









本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:新一代LMM基线发布 | 早期自回归融合+预训练先验驱动,性能直追组合模型,训练资源大幅精简!

导读
近年来,大语言模型(LLMs)的进展显著推动了大型多模态模型(LMMs)的发展,突显了通用和智能助手的潜力。然而,大多数LMMs分别对视觉和文本模态进行建模,导致近期努力开发使用单个transformer的局部LMM。尽管前景看好,但这些局部模型资源密集,通常与它们的组合对应模型相比存在性能差距。
为了缓解这一问题,作者提出了一种简单而有效的方法,在单个transformer中构建局部和端到端大型多模态模型的 Baseline 。首先,作者提出了一种新的早期融合LMM,能够在早期融合多模态输入并以自回归方式响应视觉指令。其次,作者为所提出的模型设计了一种高效的训练方案,利用预训练模型的先验知识,解决性能限制和资源消耗的挑战。所提出的模型在性能上优于使用单个transformer的其他LMMs,并且显著缩小了与组合LMMs的性能差距。
1. 引言
大语言模型(LLMs)近年来在人工智能领域取得了显著进展。这一进展极大地加速了大型多模态模型(LMMs)的发展,这些模型包括专有商业模型和开源模型。这些模型促进了复杂的视觉-语言对话和交互。大多数开源模型利用一个或多个独立的视觉组件来建模视觉模态,从而为LLMs配备了视觉理解和推理能力。例如,LLaVA系列直接利用预训练的CLIP视觉编码器提取High-Level视觉嵌入,并使用Projector将这些嵌入与LLMs连接。
由于语言是人类生成的抽象信号,由词嵌入层产生的文本嵌入包含语义信息且属于高 Level 。因此,将文本嵌入与预训练视觉编码器产生的视觉嵌入相结合是合理的,因为这两种嵌入都是语义性的。然而,现成的视觉编码器倾向于产生高度压缩的全局语义并忽略细粒度的视觉信息。因此,它可能无法提取文本所需的视觉线索,导致LMMs在处理细粒度任务时遇到困难。
为解决这一问题,作者提出了一种名为HaploVL的早期融合线性混合模型。HaploVL在早期阶段融合视觉和文本嵌入,使文本嵌入能够自主获取必要的视觉线索。具体来说,HaploVL使用一个轻量级的 Patch 嵌入层和一个单层线性层来嵌入视觉输入,并使用文本嵌入层来处理文本输入。随后,Transformer主干网络根据文本输入提取必要的视觉信息,并基于融合后的表示生成语言响应。
