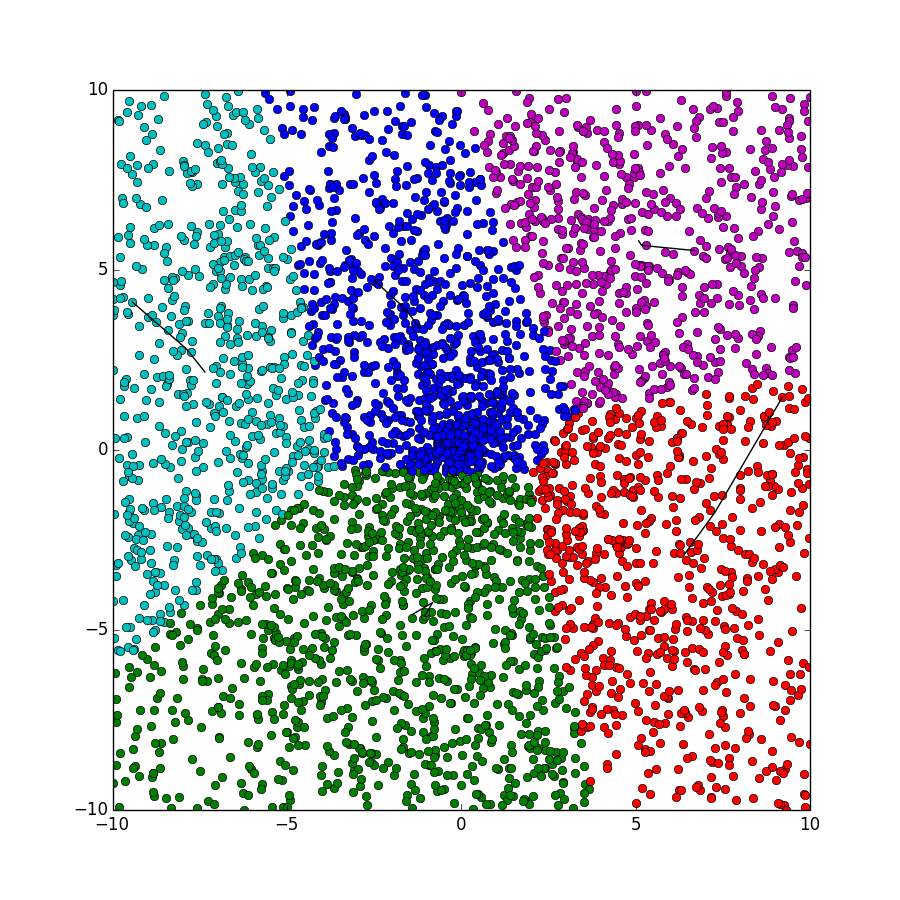
python代码
此代码使用的是k-means++算法,采用约定的方法使得到的初始聚类中心能够在后面的迭代过程中收敛到最优解。
import math
import collections
import random
import copy
import pylab
try:
import psyco
psyco.full()
except ImportError:
pass
FLOAT_MAX = 1e100
class Point:
__slots__ = ["x", "y", "group"]
def __init__(self, x = 0, y = 0, group = 0):
self.x, self.y, self.group = x, y, group
def generatePoints(pointsNumber, radius):
points = [Point() for _ in xrange(pointsNumber)]
for point in points:
r = random.random() * radius
angle = random.random() * 2 * math.pi
point.x = r * math.cos(angle)
point.y = r * math.sin(angle)
return points
def solveDistanceBetweenPoints(pointA, pointB):
return (pointA.x - pointB.x) * (pointA.x - pointB.x) + (pointA.y - pointB.y) * (pointA.y - pointB.y)
def getNearestCenter(point, clusterCenterGroup):
minIndex = point.group
minDistance = FLOAT_MAX
for index, center in enumerate(clusterCenterGroup):
distance = solveDistanceBetweenPoints(point, center)
if (distance < minDistance):
minDistance = distance
minIndex = index
return (minIndex, minDistance)
def kMeansPlusPlus(points, clusterCenterGroup):
clusterCenterGroup[0] = copy.copy(random.choice(points))
distanceGroup = [0.0 for _ in xrange(len(points))]
sum = 0.0
for index in xrange(1, len(clusterCenterGroup)):
for i, point in enumerate(points):
distanceGroup[i] = getNearestCenter(point, clusterCenterGroup[:index])[1]
sum += distanceGroup[i]
sum *= random.random()
for i, distance in enumerate(distanceGroup):
sum -= distance;
if sum < 0:
clusterCenterGroup[index] = copy.copy(points[i])
break
for point in points:
point.group = getNearestCenter(point, clusterCenterGroup)[0]
return
def kMeans(points, clusterCenterNumber):
clusterCenterGroup = [Point() for _ in xrange(clusterCenterNumber)]
kMeansPlusPlus(points, clusterCenterGroup)
clusterCenterTrace = [[clusterCenter] for clusterCenter in clusterCenterGroup]
tolerableError, currentError = 5.0, FLOAT_MAX
count = 0
while currentError >= tolerableError:
count += 1
countCenterNumber = [0 for _ in xrange(clusterCenterNumber)]
currentCenterGroup = [Point() for _ in xrange(clusterCenterNumber)]
for point in points:
currentCenterGroup[point.group].x += point.x
currentCenterGroup[point.group].y += point.y
countCenterNumber[point.group] += 1
for index, center in enumerate(currentCenterGroup):
center.x /= countCenterNumber[index]
center.y /= countCenterNumber[index]
currentError = 0.0
for index, singleTrace in enumerate(clusterCenterTrace):
singleTrace.append(currentCenterGroup[index])
currentError += solveDistanceBetweenPoints(singleTrace[-1], singleTrace[-2])
clusterCenterGroup[index] = copy.copy(currentCenterGroup[index])
for point in points:
point.group = getNearestCenter(point, clusterCenterGroup)[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2017
2017


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








