






我之前给小伙伴们推荐过不少大模型相关的产品,这些产品看起来很美,但是它们要么对国内有限制,要么是申请制/邀请制,自己想搞个账号去体验一下都是很难的事情,前一段朋友圈还经常看到有人在晒“申请通过了”,“第一次拿到xxx的体验账号”之类的东西。
不过这也容易理解,训练大模型是一件非常烧钱的事情,顶级的GPU不但非常贵,还买不到,大公司搞起来都不容易,更别说小公司了。即使是每月付费20美元的GPT4,还限制用户每天和大模型的对话次数,可见成本是很高的。
最近我看到一个消息,科大讯飞宣布:讯飞星火认知大模型面向全民开放了!
星火要燎原了!
用户可以在各大应用商店下载“讯飞星火”APP 或登陆“讯飞星火”官网直接注册使用,再也不用审核,不用邀请了。
大家可以通过我的专属二维码直接注册使用,开发者专属权益:个人开发者最高可申请400万Tokens,企业用户最高免费申请1000万Tokens

开放14小时后,讯飞星火的用户数突破100万!
上个月讯飞星火发布V2.0,我就注意到在它写代码这件事儿上有突破性的进展,基于 Python 和 C++进行代码写作的能力已高度逼近 ChatGPT,差距仅为 1%和 2%。
当时我说“国内的大模型终于学会写代码了”,讯飞星火在写代码这方面应该是国内领先的。
比如让它用Python创建一个贪吃蛇游戏。
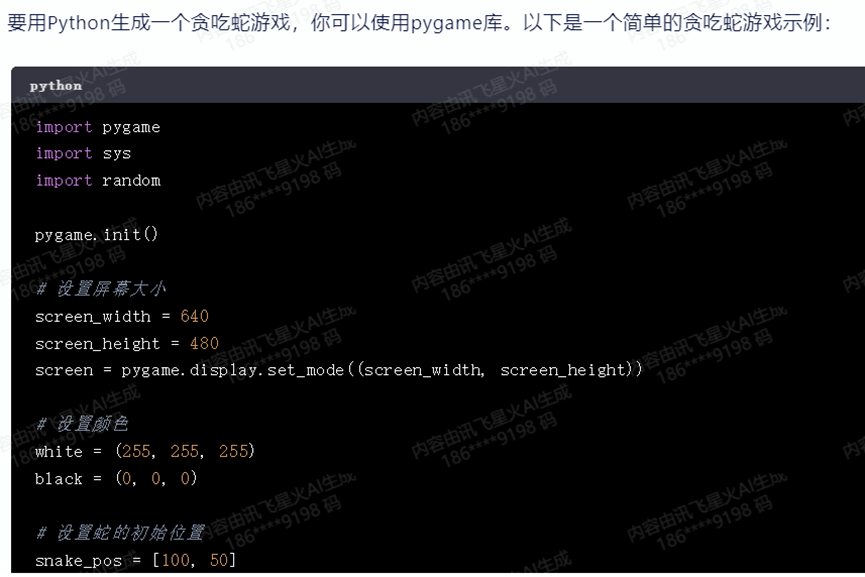
代码在几秒内就生成了,玩起来的效果是这样的:

可以说,完成度非常高,游戏的基本功能都实现了,剩下一些细节,比如改变颜色什么的,我们可以自己稍加调整即可。
再比如让它生成一个业务强相关的代码:
有一个DSL文件(tax.dsl),你需要写一个类(DSLParser)来解析它的内容,解析的时候用一个类TaxBracket表示税率区间,用Deduction表示低免额然后用另外一个类TaxCalculator来计算应纳税额,用Java来实现
tax.dsl文件的内容如下:
// 定义税率区间
tax_bracket 1
range: 0 - 15000
rate: 5%
tax_bracket 2
range: 15001 - 45000
rate: 10%
tax_bracket 3
range: 45001 - 120000
rate: 20%
tax_bracket 4
range: 120001 - 200000
rate: 30%
tax_bracket 5
range: 200001 and above
rate: 40%
// 定义抵免额
deduction Standard
amount: 5000
deduction Health_Insurance
amount: 2000
deduction Retirement_Savings
amount: 3000对DSL解析完成以后,用户会输入类似下面的内容,你需要解析它,然后调用TaxCalculator进行计算
income: 80000
deductions: Standard, Health_Insurance, Retirement_Savings
calculate_tax这段业务逻辑相对是比较复杂的,但是讯飞星火的代码生成的也不错。
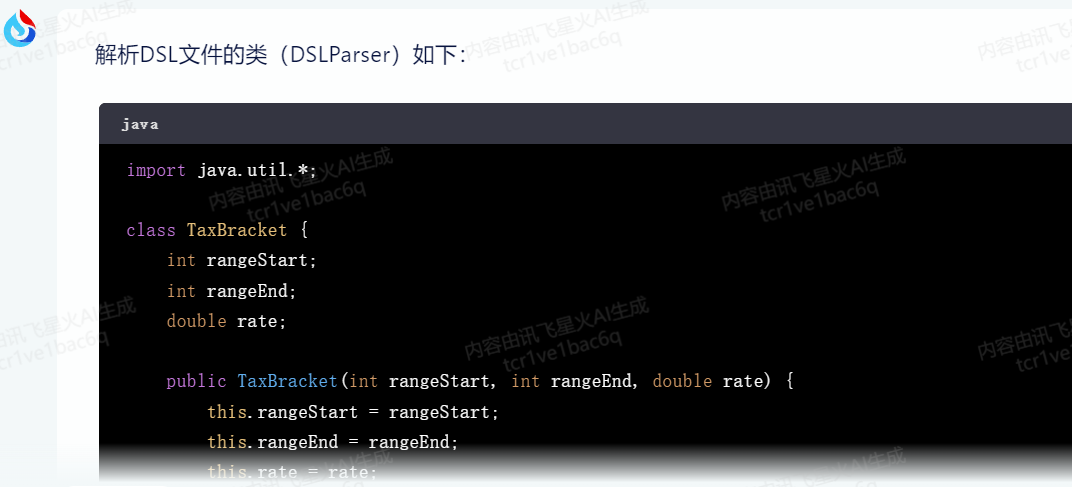
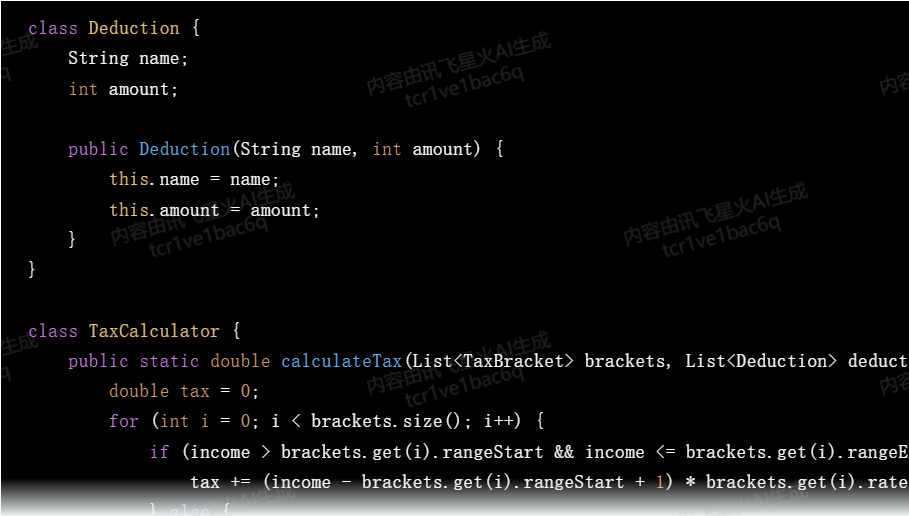
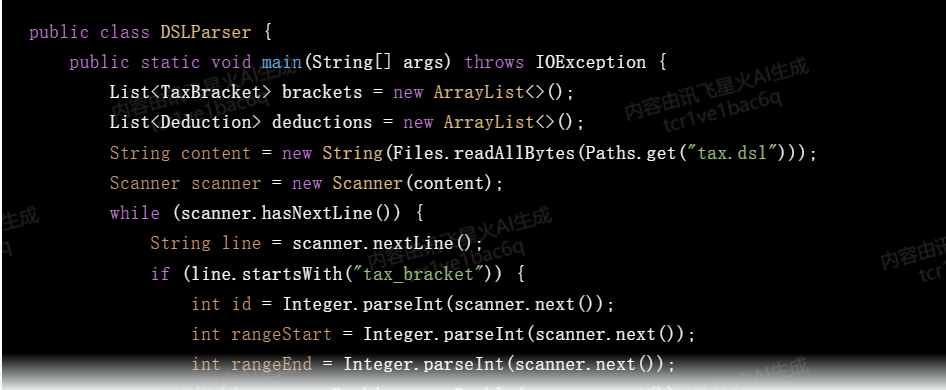
生成的代码中有些小错误,没有考虑一些边界条件,特殊条件,程序员需要能识别出来,然后和它交互,让它修改 —— 这其实也是程序员的重要价值,以后大模型时代,程序员依然是主宰,AI只是我们的好帮手。
作为程序员,除了通过聊天窗口使用大模型之外,肯定还想调用大模型的API,把大模型的能力嵌入到自己的应用当中,这个问题讯飞星火也考虑到了,它的API针对所有【星火注册用户】免费开放,可以直接注册使用,无门槛申请。
个人用户一次性最高可申请400万Tokens,企业用户一次性最高可免费申请1000万Tokens。
上周和一些朋友聊,我发现了一个有趣的现象,有些公司已经大范围普及了基于大模型的编程助手,甚至购买了付费的服务,让大模型成为日常编程工作的一部分,极大地提升了效率。
但是还有一些公司,死守着自己的一亩三分地,就是不愿意尝试,这里边有观念的问题,也有难以搞到账号的问题。
现在讯飞星火面向全民开放,账号的问题已经干掉了,强烈建议大家都去试一试,感受一下大模型生成代码的强大能力,让大模型成为自己编程的好帮手。
扫描我的专属二维码,或者点击阅读原文,可以快速注册体验。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