近期的一些研究也属于早期融合LMMs的范畴,并致力于开发具有简洁推理过程的统一多模态Transformer。例如,Fuyu直接使用一个简单的线性层而不是视觉编码器来嵌入输入图像,并将混合模态序列留给后续的Transformer处理。EVE旨在通过从固定的视觉编码器中提取来复制Fuyu,从而减少训练数据。然而,它强制在大语言模型(7B)和小ViT(300M)之间进行对齐,而不允许LMM从High-Level视觉特征中学习。因此,尽管使用了3500万训练数据,它在视觉-语言基准测试中与组合LMMs之间仍然存在显著的性能差距。
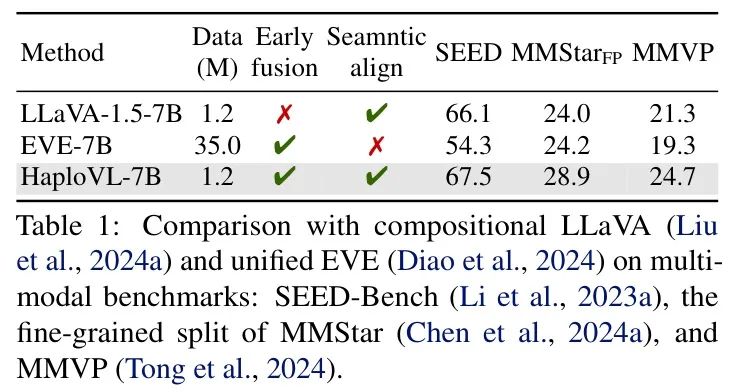
为此,HaploVL利用预解码器根据文本信息自主获取必要的视觉线索,并使用后解码器进一步处理提取的High-Level多模态嵌入。由于从头开始训练此类模型成本非常高,例如,预训练Chameleon30B所需的能量消耗相当于为一辆特斯拉Model 3提供动力绕赤道行驶约225次1,因此作者提出利用从预训练模型中获取的先验知识。这是因为预训练模型通过在大量数据上训练获得了广泛的知识,例如,CLIP视觉编码器通过观察数十亿张图像获得了基于视觉的知识,而Llama通过观察万亿个文本 Token 获得了基于文本的知识。具体来说,预解码器从视觉编码器继承了先验视觉知识,同时处理文本和视觉模态以执行模态扩展。此外,LLM保留了其先验文本知识,并学习将视觉嵌入作为条件。通过这种方式,与早期融合和单 Transformer LMM相比,作者显著减少了所需的数据和训练成本,并缩小了统一和组合LMM之间的性能差距。如表1所示,HaploVL在细粒度感知基准测试上相对于LLaVA和EVE实现了显著的性能提升。这表明开发具有单个 Transformer 的多模态模型具有广阔的潜力。
作者的贡献可以总结如下:
-
• 作者开发了一种新的早期融合LMM,该模型使用单个transformer在早期阶段获取必要的视觉线索,并基于融合的多模态嵌入生成语言响应。
-
• 作者为提出的模型设计了一种高效的训练方案,该方案利用了预训练模型中的先验知识。这种方法不仅减少了大规模数据和计算资源的需求,而且缩小了统一和组合型LMM之间的性能差距。
2. 相关工作
