







Bridging Text and Knowledge with Multi-Prototype Embedding for Few-Shot Relational Triple Extraction 阅读笔记
Article
Bridging Text and Knowledge with Multi-Prototype Embedding for Few-Shot Relational Triple Extraction
Background
目前的监督学习关系抽取需要大量的标记数据,在样本较少时表现不佳。另外实体和关系间具有的隐式相关性,使得这个任务更具挑战性。少样本学习中,经过训练的模型可以从几个例子中快速学习到新的概念,并保持良好的泛化能力。因此,如果需要将关系三元组的抽取拓展到新领域,可以使用一些实例来激活系统而不需要重新训练模型,这种少样本学习方法可以显著降低标注成本和训练成本,同时保持较高的准确率。
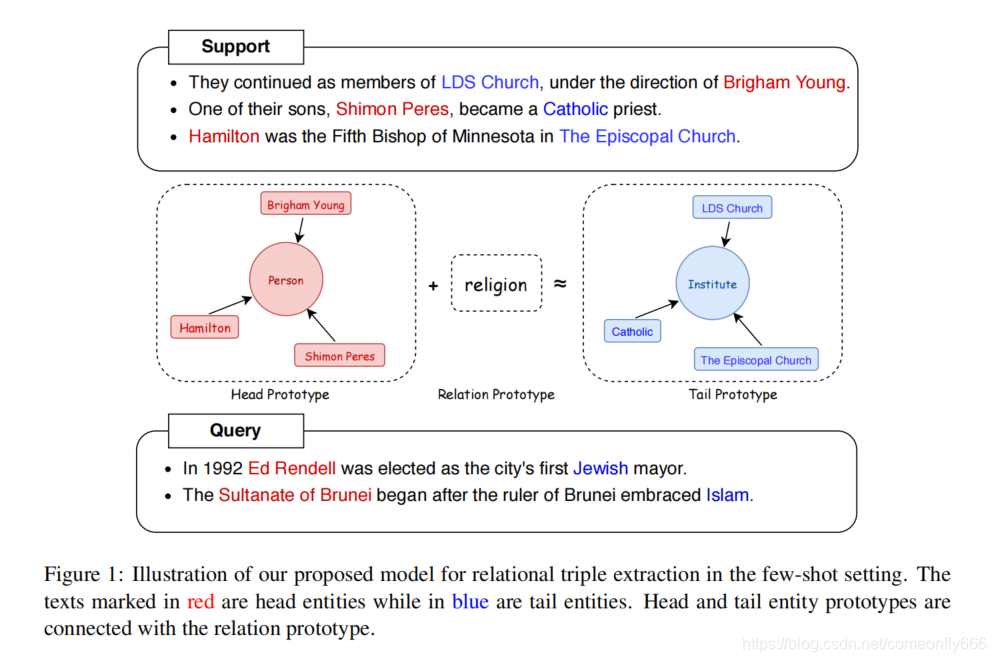
注意实体对和关系有显示的约束,例如born_in表明头实体是Person。
原型网络将每个类别中的样例数据映射到一个空间中,提取它们的“均值”来表示为该类的原型(prototype)。训练使得本类别数据到本类原型表示的举例为最近,到其他类原型表示的距离较远。
Purpose
作者提出了一个新的多原型嵌入网络模型(MPE),联合抽取关系三元组即实体对和对应关系。设计了一个混合原型学习机制,连接了关于实体和关系的文本和知识,学习实体对和关系之间的约束。另外作者还提出了知识感知正则化来引入外部知识图谱的先验知识,学习更多原型。引入原型正则化考虑不同原型之间的相似性。
Methodologies
Problem Definition
在少样本关系三元组抽取任务中,给定两个数据集 D m e t a − t r a i n D_{meta-train} Dmeta−train和 D m e t a − t e s t D_{meta-test} Dmeta−test,数据集中包含样本(x,t)的集合,其中x是包含N个单词的句子,t是抽取的关系三元组<head,relation,tail>。两个数据集具有彼此不相交的关系空间。测试集分为两部分: D t e s t − s u p p o r t D_{test-support} Dtest−support和 D t e s t − q u e r y D_{test-query} Dtest−query。由于实体对的类型可以由关系来确定(如Born_in能够确定Person和Location),所以可以通过指定关系类别来确定三元组的分类。
D t e s t − s u p p o r t D_{test-support} Dtest−support中的N个关系类每个包含K个样本,则成为N-way-K-shot问题。
受样本数量限制,使用 D t e s t − s u p p o r t D_{test-support} Dtest−support从头训练一个好的模型并评估其性能并非易事,因此作者将 D m e t a − t r a i n D_{meta-train} Dmeta−train也分为两个部分 D t r a i n − s u p p o r t D_{train-support} Dtrain−support和 D t r a i n − q u e r y D_{train-query} Dtrain−query,并在训练阶段模型少样本设置。
