







Quantifying the Significance and Relevance of Cyber-Security Text Through Textual Similarity and Cyber-Security Knowledge Graph阅读笔记
Purpose
本文提出了一种新的方法从文本中识别特定用户的内容,通过将文本与已知重要文本的向量表示比较,使用NER识别网络安全实体,并将其与现有的CKG关联,着重于量化非结构化文本中包含的威胁信息的重要性和相关性。将文本相似度和文本中的实体与CKG的相关性作为威胁信息的特征,将这些特征作为分类器的输入,生成一个量化文本重要性和相关性的分数。
Proposed Autonomous Systems
Proposed System Architecture
作者之前提出了一个从公开信息源识别威胁信息的系统,在原基础上修改后,架构如图1。

Natural Language Filter模块分类过滤出网络安全相关的文本文档,Analyzer模块确定其重要性和相关性,重要文本通过Cybernetics-security Relation Extractor抽取有用的信息丰富CKG,从而提升后续文档的相关性特征。
Natural Language Filter Module
通过使用超过100万个安全文本文档进行训练,比较输入的文本文档与训练文档的向量表示的余弦相似度,过滤掉小于70%的文档。
Analyzer Module
作者认为文本的重要性可以通过识别文本与预定义的重要文本的相似性确定,相关性可以通过文本中提及的实体与感兴趣的术语的相关性确定。这些特征可以用来产生一个独特的数字表示文本的重要性和相关性,框架结构如图2。

Similarity Analyzer 用向量表示文本,对于同一个单词,向量的不同分量可以表示不同的意思。
Cyber-security Knowledge Graph Analyzer 用CKG推断用户关注的实体与提及实体之间的相关性。
Significance Score Calculator 根据输入(与预定义重要文本最接近的相似度得分 + 关注的实体与提及实体之间的相关性特征),输出固定范围的数字。
Implementation
Data Used
MalwareTextDB:由85份APT报告组成,本文中简称MWTDB。

CVE repository:通用漏洞披露,简称CVE。
StackExchange discussions:各种主体的问答网站,简称为SE。
Security news outlet RSS feeds:网络安全信息摘要,简称RSS。
Similarity Analyzer
为计算文本相似度,需要将文本转换为向量,本文使用谷歌提出的Universal Sentence Encoder (USE)作为向量表示模型。
1)Universal Sentence Encoder
基于transformer和深度平均网络(DAN)模型,将句子转换为向量嵌入。USE将变长的英语句子作为输入,输出512维向量。
2)Implementation of Similarity Analyzer
使用USE生成参考文本中每个条目的初始256字节的向量表示,将它们存储在数据库中(尽管USE可以处理不同长度的文本,但比较相同长度的文本时会获得更好的文本相似性)。表1显示了不同参考文本库之间的最大余弦相似度。根据重要性不同,为存储库分配了相应权重。

与参考文本库类似,USE从输入文本提取256个字符,并转换为向量表示,计算与存储库每个条目的余弦相似度,选每个库的最高相似度得分,过程如图3。

Cyber-Security Knowledge Graph Analyzer
1)Cyber-Security Knowledge Graph
利用CVE描述构建知识图谱,为每个关系类型设定一个独特的数字作为cost,该cost也被用来计算节点间的最短距离。
2)NER
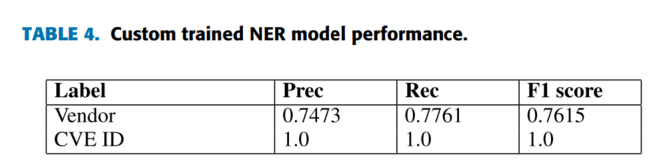
由于在非结构化文本中区分IT product和IT vendor十分困难,将product和vendor都定义为Vendor类。命名实体识别采用Stanford NER模型,各标签性能如表4。可以看出,由于CVE ID的标准化结构,可以完全正确识别。
3)Implementation of Cyber-Security Knowledge Graph Analyzer
作者提出,利用节点数、边数和总代价等相似度量来定义实体的相关性。Entities of Interest(EI)被定义为与用户相关的实体,文本中抽取的实体被标记为Mentioned Entities(ME)。过程如下

Conclusion
本文提出了一种新的方法来量化非结构化文本的相关性和重要性,通过与预定义的重要文本计算相似度确定重要性,利用CKG计算实体的相关性,为此训练了一个自定义NER模型,构建了一个CKG。
未来将抽取非结构化文本中的关系,构建更全面的网络安全知识图谱。















 1593
1593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