编码器-解码器大型多模态模型,如LLaVA所示,使用预训练的视觉编码器提取视觉嵌入,并通过MLP层将视觉嵌入与大语言模型(LLM)对齐。然后,这些具有“编码器-MLP-LLM”配置的模型在定制指令数据上进行微调,以获得图像理解和推理的能力。许多创新通过利用更强大的视觉编码器、扩展输入大小到任意分辨率以及合成高质量数据来提高该方法的表现。同时,受这种简单架构的启发,许多研究用领域特定编码器替换视觉编码器,以开发特定模态的多模态模型。此外,其他人将多个特定模态编码器与语言模型集成,使其能够适应更多附加模态。然而,这种方法的一个重大局限性是视觉序列的长度。为了缓解这个问题,BLIP-2开发了一个Q-former,用固定数量的可学习 Query 替换了长视觉特征。这种“编码器Q-former-LLM”配置已被许多研究复制。
单 Transformer 多模态模型旨在摒弃视觉编码器,仅允许语言模型处理未完全压缩的文本嵌入和视觉嵌入。Fuyu使用线性 Projector 将原始图像patchify,其中获得的Low-Level视觉patch嵌入被视为连续的 Token 。与具有“编码器-MLPLLM”配置的模型相比,Fuyu直接将Low-Level视觉嵌入与文本嵌入融合,而不是High-Level视觉嵌入(视觉编码器的隐藏状态)。此外,Chameleon采用VQ码本将图像离散化为一系列离散的视觉 Token ,类似于文本分词的过程。因此,视觉和文本嵌入可以从中提取相同的嵌入层,并由仅解码器的transformer进行处理。Emu3将这种简化的 Pipeline 扩展到生成高质量的图像和视频。由于这些方法是从头开始训练的,它们消耗了大量的计算资源,并需要大量的数据。为了将现成的仅解码器语言模型适应到多模态模型,EVE引入了一个精心设计的patch嵌入层和训练策略。然而,尽管使用了35M张图像,它们与编码器-解码器多模态语言模型相比,仍然存在显著的性能差距。
3. 方法
HaploVL是一个单 Transformer 多模态模型。类似于流行的LMM,它将视觉和文本输入映射到相同的潜在空间,并以自回归的方式将它们作为文本生成的条件。与总是依赖于固定视觉编码器的高度压缩视觉嵌入的其他LMM不同,HaploVL在早期阶段融合了视觉和文本输入,并根据文本输入提取必要的视觉信息。与之前的早期融合和单 Transformer LMM相比,HaploVL在训练方面更加高效,因为它吸收了模型学习到的先验知识。在下一节中,作者首先详细介绍HaploVL的架构,然后介绍高效的训练过程。
3.1 架构
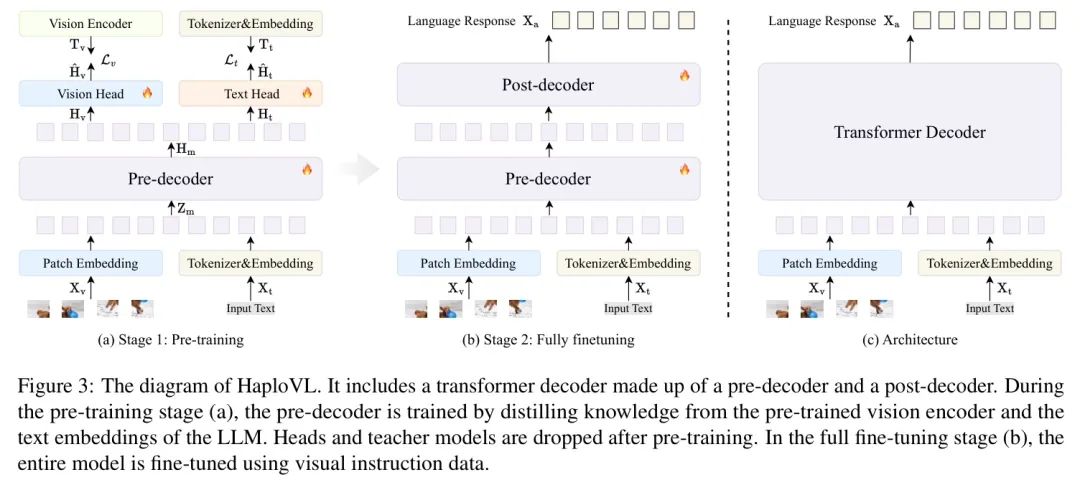


3.2 训练
作者为HaploVL采用了两阶段训练方案,如图3所示。在第一阶段,通过特征蒸馏对预解码器进行训练。这使得它能够有效地同时处理视觉和文本输入,为后续阶段奠定基础。在第二阶段,模型被训练以遵循视觉指令,这相当于LLaVA的视觉指令微调。


