







FCM与K-Means的实现及对比
1. Fuzzy C-means的基本原理
Fuzzy C-means (FCM) 算法通过优化目标函数得到每个样本点对所有类中心的隶属度,从而对样本进行自动分类。
预先确定好待分类的样本应分成几类,然后按照最优原则进行在分类,经多次迭代直到分类比较合理为止。
在分类过程中可认为某个样本以某一隶属度隶属某一类,又以某一隶属度隶属于另一类。
这样,样本就不是明确的属于或不属于某一类。
若样本集有n个样本要分成c类,则他的模糊划分矩阵为c×n。
该矩阵有如下特性:
- 每一样本属于各类的隶属度之和为1。
- 每一类模糊子集都不是空集。
对数据集X进行分类,若将这些数据划分成C个类的话,那么对应的就有C个类中心为Ci,每个样本Xj属于某一类Ci的隶属度定为Uij,那么定义一个FCM目标函数及其约束条件如下:


目标函数(1)由相应样本的隶属度与该样本到各类中心的距离相乘组成的,式(2)为约束条件,也就是一个样本属于所有类的隶属度之和要为 1 。
式(1)中的m是一个隶属度的因子,一般为2 ,||Xj - Ci|| 表示Xj到中心点Ci的欧式距离。
目标函数J越小越好,需求得目标函数J的极小值。
Uij的迭代公式:
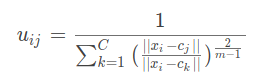
Ci的迭代公式:
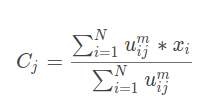
在迭代过程中目标函数J一直在变化,逐渐绉向稳定。
当J不在变化时就认为算法收敛到一个较好的结果了。
2. 准备数据集
2.1 数据集来源
(http://archive.ics.uci.edu/ml/datasets/Page+Blocks+Classification)
2.2 数据集介绍
Page Blocks Classification Data Set
(页面模块分类数据集)
数据集具体信息:
5473个例子来自54个不同的文档。每个观测都涉及一个块。所有属性都是数字。
5473个记录数,10个特征数,5个类别。
摘要:该数据集用于分类,对被分割过程检测到的文档页面布局中的所有块进行分类。

