







一、Redis集合数据类型(set)
Redis 的集合不是一个线性结构,而是一个哈希表结构,它的内部会根据 hash 分子来存储和查找数据,理论上一个集合可以存储 2 的 32 次方减 1 个节点(大约 42 亿)个元素,因为采用哈希表结构,所以对于 Redis 集合的插入、删除和查找的复杂度都是 0(1),只是我们需要注意 3 点。
- 对于集合而言,它的每一个元素都是不能重复的,当插入相同记录的时候都会失败
- 集合是无序的。
- 集合的每一个元素都是 String 数据结构类型。
集合是无序的,并且支持并集、交集和差集的运算
二、Redis有序集合(sorted set)
有序集合和集合类似,只是说它是有序的,和无序集合的主要区别在于每一个元素除了值之外,它还会多一个分数。分数是一个浮点数,在 Java 中是使用双精度表示的,根据分数,Redis 就可以支持对分数从小到大或者从大到小的排序。
这里和无序集合一样,对于每一个元素都是唯一的,但是对于不同元素而言,它的分数可以一样。元素也是 String 数据类型,也是一种基于 hash 的存储结构。
集合是通过哈希表实现的,所以添加、删除、查找的复杂度都是 0(1)。集合中最大的成员数为 2 的 32 次方减 1(40 多亿个成员),有序集合的数据结构如图 1 所示。
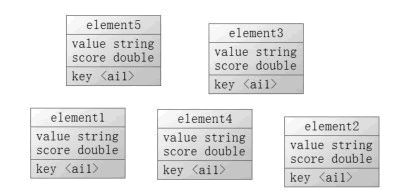
有序集合是依赖 key 标示它是属于哪个集合,依赖分数进行排序,所以值和分数是必须的,而实际上不仅可以对分数进行排序,在满足一定的条件下,也可以对值进行排序。
三、Redis HyperLogLog(基数)
基数是一种算法。举个例子,一本英文著作由数百万个单词组成,你的内存却不足以存储它们,那么我们先分析一下业务。
英文单词本身是有限的,在这本书的几百万个单词中有许许多多重复单词,扣去重复的单词,这本书中也就是几千到一万多个单词而已,那么内存就足够存储它们了。
比如数字集合 {1,2,5,7,9,1,5,9} 的基数集合为 {1,2,5,7,9} 那么基数(不重复元素)就是 5个,基数的作用是评估大约需要准备多少个存储单元去存储数据,但是基数的算法一般会存在一定的误差(一般是可控的)。Redis 对基数数据结构的支持是从版本 2.8.9 开始的。
基数并不是存储元素,存储元素消耗内存空间比较大,而是给某一个有重复元素的数据集合(一般是很大的数据集合)评估需要的空间单元数,所以它没有办法进行存储,加上在工作中用得不多,所以基数就介绍到这儿了。
四、总结
通过前面的文章我们已经了解了Redis的一些基础内容和六种数据结构,日常工作中我们主要使用到的Redis高速的读写速度来优化我们的应用打开速度,利用到的数据结构也是以字符串、哈希为主。后面的文章我们将会讲到一些Redis的高级用法,譬如Redis哨兵、集群、持久化及一些缓存淘汰策略模式、发布订阅等等。爱学的你们要持续关注该Redis专题哦~~















 1598
1598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