第二阶段:全面微调。这一训练阶段主要针对多模态学习。如图3(b)所示,作者在这一阶段对HaploVL的所有组件进行微调。仍然采用下一 Token 预测损失来最大化方程(1)的对数似然。微调后,HaploVL在以下人类视觉指令方面表现出能力。
4. 实验
在本节中,作者首先概述了实验设置,包括训练设置和数据集。然后,作者将HaploVL与领先方法在各种基准上进行比较。最后,本节结尾给出了训练过程分析和一些定性结果。
4.1 实验设置

数据集。数据主要来自LLaVA、MMC4、海豚、CC3M,以及COCO。此外,HaploVL在广泛采用的基于图像的基准测试中进行了评估,包括GQA、VQAv2、ScienceQA-IMG(SQA)、AI2D、MMBenchEN-dev(MMB)、MMMU、RealWorldQA、MMStar(MMS)、POPE、SEED-Bench-IMG(SEED)和MMVP。
在这些基准中,MMVP主要关注细粒度感知。更多细节请见附录。
4.2 主要结果
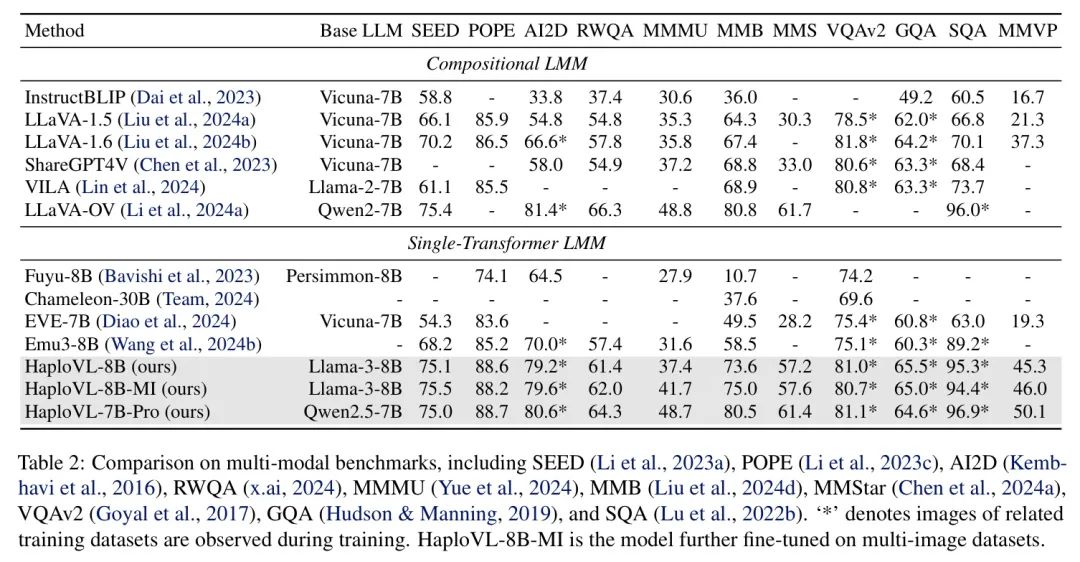
作者将HaploVL与现有的多模态模型进行了比较,包括单独的模型和具有单个transformer的统一模型,如表2所示。值得注意的是,HaploVL在性能上优于其他统一模型。具体来说,作者在MMBench上比Emu3提高了15.1%,在MMMU上提高了5.5%。此外,HaploVL在MMBench上比使用预训练权重的模型EVE领先24.1%,在SEED-Bench上领先20.8%。这些结果展示了HaploVL在多模态能力方面的巨大潜力。此外,作者还与单独的模型进行了比较,发现HaploVL在性能上显著优于之前的单独模型。然而,作者的性能仍然落后于最先进的单独开源模型LLaVA-One Vision。作者将其归因于输入分辨率和上下文长度。LLaVAOneVision使用7290个token来表示一个输入图像,而HaploVL只使用最多2304个token。由于计算资源限制,作者只能将上下文长度设置为6144,这在一定程度上影响了模型的有效性。尽管如此,HaploVL-7B-Pro的性能几乎与LLaVAOne Vision相当。此外,作者为单模态transformer实现了一个简单高效的 Baseline ,它使用更少的资源就优于其他原生LMMs。作者期望在这个基础上进一步改进此类模型的表现。
4.3 消融研究