Framework
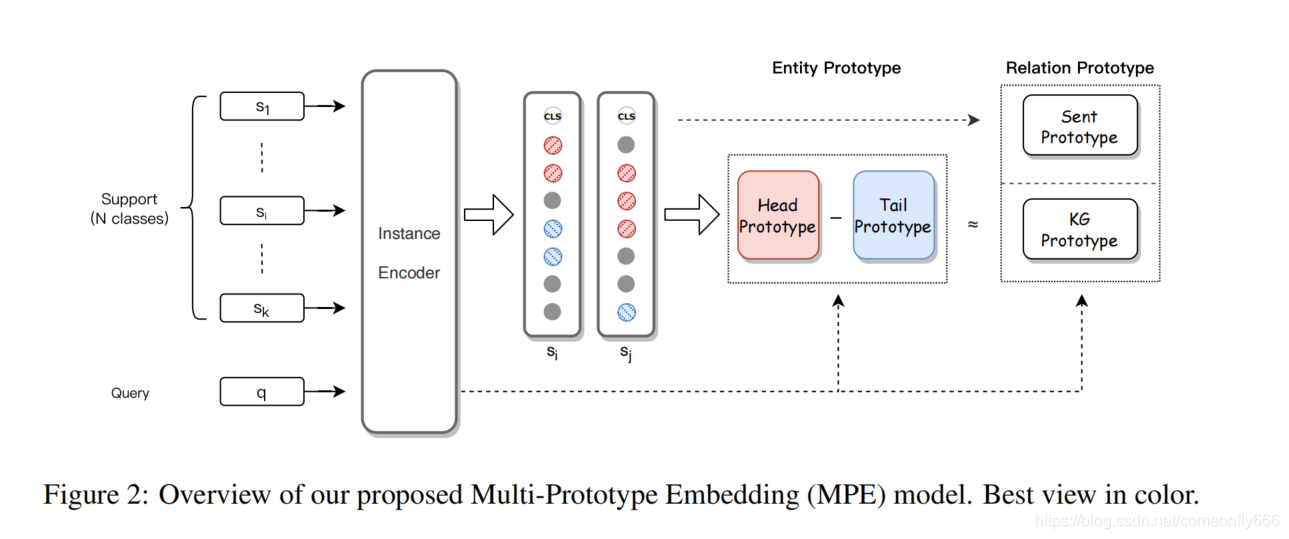
多原型嵌入模型框架如图2所示,主要包含3个模块:
-
实例编码。利用BERT/Roberta/XLNet预训练模型对句子进行编码。
-
混合原型学习。得到序列标注方法使用的实体对表示后,能够得到支撑集中的实体原型,然后基于知识图谱约束,并考虑实体对和关系的联系,构建关系原型。
-
原型感知正则化。为了进一步增强原型学习,优化了原型在表示空间中的位置。让每个原型和相关实例之间的距离更近,并分散那些不同类型的原型。
Instance Encoder
对每个句子x = { ω 1 \omega_1 ω1, ω 2 \omega_2 ω2,…, ω n \omega_n ωn},为了匹配BERT的输入格式,将其构建为 {[CLS], ω 1 \omega_1 ω1, ω 2 \omega_2 ω2,…, ω n \omega_n ωn,[SEP]}的格式,[CLS]用来表示整个句子信息。句子上下文嵌入B = { h 0 h_0 h0, h 1 h_1 h1, h 2 h_2 h2,…, h n h_n hn, h n + 1 h_{n+1} hn+1}, h 0 h_0 h0是[CLS]的词嵌入, h n + 1 h_{n+1} hn+1是[SEP]的词嵌入。由于分词器可能将单词拆分,n的值可能与输入句子长度不同。
Hybrid Prototypical Learning
建立实体标签集S = {B-Head,I-Head,B-Tail,I-Tail,O,X}。利用CRF进行序列标注,y = { y 0 y_0 y0, y 1 y_1 y1, y 2 y_2 y2,…, y n y_n yn, y n + 1 y_{n+1} yn+1}作为句子的标签,序列标注的损失记为 l o s s c r f loss_{crf} losscrf针对每一个实体,使用其第一个词表示作为头/尾嵌入。对支撑集中的每个类需要计算出一个代表向量,称为原型(prototype)。本文中使用的是带权值的原型,命名为Proto+Att网络,权值根据Q的表示向量,通过注意力机制获得。
h e a d p r o t o = 1 ∣ S k ∣ ∑ h e a d i ∈ S k α h h e a d i head_{proto} = \frac{1}{|S_k|}\sum_{head_i\in S_k}\alpha_hhead_i headproto=∣Sk∣1∑headi∈Skαhheadi
t a i l p r o t o = 1 ∣ S k ∣ ∑ t a i l i ∈ S k α h t a i l i tail_{proto} = \frac{1}{|S_k|}\sum_{tail_i\in S_k}\alpha_htail_i tailproto=∣Sk∣1∑taili∈Skαhtaili
其中
