







目录
元字段
每个文档都有与之关联的元数据,元字段是为了保证系统正常运转的内置字段,比如_index表示索引字段,_type表示映射类型字段和_id表示文档主键字段,这些字段都是以下划线开头的。当映射类型被创建的时候,可以自定义一些元字段的行为,例如标识元字段、文档来源元字段、索引元字段、路由元字段等。
标识元字段:
| 参数 | 说明 |
|---|---|
| _index | 文档所属的索引 |
| _uid | 包含_type和_id的混合字段 |
| _type | 文档的映射类型 |
| _id | 文档的ID |
文档元字段:
| 参数 | 说明 |
|---|---|
| _source | 作为文档内容的原始JSON |
| _size | _source元字段占用的字节数,通过mapper-size插件提供 |
索引元字段:
| 参数 | 说明 |
|---|---|
| _all | 索引所有字段的值 |
| _field_names | 文档中包含非空值的字段 |
| _timestamp | 关联文章的时间戳,可以手动指定或者自动生成 |
| _ttl | 定义文档被自动删除之前的存活时间 |
路由元字段:
| 参数 | 说明 |
|---|---|
| _parent | 用于映射类型之间创建父子关系 |
| _routing | 一个自定义的路由值,路由文档到一个特定的分片 |
其他元字段:
| 参数 | 说明 |
|---|---|
| _meta | 应用特定的元字段 |
1、_all
_all字段是一个特殊的包含全部内容的字段,在一个大字符串中关联所有其他字段的值,使用空格作为分隔符。可以被分析和索引但不会被存储。使用_all字段可以对文档的值
进行搜索而不必知道包含所需值的字段名。当面对一个新的数据集的时候,_all字段是非常有用的选项。
利用_all字段进行搜索:
PUT /test/secilog/1
{
"first_name": "John",
"last_name": "Smith",
"date_of_birth": "1970-10-24"
}
GET /test/_search
{
"query": {
"match": {
"_all": "john smith 1970"
}
}
}
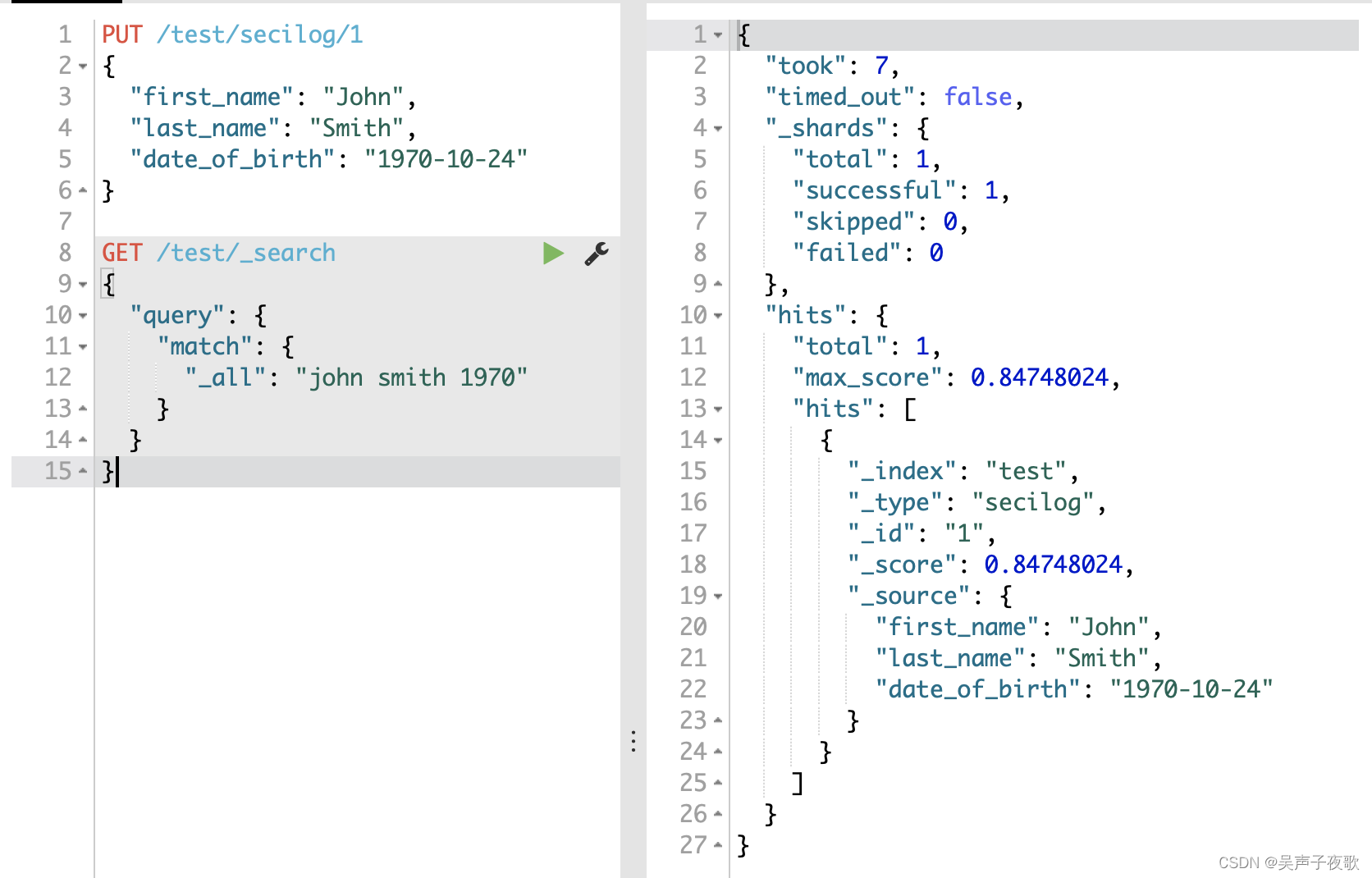
al1字段包含的索引词:[“john”,“smith”,“1970”,“10”,“24”]
date_of_birth字段作为日期型字段,会索引一个索引词190-10-24 00:00:00UTC。但是,_all字段将所有的值作为字符串,所以日期值作为三个字符串被索引:"1970”,
“10”,“24”。
_all字段就是一个字符串类型字段,接受与字符串型字段相同的参数,包括analyzer,index_options和store。
_all字段关联字段值的时候,丢失了短字段(高相关性)和长字段(低相关性)之间的区别。当相关性是重要搜索条件的时候,应该明确指出查询字段。
_all字段的使用需要额外的处理器周期,并且耗费更多的磁盘空间。如果不需要的话,可以完全禁用或者在每个字段的基础上自定义。