针对不同的LLM、分辨率和视觉指令数据进行的消融实验。如表4所示,通过提升语言模型、输入分辨率和指令数据,作者实现了性能的提升。具体而言,采用更先进的语言模型(Llama-3)使得平均性能提升了2.5%。这表明多模态理解能力与语言模型的能力相关。将分辨率从336×336提升到672×672,使用相同的665K数据集,平均性能提升了3.3%,特别是在POPE上实现了3.7%的显著提升。这强调了允许LMM感知更精细的视觉细节的重要性。当在672×672分辨率下扩展视觉指令数据时,由于LMM的知识得到丰富,平均性能提升了6.6%。这些提升在MMStar和MMVP等基准测试中尤为明显,表明在扩展LMM的视觉知识后,可以增强细粒度感知能力。然而,在GQA上观察到轻微的性能下降。
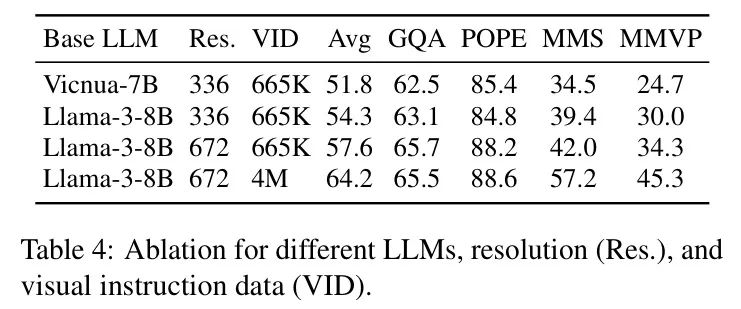
这种差异可能源于4M指令数据与GQA数据集在分布上的差异。
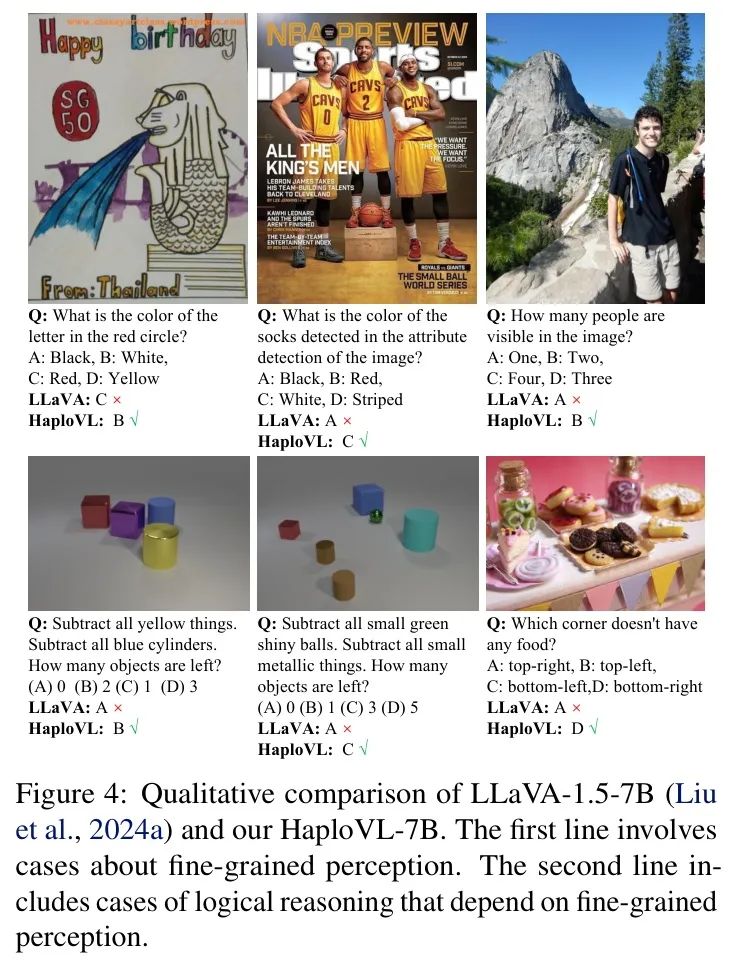
与使用相同LLM和训练数据的组成式LMM相比。作者使用相同的LLM(Vicuna-7B)和指令数据(665K)将HaploVL与典型的组成式LMM LLaVA-1.5-7B的性能进行了比较。由于LLM和指令数据主要影响不同基准测试上的性能,作者限制了数据以确保HaploVL与LLaVA-1.5-7B之间的比较是公平的。这使得作者能够验证使用单个transformer的LMM是否比单独的模型具有优势。如表5所示,在MMVP基准测试上,HaploVL相对于LLaVA-1.5-7B和EVE-7B分别获得了3.4%和5.4%的提升;在MMStar基准测试上,HaploVL分别比LLaVA-1.5-7B和EVE-7B高出4.2%和6.3%。作者进一步分析了MMStar的详细得分,包括粗感知(CP)、细粒度感知(FP)、实例推理(IR)、逻辑推理(LR)、科学技术(ST)和数学(MA)。值得注意的是,HaploVL-7B模型在细粒度感知上比LLaVA-1.5-7B提高了4.9%,在逻辑推理上提高了9.6%。这表明在单个transformer中将原始图像和文本嵌入融合是有益的,从而增强了基于图像的逻辑推理。相比之下,使用来自CLIP-ViT编码器的High-Level语义嵌入的单独模型可能会模糊细粒度图像信息,从而损害模型执行依赖于图像细节的任务的能力。这与先前的研究一致。
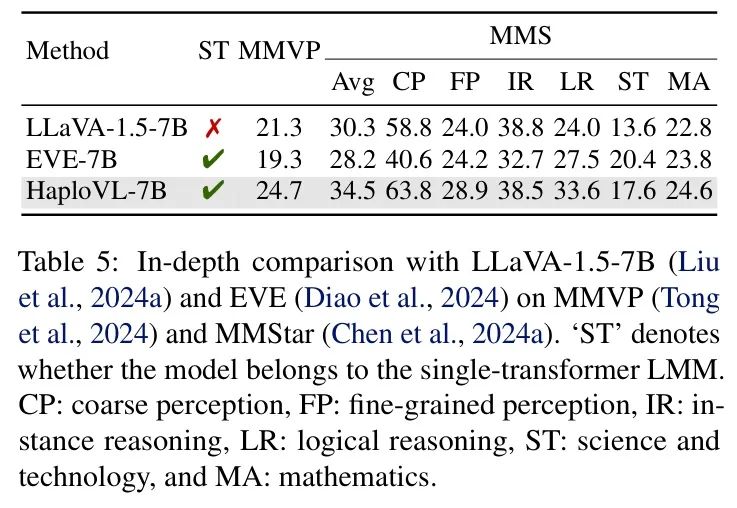
