







目录
滑动窗口的卷积实现(Convolutional implementation of sliding windows)
Bounding Box预测(Bounding box predictions)
候选区域(选修)(Region proposals (Optional))-R-CNN算法
目标定位(Object localization)
定义
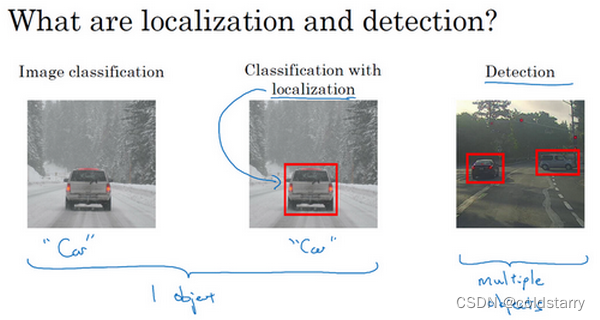
图片分类任务:判断其中的对象是不是汽车
定位分类:在图片中标记出它的位置,用边框或红色方框把汽车圈起来,这就是定位分类问题。其中“定位”的意思是判断汽车在图片中的具体位置。
通常只有一个较大的对象位于图片中间位置,我们要对它进行识别和定位。而在对象检测问题中,图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。因此,图片分类的思路可以帮助学习分类定位,而对象定位的思路又有助于学习对象检测
图片分类的例子:输入一张图片到多层卷积神经网络。这就是卷积神经网络,它会输出一个特征向量,并反馈给softmax单元来预测图片类型。
原理图
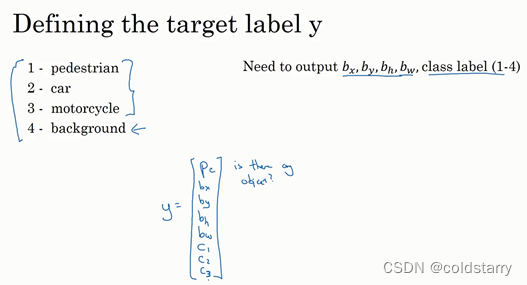
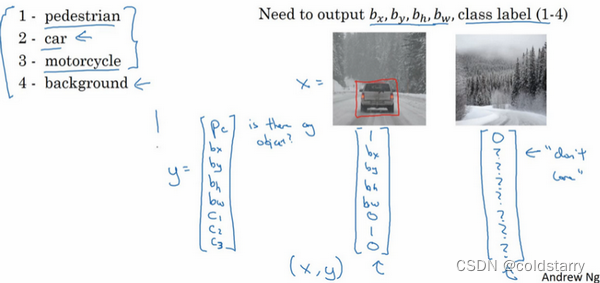
如果你正在构建汽车自动驾驶系统,那么对象可能包括以下几类:行人、汽车、摩托车和背景,这意味着图片中不含有前三种对象,也就是说图片中没有行人、汽车和摩托车,输出结果会是背景对象,这四个分类就是softmax函数可能输出的结果。
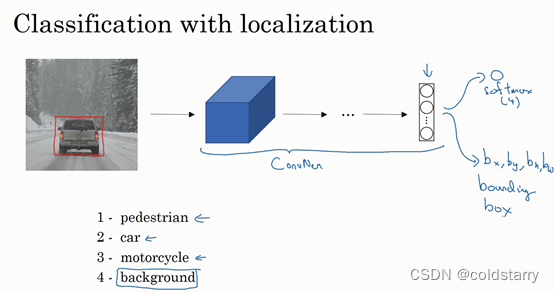
具体做法:
输出向量
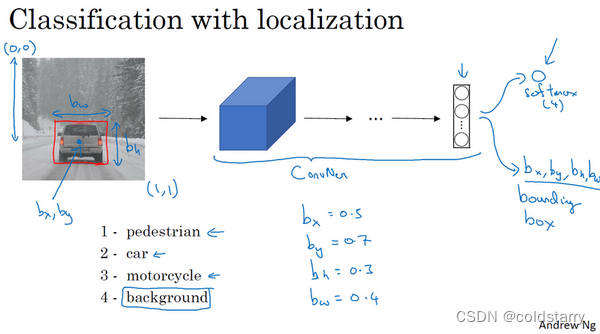
我们可以让神经网络多输出几个单元,输出一个边界框。具体说就是让神经网络再多输出4个数字,标记bx,by,bh,bw,这四个数字是被检测对象的边界框的参数化表示。