2、_field_name
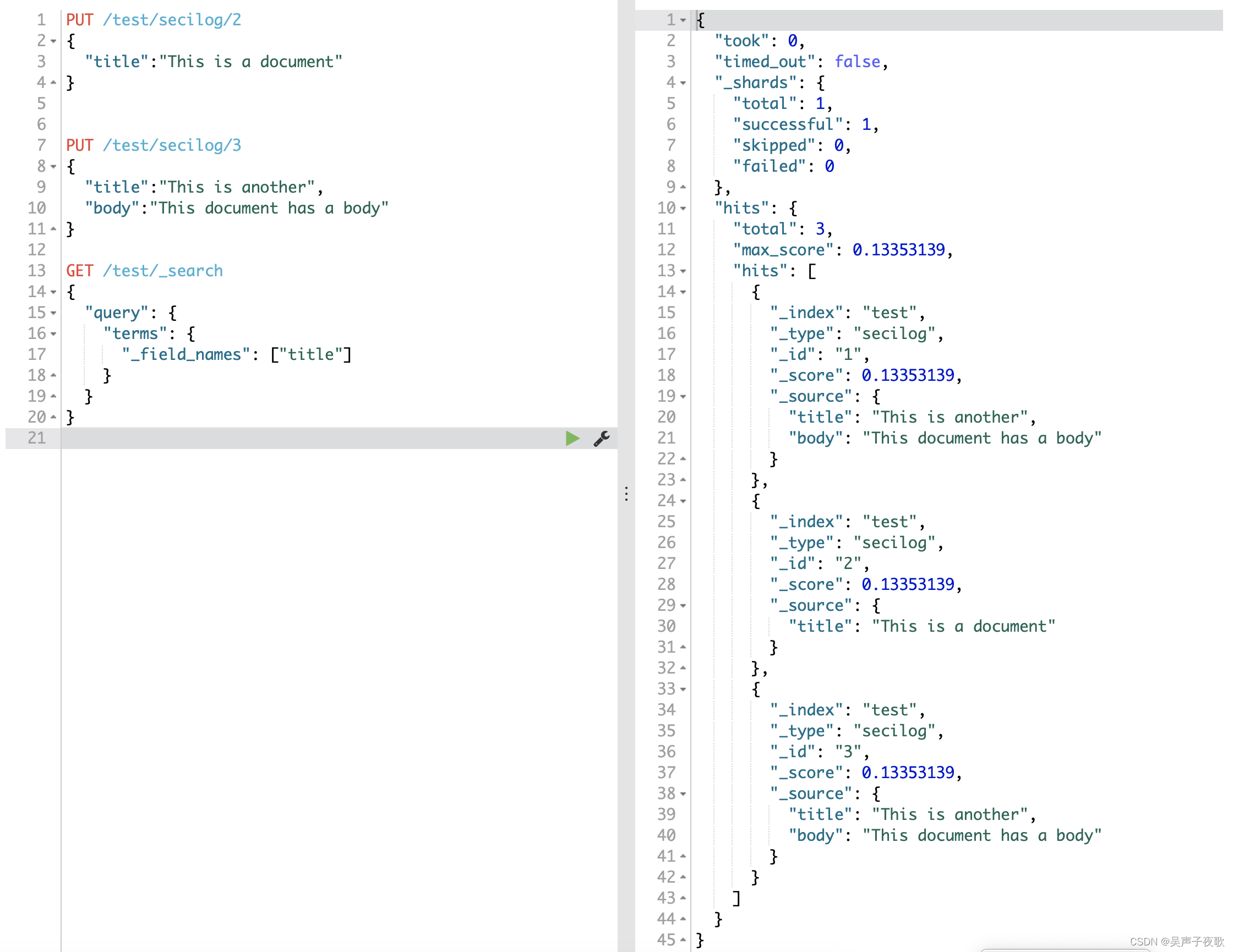
_field_names字段索引文档中所有包含非空值的字段名称。_field_nams字段用于存在查询和缺失查询的情况下,查找指定字段拥有非空值的文档是否存在。
PUT /test/secilog/2
{
"title":"This is a document"
}
PUT /test/secilog/3
{
"title":"This is another",
"body":"This document has a body"
}
GET /test/_search
{
"query": {
"terms": {
"_field_names": ["title"]
}
}
}
3、_id
每个被索引的文档都关联一个_type字段和一个_id字段。_id字段没有索引,它的值可以哦那个_uid字段自动生成。
_id字段的值可以在查询以及脚本中访问,但是在聚合或者排序的时候,要使用_uid字段而不用_id字段。
GET /test/_search
{
"query": {
"terms": {
"_id": ["1", "2"]
}
}
}
4、_index
在多个索引中执行查询的时候,有时需要添加查询子句来关联特定的索引文档。_index字段可以匹配包含某个文档的索引。在term或terms查询、聚合、脚本以及排序的时候,可以访问index字段的值。
index是一个虚拟字段,不作为一个真实的字段添加到Lucene索引中。这意味着可以在term或terms查询(或任何重写term查询的查询,比如match、query.string或者simple_query_.string查询)中使用_index字段,但是不支持prefix、wildcard、regexp或fuzzy查询。
GET /index_1,index_2/_search
{
"query": {
"terms": {
"_index": ["index_1", "index_2"]
}
},
"aggs": {
"indices": {
"terms": {"field": "_index", "size": 10}
}
},
"sort": [{
"_index": {"order": "asc"}
}],
"script_fields": {
"index_name": {
"script": "doc['_index']"
}
}
}
5、_meta
每个映射类型都可以拥有自定义的元数据。这些元数据对Elasticsearch来说毫无用处,但是可以用来存储应用程序的特定元数据:
PUT /test
{
"mappings": {
"user": {
"_meta": {
"class": "MyApp::User",
"version": {"min": "1.0", "max": "1.3"}
}
}
}
}
6、_parent
在同一个索引中通过创建映射类型可以在文档间建立父子关系。
创建映射:
PUT /ps
{
"mappings": {
"my_parent": {},
"my_child": {