为进一步说明细粒度感知与逻辑推理之间的差异,作者在图4中提供了定性结果。第一行展示了细粒度感知的案例,其中LLaVA-1.5-7B未能识别图像中心外的物体颜色和物体数量。例如,LLaVA-1.5-7B错误地识别了NBA球员的袜子颜色。第二行展示了逻辑推理的例子,由于缺乏细粒度感知能力,LLaVA-1.5-7B在依赖该能力的任务上失败,例如边缘物体感知和推理,以及图像中的区域突出。相比之下,HaploVL在块嵌入层之后融合原始图像嵌入,增强了其感知细粒度图像信息的能力。因此,它在依赖细粒度感知能力的任务上表现出更好的性能。
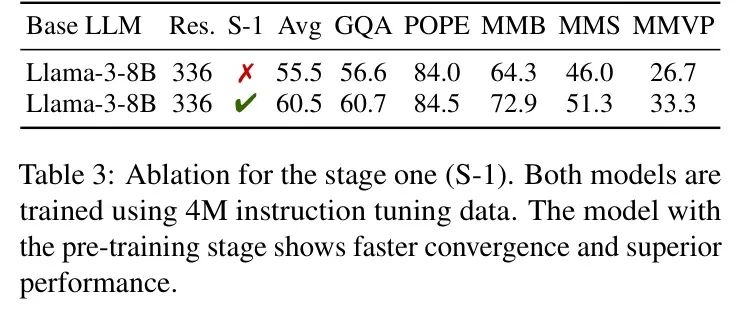
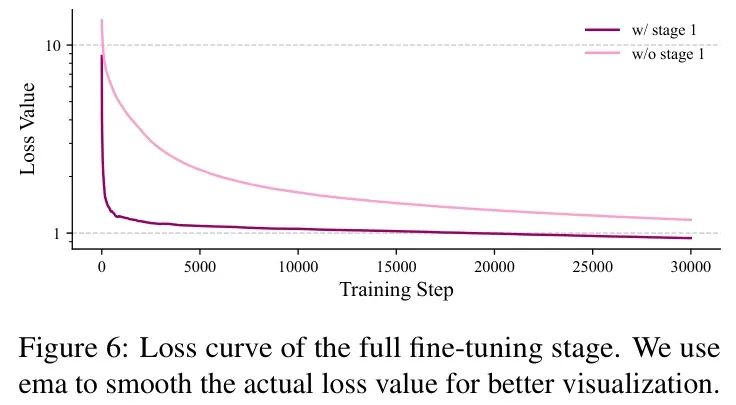
是否可以直接使用下一个 Token 预测损失?为了验证模态扩展的有效性,作者直接使用下一个 Token 预测损失优化模型,而没有经过第一阶段。如图6所示,模型在直接优化时收敛速度较慢,因为它必须同时执行模态融合和文本生成。相比之下,具有模态扩展阶段的模型收敛速度显著更快。此外,如表3所示,作者发现没有模态扩展阶段的模型性能下降了4.3%。
4.4 可视化研究
为了探究文本嵌入是否能够动态捕捉视觉线索,作者可视化了预解码器后文本嵌入与视觉嵌入之间的注意力图,如图5所示。观察可知,文本对更高相关性的区域表现出自动响应。例如,它对图像边缘的目标以及图像内的文本元素都表现出响应性。这些发现表明,作者单 Transformer 模型的早期融合机制对于细粒度感知任务是有效的,从而证实了表5中呈现的结果。

5. 结论
本工作提出了一种基于单一Transformer架构的多模态模型及其相应的有效训练方法。通过在早期阶段融合原始视觉和文本嵌入,HaploVL增强了其细粒度感知能力,使其能够更好地捕捉图像中的微妙关系。此外,HaploVL基于预训练的单模态模型的知识。这使得它能够在相对较少的训练 Token 下实现优异的性能,并缩小单Transformer多模态模型与组合模型之间的性能差距。
因此,它展示了单一Transformer架构在多模态任务中的潜力。作者期望作者的工作可以为未来关于单一Transformer多模态模型的研究奠定基础,为该领域提供新的见解和进步的机会。
参考
[1]. HaploVL: A Single-Transformer Baseline for Multi-Modal Understanding
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









