






1
1992年9月, 一个周三的下午,贝尔实验室。
Rob Pike (Go语言发明人之一) 正在操作系统Plan 9 上忙碌,这是继Unix之后的一个大工程, 马上就要完工了, 这个时候他突然接到了一个电话。

(年轻帅气的Rob Pike)
电话是IBM的人打来的,他们正在奥斯汀参加X/Open 委员会会议, 想请Rob Pike 和 Ken Thomson (Unix发明人) 对他们设计的一个Unicode编码进行评审。
Rob Pike知道X/Open委员会主要负责制定Unix上的标准规范,以便提高应用程序的在不同Unix变体上的移植性。
很明显,这一次会议的主题是:编码!
Rob Pike想到了自己正在忙活的操作系统Plan 9 , 为了支持全世界的语言如英文、中文、韩文、日文、阿拉伯文...... Plan 9 当然要用Unicode 。

(这货怎么和Go的吉祥物长得如此之像?)
大家都知道Unicode只是规定了每个字符用什么编码,但是没有规定如何去存储, 当时Plan 9 采用了一个叫做ISO 10646 UTF编码, 但是这个编码实在不怎么样, 按照Rob Pike的话说:我们恨这个编码。
Rob 和 Ken 立刻意识到:机会来了 !
Rob :我们有丰富的经验, 为什么不设计一个真正好用的Unicode存储标准呢?
Ken :同意, 我们设计出来,把标准推广的事情交给X/Open委员会。
俩人向IBM的人表达了这个想法, 得到了支持,条件是: 一定要快,快速设计、快速实现。
因为下周一就要投票表决了!
对于天才程序员来说,快速、高质量把活儿搞定就是小菜一碟。
Ken :还记得《老婆离家三周,我开发了一个操作系统吗?》
他们俩慢悠悠地去餐厅吃饭,在吃饭期间,Ken 和 Rob就把基本的方案给设计出来了,这就是大名鼎鼎的UTF-8。
回到贝尔实验室,他们就把想法写成了提纲,发给了X/Open 委员会的人, 委员会的回复是:
这比我们设计的版本好多了,你们什么时候能实现它?
Rob 和Ken 拍着胸脯说:放心吧,下周一肯定能有一个完整的、可以运行的实现。
当天晚上(周三),他们俩就卷起袖子干活, Ken 把packing和unpacking的代码搞定, Rob则去折腾C和图形库相关的东西。
周四,所有的代码都已完成,开始将Plan 9操作系统上的文本文件转成UTF-8
周五,Plan 9 操作系统就已经运行在UTF-8上面了。
实际花费不到三天!
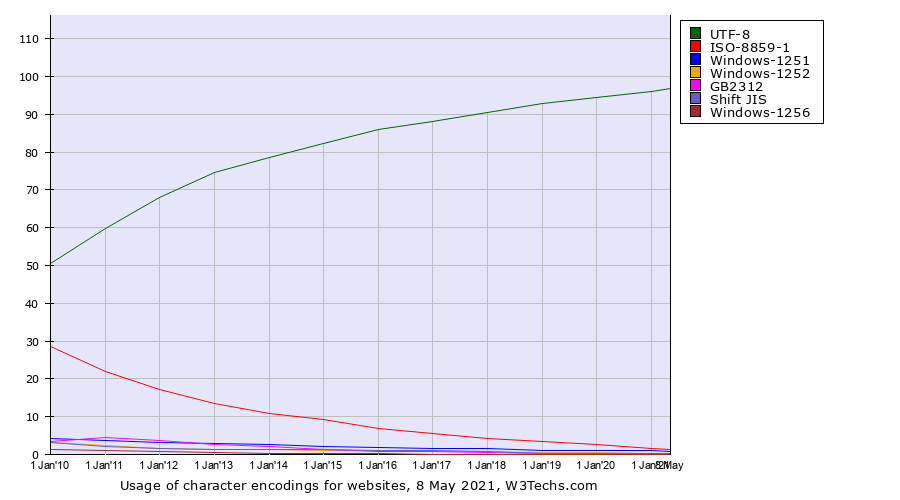
这三天的工作成果最终统治了整个互联网的编码标准, 统计显示, 现在96.8%的Web网站在使用UTF-8。
2
故事讲完了,我们来看看为什么UTF-8能流行起来。
前面说过Unicode只是一个字符集,它规定了每个字符的二进制代码,例如“码” , 对应的Unicode 是7801 , 二进制是