"_parent": {"type": "my_parent"}
}
}
}
插入父文档:
PUT /ps/my_parent/1
{
"text": "This is a parent document"
}
插入子文档,并指出父文档:
PUT /ps/my_child/2?parent=1
{
"text":"This is a child document"
}
PUT /ps/my_child/3?parent=1
{
"text":"This is another child document"
}
6.1、父子限制
父类型和子类型必须是不同的,即父子关系不能建立在相同类型的文档之间。
_parent的type设置只能指向一个当前不存在的类型。这意味着一个类型被创建之后就无法成为父类型。
父子文档必须索引在相同的分片上。parent编号用于作为子文档的路由值,确保子文档被索引到父文档所在的分片中。这意味着当获取、删除或更新子文档的时候,需要提供相同的parent值。
6.2、整体序数
使用整体序数可以加快建立父子关系。分片发生任何改变之后,整体序数都需要进行重建。分片中存储的父编码值越多,为parent字段重建整体序数所花的时间就越长。
整体序数在默认情况下属于懒创建:刷新之后的第一次父子查询或聚合会触发整体序数的创建,这可能会给用户的使用引入一个明显的延迟。可以使用参数将整体序数的创建时间由查询触发改到刷新触发:
PUT /ps
{
"mappings": {
"my_parent": {},
"my_child": {
"_parent": {
"type": "my_parent",
"fielddata": {"loading": "eager_global_ordinals"}
}
}
}
}
7、_routing
文档在索引中利用下面的公式路由到特定的分片:
shard_num = hash(_routing) % num_primary_shards
_routing字段的默认值使用的是文档的_id字段。如果存在父文档,则使用文档的_parent编号。
可以通过为每个文档指定一个自定义的路由值来实现自定义的路由方式:
PUT /test/secilog/5?routing=user5
{
"title": "This is a document"
}
这个问昂使用user5作为路由值,而不是它的ID,在获取、删除和更新文档的时候需要提供相同的路由值。
_routing字段可以在查询、聚合、脚本以及排序的时候访问:
GET /test/_search
{
"query": {
"terms": {"_routing": ["user1"]}
},
"aggs": {
"Routing values": {
"terms": {"field": "_routing", "size": 10}
}
},
"sort": [
{
"_routing": {"order": "desc"}
}
],
"script_fields": {
"Routing value": {"script": "doc['_routing']"}
}
}
7.1、利用自定义路由进行搜索