α h = exp ( e h i ) ∑ m = 1 k exp ( e h m ) \alpha_{h} =\frac{\exp \left(e_{h_{i}}\right)}{\sum_{m=1}^{k} \exp \left(e_{h_{m}}\right)} αh=∑m=1kexp(ehm)exp(ehi)
e h i = head proto T Q e_{h_{i}}=\operatorname{head}_{\text {proto }}^{T} Q ehi=headproto TQ
α t = exp ( e t j ) ∑ n = 1 k exp ( e t n ) \alpha_{t} = \frac{\exp \left(e_{t_{j}}\right)}{\sum_{n=1}^{k} \exp \left(e_{t_{n}}\right)} αt=∑n=1kexp(etn)exp(etj)
e t j = tail proto T Q e_{t_{j}}=\operatorname{tail}_{\text {proto }}^{T} Q etj=tailproto TQ
采用欧几里得距离作为实体原型和实例之间的距离,最小化该距离的损失为 l o s s e n i t i t y loss_{enitity} lossenitity。
对于关系原型,一方面,利用[CLS]计算句子原型 s e n t p r o t o sent_{proto} sentproto;另一方面,根据在低维空间中的向量表示 h + t ≈ r h+t\approx r h+t≈r,使用头尾实体原型构建知识图谱原型
k g p r o t o = ∣ h e a d p r o t o − t a i l p r o t o ∣ W r kg_{proto} = |head_{proto}-tail_{proto}|W_r kgproto=∣headproto−tailproto∣Wr
结合之后形成关系原型
r e l a t i o n p r o t o = [ s e n t p r o t o ; k g p r o t o ] relation_{proto} = [sent_{proto};kg_{proto}] relationproto=[sentproto;kgproto]
最小化距离的损失为 l o s s r e l a t i o n loss_{relation} lossrelation。
Prototype-Aware Regularization
如果一个类中的支持实例距离都很远,将导致原型很难捕获其共同特征。因此作者提出原型感知正则化来优化原型学习。使用欧氏距离和余弦距离来度量相似性,损失函数如下:
l o s s i n t r a = 1 N K ∑ i = 1 N ∑ k = 1 K ∣ ∣ x i k − p i k ∣ ∣ 2 2 loss_{intra} = \frac{1}{NK}\sum_{i=1}^N \sum_{k=1}^K||x_i^k-p_i^k||_2^2 lossintra=NK1∑i=1N∑k=1K∣∣xik−pik∣∣22