111 1000 0000 0001
需要两个字节来保存, 如果表示其他更大范围的字符,可能需要3个字节或者4个字节,甚至更多。
当计算机面对这两个字节的字节流的时候,就会出现严重的问题:计算机怎么知道这两个字节表示的是一个字符?还是两个字符?
大家知道英文字母用一个字节保存就够了,如果Unicode规定每个英文字符也用两个字节或三个字节来保存,那每个英文字母前面势必要补上0, 文本文件要大两到三倍。
这是巨大的浪费,肯定不行。
Rob和Ken的设计的UTF-8就比较聪明, 看看这个表:
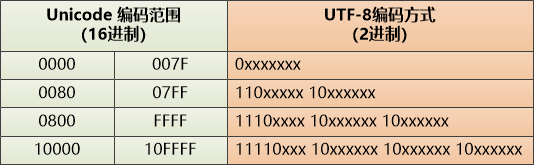
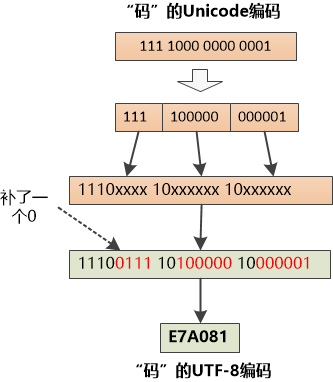
把Unicode 转换成UTF-8,非常简单,比如汉字“码” , Unicode 是7801 , 二进制是 111 1000 0000 0001
7801对应上图的第三行,只要把二进制从右向左填到对应的“模板”中就行,不够的补零
更多的细节就不展开了,关键要看看UTF-8有什么好处。
3
1. 兼容ASCII, 表格中的第一行就是为ASCII所设。
多字节编码的每个字节的最高位永远是 1,而 ASCII 字符编码的最高位是 0,所以从根本上杜绝了编码冲突。
2. 第一个字节就指明了后续的长度
当程序面对一个字节流的时候,只需要读出第一个字节最前面有几个1 ,就知道这个字符的长度,解码很方便。
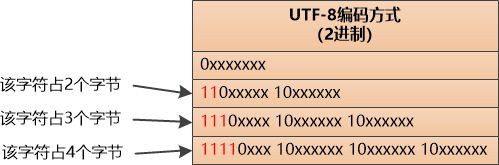
3. 前缀码
大家仔细观察下, UTF-8中没有任何合法字符是其他字符的前缀, 这样就带来了一个好处:支持程序快速地跳过有问题的字节,然后正常解码。
假设有两个中文 “码” 和 “农”, 对应的UTF-8编码为E7A081(码) and E5869C(农)。
但是网络传输丢失了一些数据,变成了 E781 E5869C (即“码”的A0丢失了)
现在程序先读到了E7, 二进制是 1110 0111,它就知道这个字符应该是3字节的, 并且后面的两个字节都应该以10 开头。
于是它就要再读两个字节, 因为A0这个字节丢失了, 程序读到了81 和 E5。
程序就发现:
81 (二进制10000001) 是符合规范的
E5(二进制11100101)的开始两个bit不是10啊, 这应该是另外一个字符的开始。
所以程序就判断出有字符丢失了,可以丢弃刚读到的E7 81 , 然后从E5开始读取, E5 86 9C ,最终显示“农”字。
是不是很巧妙?
全文完,觉得不错的话点个赞或者再看吧!
近期爆文:















 2707
2707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