自定义路由可以降低搜索压力。搜索请求可以仅仅发送到匹配指定路由值的分片而不是广播到所有分片:
GET /test/_search?routing=user1,suer2
{
"query": {
"match": {
"title": "document"
}
}
}
搜索请求仅在关联路由值user1和user2的分片上执行。
7.2、使路由值成为必选项
使用自定义路由索引、获取、删除或更新文档时,提供路由值是很重要的。忘记路由值会导致文档被一个以上的分片索引。作为保障,routing字段可以被设置,应使自定义路由值成为所有CRUD操作的必选项:
PUT /test
{
"mappings": {
"secilog": {
"_routing": {"required": true}
}
}
}
7.3、自定义路由下的唯一编码
当索引指定了自定义路由的文档时,不能保障所有分片中文档Id的唯一性。事实上,拥有相同Id的文档会根据不同的路由存储在不同的分片中,只能依靠用户来确保编码的唯一性。
8、_source
_source字段包含索引时原始的JSON文档内容,字段本身不建立索引(因此无法搜索)但是会被存储,所以当执行获取请求的时候可以返回source字段。虽然很方便,但是
source字段确实会对索引产生存储开销。因此,可以禁用_source字段:
PUT /secisland
{
"mappings": {
"secilog": {
"_source": {"enabled": false}
}
}
}
如果磁盘空间是个问题,可以提高压缩等级来实现节约存储空间。可以用包含/排除字段的特性在保存之前减少_source字段的内容。
如果source字段被禁用,会造成大量的功能无法使用:
- 更新接口。
- 高亮显示功能。
- 重建索引的功能,不论是修改映射或分析,还是升级索引到一个新版本。
- 通过查看索引时的原始文档对查询或聚合进行调试的功能。
- 自动修复索引的功能。
- 从source字段中移除内容相当于精简版的禁用功能,尤其是无法重建文档索引。
includes/excludes参数(可以使用通配符):
PUT /secisland
{
"mappings": {
"event": {
"includes": ["*.count", "meta.*"],
"excludes": ["meta.description", "meta.other.*"]
}
}
}
移除的字段不会被存储在_source字段中,但我们仍然可以搜索这些字段。
9、_type
每个索引的文档都包含_type和_id字段,索引_type字段的目的是通过类型名加快搜索进度。
_type字段的值可以在查询、聚合、脚本以及排序时访问:
GET /test/_search
{
"query":{
"terms": {
"_type": ["type_1", "type_2"]
}
},
"aggs": {
"types": {
"terms": {"field": "_type", "size": 10}
}
},
"sort": [
{"_type": {"order": "desc"}}
],
"script_fields": {