l o s s i n t e r = 1 − 1 N ∑ i = 1 N ∑ j = i + 1 N c o s i n e ( p i , p j ) loss_{inter} = 1-\frac{1}{N}\sum_{i=1}^N \sum_{j=i+1}^Ncosine(p_i,p_j) lossinter=1−N1∑i=1N∑j=i+1Ncosine(pi,pj)
其中 x i x_i xi是每个句子的表示, p i p_i pi是相关原型, l o s s i n t r a loss_{intra} lossintra和 l o s s i n t e r loss_{inter} lossinter是两个不同原型感知正则化函数。总正则化损失为 l o s s r e g u l a r = l o s s i n t r a + α l o s s i n t e r loss_{regular} = loss_{intra} + \alpha loss_{inter} lossregular=lossintra+αlossinter
总的损失为 L = l o s s c r f + β l o s s e n t i t y + γ l o s s r e l a t i o n + δ l o s s r e g u l a r L = loss_{crf}+\beta loss_{entity}+\gamma loss_{relation}+\delta loss_{regular} L=losscrf+βlossentity+γlossrelation+δlossregular
Experiments
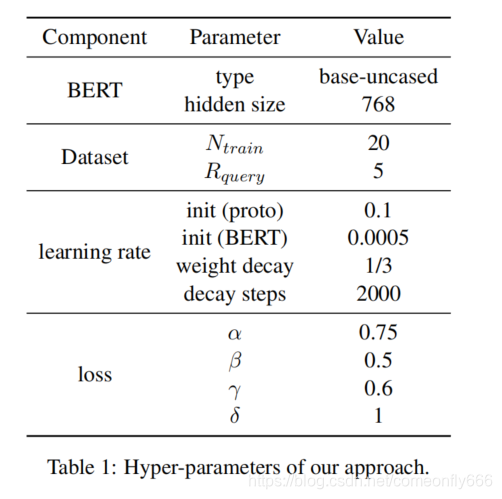
采用公共数据集FewRel,有80种关系,每个关系有700个样本。随机挑选50种关系训练,15种关系验证,剩下的15种关系用来测试。超参数设置如表1:
结果如表2.
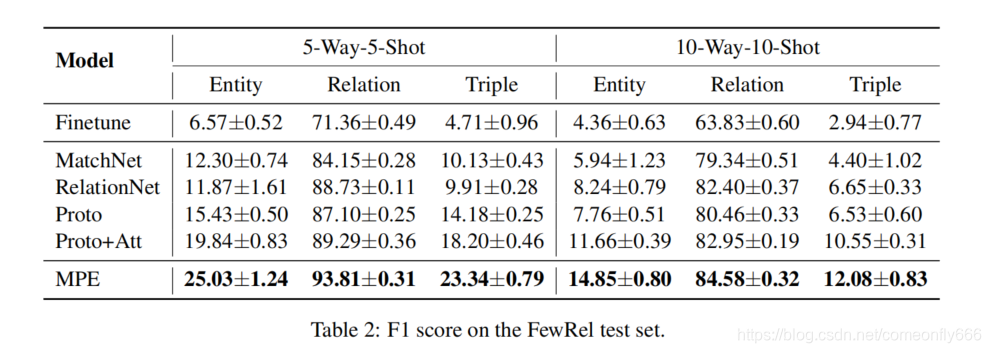
与所有基线相比,MPE具有最好的性能,证明了多原型利用文本和知识是有效的;在少样本学习中,实体识别表现的比关系抽取差了很多,原因在于序列标注比分类任务更具挑战性;Proto+Att比Proto表现的更好,说明不同实例对原型学习有不同的影响。

观察表4,例1说明本文的方法在类似的上下文表示中,只在细粒度实体类型上有所不同的任务中表现不好,这可能是由于模型倾向于将具有相似上下文的句子分类为高频关系的不平衡学习问题导致的。例2是错误的边界问题,问题在于序列标注具有的挑战性。例3是错误的三元组问题,作者观察到,许多三元组中的实体并不在标准数据集中,这可能是由于一个句子中含有多个三元组,而FewRel并没有对其进行标记。
Conclusion
本文中作者研究了少样本关系三元组抽取问题,提出了一种新的多原型嵌入网络,桥接了文本表示学习和知识约束。大量的实验证明了模型的有效性,但在实体识别方面表现较差,且不能在一个句子中提取多个三元组,存在上下文干扰问题。未来工作中,将包括1)利用有效的序列解码器提高实体识别的性能;2)研究单个句子中具有多个三元组的少样本关系三元组抽取问题;3)注入逻辑规则,提升鲁棒性4)开发少样本关系三元组抽取基准测试。














 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