数据集原主:
Donato Malerba
目前就职于巴里·奥尔多·莫罗大学计算机科学系。他是thye部门的主管和知识发现与数据工程(KDDE)小组的负责人。Donato从事数据科学研究,特别是数据挖掘、机器学习和大数据。
特征信息:
height: integer. | Height of the block.
lenght: integer. | Length of the block.
area: integer. | Area of the block (height * lenght);
eccen: continuous. | Eccentricity of the block (lenght / height);
p_black: continuous. | Percentage of black pixels within the block (blackpix / area);
p_and: continuous. | Percentage of black pixels after the application of the Run Length Smoothing Algorithm (RLSA) (blackand / area);
mean_tr: continuous. | Mean number of white-black transitions (blackpix / wb_trans);
blackpix: integer. | Total number of black pixels in the original bitmap of the block.
blackand: integer. | Total number of black pixels in the bitmap of the block after the RLSA.
wb_trans: integer. | Number of white-black transitions in the original bitmap of the block.
相关文献:
Malerba, D., Esposito, F., and Semeraro, G. “A Further Comparison of Simplification Methods for Decision-Tree Induction.” In D. Fisher and H. Lenz (Eds.), “Learning from Data: Artificial Intelligence and Statistics V”, Lecture Notes in Statistics, Springer Verlag, Berlin, 1995.
[Web Link]
Esposito F., Malerba D., & Semeraro G. Multistrategy Learning for Document Recognition. Applied Artificial Intelligence, 8, pp. 33-84, 1994
[Web Link]
3. 读取数据集
3.1 读取page-blocks.data
fp=open("page-blocks.data","r")
lines=fp.readlines()
fp.close()
3.2 整理数据集格式
import numpy as np
X=[]
y=[]
for i in range(len(lines)):
X.append([])
for feature in lines[i].split()[:-1]:
X[i].append(float(feature))
y.append(int(lines[i].split()[-1])-1)
X=np.array(X)
y=np.array(y)
4. FCM的python实现
- C=5
import numpy as np
from skfuzzy.cluster import cmeans
import time
tic0 = time.clock()
center, u, u0, d, jm, p, fpc = cmeans(X.T, m=2, c=5, error=0.005, maxiter=1000)
toc0 = time.clock()
test_y = np.argmax(u, axis=0)
- C=4
import numpy as np
from skfuzzy.cluster import cmeans
import time
tic0 = time.clock()
center, u, u0, d, jm, p, fpc = cmeans(X.T, m=2, c=4, error=0.005, maxiter=1000)
toc0 = time.clock()
test_y = np.argmax(u, axis=0)
- C=3
import numpy as np
from skfuzzy.cluster import cmeans
import time
tic0 = time.clock()
center, u, u0, d, jm, p, fpc = cmeans(X.T, m=2, c=3, error=0.005, maxiter=1000)
toc0 = time.clock()
test_y = np.argmax(u, axis=0)
5. K-means的python实现
- K=5
from sklearn.cluster import KMeans
import time
tic0 = time.clock()
y_pred = KMeans(n_clusters=5).fit_predict(X)
toc0 = time.clock()
- K=4
from sklearn.cluster import KMeans
import time
tic0 = time.clock()
y_pred = KMeans(n_clusters=4).fit_predict(X)
toc0 = time.clock()
- K=3
from sklearn.cluster import KMeans
import time
tic0 = time.clock()
y_pred = KMeans(n_clusters=3).fit_predict(X)
toc0 = time.clock()
6. 聚类性能度量
6.1 聚类性能度量指标
聚类性能度量是将聚类结果与某个参考模型进行比较,比如与数据集中的label进行进行比较,称为“外部指标”。
对于“外部指标”,我们的度量目的就是要使得我们的聚类结果与参考模型尽可能相近,通常通过将聚类结果与参考模型结果对应的簇标记向量进行两两比对,来生成具体的性能度量。
其度量的中心思想是:聚类结果中被划分到同一簇中的样本在参考模型中也被划分到同一簇的概率越高代表聚类结果越好。

(图片来源于网络)
6.1.1 Jaccard系数

6.1.2 FM指数

6.1.3 Rand指数

上述度量指标值在[0,1]区间,值越大越好。
6.2 Python代码实现
def evaluate(y, t):
a, b, c, d = [0 for i in range(4)]
for i in range(len(y)):
for j in range(i+1, len(y)):
if y[i] == y[j] and t[i] == t[j]:
a += 1
elif y[i] == y[j] and t[i] != t[j]:
b += 1
elif y[i] != y[j] and t[i] == t[j]:
c += 1
elif y[i] != y[j] and t[i] != t[j]:
d += 1
return a, b, c, d
def external_index(a, b, c, d, m):
JC = a / (a + b + c)
FMI = np.sqrt(a**2 / ((a + b) * (a + c)))
RI = 2 * ( a + d ) / ( m * (m + 1) )
return JC, FMI, RI
def evaluate_it(y, t):
a, b, c, d = evaluate(y, t)
return external_index(a, b, c, d, len(y))
7. 运行结果及分析
7.1 K=5,C=5时的5次运行结果
First:


Second:


Third:


Fourth:


Fifth:


7.2 K=4,C=4时的5次运行结果
First


Second


Third


Fourth


Fifth


7.3 K=3,C=3时的5次运行结果
First


Second


Third


Fourth


Fifth


8. FCM和K-Means的对比
- 对于K-means算法,每一行只会有一个元素为1,其他均为0,对于FCM算法,每一行的归属概率之和为1。
- 根据运行结果可得:K-means的运行时间优于FCM算法。
- K-Means属于硬聚类,FCM属于软聚类;K-Means计算的值非0即1,FCM通过赋予隶属度权重,计算概率(百分比)来判断当前数据哪一个cluster。
- FCM算法的计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
- FCM算法的缺点:当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
- FCM是对J目标函数求极小值,也就是说我们得到的结果可能是目标函数的局部极值点或者是鞍点。















 3460
3460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