"type": {
"script": "doc['_type']"
}
}
}
返回:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": null,
"hits": [
{
"_index": "test",
"_type": "type_2",
"_id": "2",
"_score": null,
"fields": {
"type": [
"type_2"
]
},
"sort": [
"type_2"
]
},
{
"_index": "test",
"_type": "type_1",
"_id": "1",
"_score": null,
"fields": {
"type": [
"type_1"
]
},
"sort": [
"type_1"
]
}
]
},
"aggregations": {
"types": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "type_1",
"doc_count": 1
},
{
"key": "type_2",
"doc_count": 1
}
]
}
}
}
10、_uid
每个索引的文档都包含_type和_id字段,这两个值结合为{type}#{id}并且作为_uid字段被索引。
_uid字段的值可以在查询、聚合、脚本以及排序时访问:
GET /test/_search
{
"query": {
"terms": {
"_uid": ["u#1", "u#2"]
}
},
"aggs": {
"UIDs": {
"terms": {"field":"_uid", "size": 10}
}
},
"sort": [
{"_uid":{"order":"desc"}}
],
"script_fields": {
"UID": {
"script": "doc['_uid']"
}
}
}
返回:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": null,
"hits": [
{
"_index": "test",
"_type": "u",
"_id": "2",
"_score": null,
"fields": {
"UID": [
"u#2"
]
},
"sort": [
"u#2"
]
},
{
"_index": "test",
"_type": "u",
"_id": "1",
"_score": null,
"fields": {
"UID": [
"u#1"
]
},
"sort": [
"u#1"
]
}
]
},
"aggregations": {
"UIDs": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "u#1",
"doc_count": 1
},
{
"key": "u#2",
"doc_count": 1
}
]
}
}
}















 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