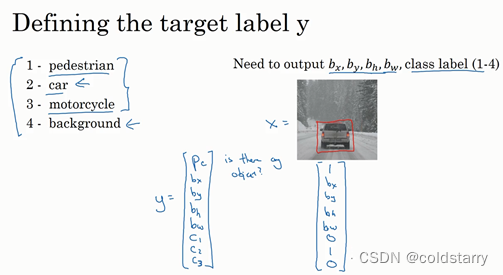
图片中没有检测对象的样例


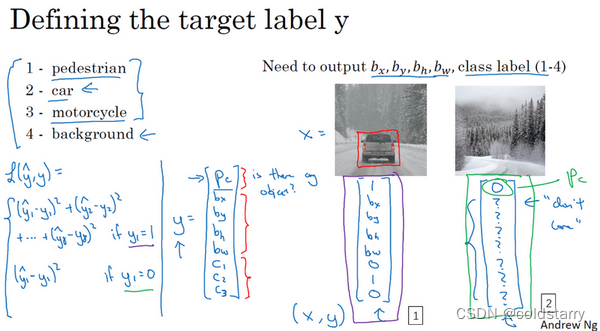
损失函数

 特征点检测(Landmark detection)
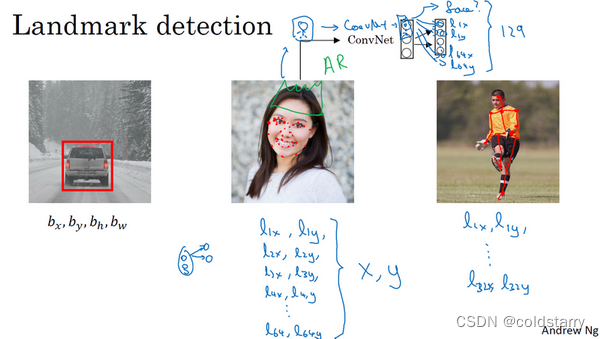
特征点检测(Landmark detection)
定义:


也许除了这四个特征点,你还想得到更多的特征点输出值,这些(图中眼眶上的红色特征点)都是眼睛的特征点,你还可以根据嘴部的关键点输出值来确定嘴的形状,从而判断人物是在微笑还是皱眉,也可以提取鼻子周围的关键特征点。为了便于说明,你可以设定特征点的个数,假设脸部有64个特征点,有些点甚至可以帮助你定义脸部轮廓或下颌轮廓。选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置。
具体做法:

目标检测(Object detection)
学过了对象定位和特征点检测,今天我们来构建一个对象检测算法。这节课,我们将学习如何通过卷积网络进行对象检测,采用的是基于滑动窗口的目标检测算法。


滑动窗口目标检测

假设这是一张测试图片,首先选定一个特定大小的窗口,比如图片下方这个窗口,将这个红色小方块输入卷积神经网络,卷积网络开始进行预测,即判断红色方框内有没有汽车。

滑动窗口目标检测算法接下来会继续处理第二个图像,即红色方框稍向右滑动之后的区域,并输入给卷积网络,因此输入给卷积网络的只有红色方框内的区域,再次运行卷积网络,然后处理第三个图像,依次重复操作,直到这个窗口滑过图像的每一个角落。
为了滑动得更快,我这里选用的步幅比较大,思路是以固定步幅移动窗口,遍历图像的每个区域,把这些剪切后的小图像输入卷积网络,对每个位置按0或1进行分类,这就是所谓的图像滑动窗口操作。

重复上述操作,不过这次我们选择一个更大的窗口,截取更大的区域,并输入给卷积神经网络处理,你可以根据卷积网络对输入大小调整这个区域,然后输入给卷积网络,输出0或1。

再以某个固定步幅滑动窗口,重复以上操作,遍历整个图像,输出结果。
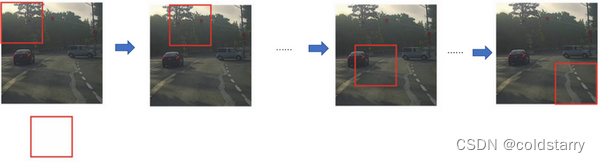
然后第三次重复操作,这次选用更大的窗口。
如果你这样做,不论汽车在图片的什么位置,总有一个窗口可以检测到它。
 </
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









