







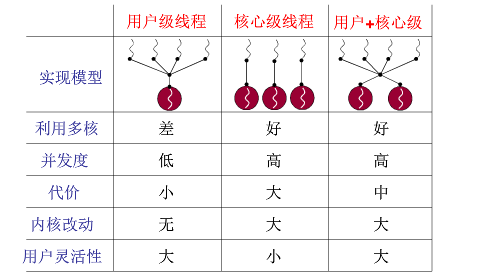
内核级线程与用户级线程的区别
用户级线程的ThreadCreate(),Yield(),是用户程序,不进入内核。
而内核级线程的ThreadCreate()是系统调用,会进入内核,TCB在内核中,内核管理TCB。Yiled()用户不可见,调度点由系统决定,在内核级线程中Yield就不叫Yield了,进入了内核叫Schedule。
内核级线程阻塞后,内核知道这个进程中的其他线程,会切换到其他线程去。所以内核级线程的并发性更好。
而用户级线程阻塞了,那它在的整个进程都会被挂起,直接切到别的进程去执行了。
用户级线程:
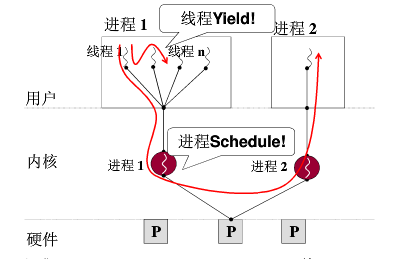
内核级线程:
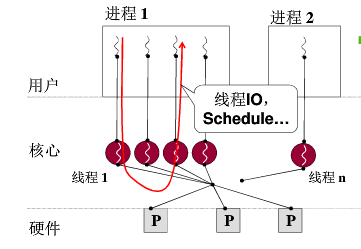
内核级线程
因为进程要分配资源,访问内存,访问文件等等,所以必须要在内核态才能访问控制这些资源,所以进程必须在内核中,切换进程实际是切换资源+切换内核级线程。
内核级线程不仅要在用户态跑,还要在内核态跑,所以在用户态要有用户栈,在内核态要有内核栈。内核级线程需要一套栈。
用户级线程的切换是TCB切,根据TCB切换用户栈;
内核级线程的切换是TCB切,根据TCB切换一套栈,内核栈切,用户栈也要切。
用户栈和内核栈之间的关联
进入内核的唯一方法就是中断(INT中断,时钟中断,键盘鼠标硬件中断…)。
先是在用户态的用户栈里面来回折腾,但是只要一有中断,就启用内核栈,操作系统就通过硬件的一些寄存器找到线程对应的内核栈,找到这个内核栈后就压在用户态执行的栈SS,SP,还要压刚才在用户态执行到什么地方。
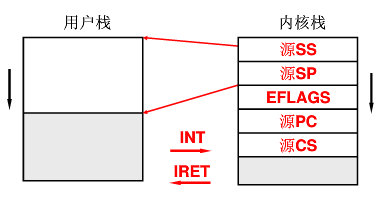
而IRET就是返回,将压入内核栈的5个寄存器弹出,根据弹出的这5个寄存器又可以找到用户栈了。
举例来描述:

read()是个库函数,就会展开成一段int指令。int中断。
中断返回的时候,cs,pc一弹,就又可以找到用户栈和我们在用户态代码执行到哪里。这样就实现了执行指令序列的跳转了。
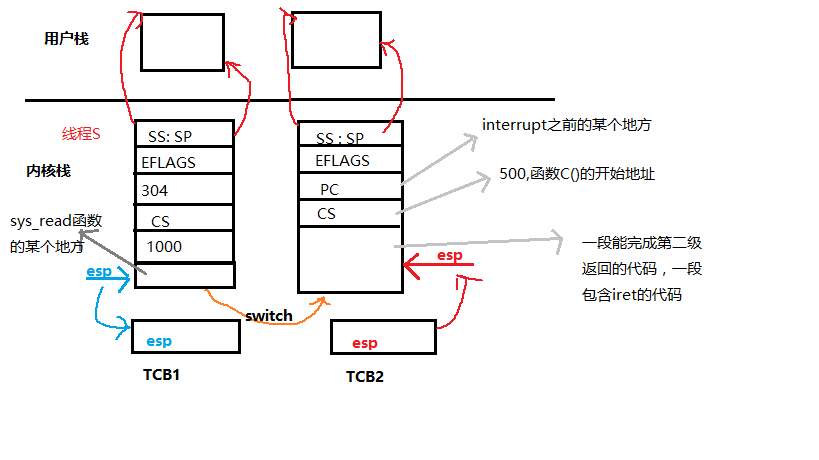
内核级栈的切换
//线程S代码
100: A(){
B();
104:
}
200: B(){
read();
204:
}
300:read(){
int 0x80;
304;
}
system_call:
call sys_read;
1000:
2000:sys_read(){
启动磁盘读;
将自己变成阻塞;
找到next;//下一个线程的TCB
switch_to(cur,next);
//switch_to通过TCB找到内核栈指针,然后通过ret切到某个内核程序
//最后再用CS:PC切到用户程序
}
//线程T代码
500:C(){
....
}
interrupt:
call sys_xxx;
3000:
4000:sys_xxx(){
}
内核线程switch_to的五段论
中断入口:(进入切换)
push ds;
...;
mov ds,内核段号;...
call 中断处理
}//ret
中断处理:(引发切换)
启动磁盘读或时钟中断;
schedule();
}//ret
schedule: next=..;
call switch_to;
}//ret
switch_to:(内核栈切换)
TCB[cur].esp=%esp;
%esp=TCB[next].esp;
ret
中断出口:(第二级切换)
...;
pop ds;
iret
补充(不需要太在意,与本次内容关系不大):
S、T非同一进程:(地址切换)
要首先切换地址映射表;
TCB[cur].ldtr=%ldtr
%ldtr=TCB[next].ldtr内核级线程中的ThreadCreate
void ThreadCreate()
{
TCB tcb=get_free_page();//因为是在内核中,所以分配不是malloc
*krlstack=...; //内核栈
*userstack传入;
填写两个stack;
tcb.esp=krlstack;//关联tcb与内核栈
tcb.状态=就绪;
tcb入队;
}















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









