









 本文详细介绍了Spring Data MongoDB的聚合操作,包括Aggregate的简介、Pipeline参数及其应用场景,如$project、$match、$limit、$skip、$unwind和$out等。文章通过实例展示了如何在MongoDB中执行聚合管道,并提到了AggregationOutput在MongoDB集成中的应用。
本文详细介绍了Spring Data MongoDB的聚合操作,包括Aggregate的简介、Pipeline参数及其应用场景,如$project、$match、$limit、$skip、$unwind和$out等。文章通过实例展示了如何在MongoDB中执行聚合管道,并提到了AggregationOutput在MongoDB集成中的应用。
一、Aggregate简介
db.collection.aggregate()是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。

1、db.collection.aggregate()可以多个管道,能方便的进行数据的处理。
2、db.collection.aggregate()使用了MongoDB内置的原生操作,聚合效率非常高,支持类似于SQL Group By操作的功能,而不再需要用户编写自定义的JavaScript例程。
3、 每个阶段管道限制为100MB的内存。如果一个节点管道超过这个极限,MongoDB将产生一个错误。为了能够在处理大型数据集,可以设置allowDiskUse为true来在聚合管道节点把数据写入临时文件。这样就可以解决100MB的内存的限制。
4、db.collection.aggregate()可以作用在分片集合,但结果不能输在分片集合,MapReduce可以 作用在分片集合,结果也可以输在分片集合。
5、db.collection.aggregate()方法可以返回一个指针(cursor),数据放在内存中,直接操作。跟Mongo shell 一样指针操作。
6、db.collection.aggregate()输出的结果只能保存在一个文档中,BSON Document大小限制为16M。可以通过返回指针解决,版本2.6中后面:DB.collect.aggregate()方法返回一个指针,可以返回任何结果集的大小。
二、Aggregate pipeline 参数
今天主要是pipeline 运用到Spring上:
【pipeline 参数】
pipeline 类型是Array 语法:db.collection.aggregate( [ { <stage> }, ... ] )
$project:可以对输入文档进行添加新字段或删除现有的字段,可以自定哪些字段显示与不显示。
$match :根据条件用于过滤数据,只输出符合条件的文档,如果放在pipeline前面,根据条件过滤数据,传输到下一个阶段管道,可以提高后续的数据处理效率。还可以放在out之前,对结果进行再一次过滤。
$limit :用来限制MongoDB聚合管道返回的文档数
$skip :在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind :将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$out :必须为pipeline最后一个阶段管道,因为是将最后计算结果写入到指定的collection中。
$group : 将集合中的文档分组,可用于统计结果,$group首先将数据根据key进行分组。
MongoDB上对 pipeline 操作可以查看
学习MongoDB 十一: MongoDB聚合(Aggregation Pipeline基础篇上)(三)
学习MongoDB 十二: MongoDB聚合(Aggregation Pipeline基础篇-下)(四)
三、举例子并在MongoDB操作pipeline
db. orders.insert([
{
"onumber" : "001",
"date" : "2015-07-02",
"cname" : "zcy1",
"items" :[ {
"ino" : "001",
"quantity" :2,
"price" : 4.0
},{
"ino" : "002",
"quantity" : 4,
"price" : 6.0
}
]
},{
"onumber" : "002",
"date" : "2015-07-02",
"cname" : "zcy2",
"items" :[ {
"ino" : "003",
"quantity" :1,
"price" : 4.0
},{
"ino" : "002",
"quantity" :6,
"price" : 6.0
}
]
},{
"onumber" : "003",
"date" : "2015-07-02",
"cname" : "zcy2",
"items" :[ {
"ino" : "004",
"quantity" :3,
"price" : 4.0
},{
"ino" : "005",
"quantity" :1,
"price" : 6.0
}
]
},{
"onumber" : "004",
"date" : "2015-07-02",
"cname" : "zcy2",
"items" :[ {
"ino" : "001",
"quantity" :3,
"price" : 4.0
},{
"ino" : "003",
"quantity" :1,
"price" : 6.0
}
]
}
])> db.orders.aggregate([
... {$match:{"onumber":{$in:["001","002", "003"]}}},
... {$unwind:"$items"},
... {$group:{_id:"$items.ino",total:{$sum:"$items.quantity"}}},
... {$match:{total:{$gt:1}}}
... ]);
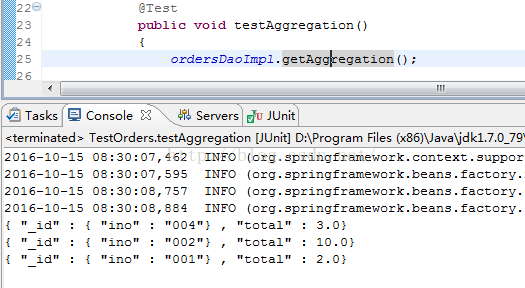
{ "_id" : "004", "total" : 3 }
{ "_id" : "002", "total" : 10 }
{ "_id" : "001", "total" : 2 }四、AggregationOutput
Spring Data MongoDB 项目提供与MongoDB文档数据库的集成。如果对环境的搭建不清楚可以先看
我们先介绍Mongo本身提供的com.mongodb.AggregationOutput进行分组查询,下一篇会介绍Spring Data MongoDB模板封装的Aggregation方法,我们直接看代码

@Override
public void getAggregation() {
Set<String> onumberSet=new HashSet<String>();
onumberSet.add("001");
onumberSet.add("002");
onumberSet.add("003");
//过滤条件
DBObject queryObject=new BasicDBObject("onumber", new BasicDBObject("$in",onumberSet));
DBObject queryMatch=new BasicDBObject("$match",queryObject);
//展开数组
DBObject queryUnwind=new BasicDBObject("$unwind","$items");
//分组统计
DBObject groupObject=new BasicDBObject("_id",new BasicDBObject("ino","$items.ino"));
groupObject.put("total", new BasicDBObject("$sum","$items.quantity"));
DBObject queryGroup=new BasicDBObject("$group",groupObject);
//过滤条件
DBObject finalizeMatch=new BasicDBObject("$match",new BasicDBObject("total",new BasicDBObject("$gt",1)));
AggregationOutput output=mongoTemplate.getCollection("orders").aggregate(queryMatch,queryUnwind,queryGroup,finalizeMatch);
for (Iterator<DBObject> iterator = output.results().iterator(); iterator.hasNext();) {
DBObject obj =iterator.next();
System.out.println(obj.toString());
}
}public class TestOrders {
private static OrdersDao ordersDaoImpl;
private static ClassPathXmlApplicationContext app;
@BeforeClass
public static void initSpring() {
try {
app = new ClassPathXmlApplicationContext("classpath:applicationContext-mongo.xml");
ordersDaoImpl = (OrdersDao) app.getBean("ordersDaoImpl");
} catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void testAggregation()
{
ordersDaoImpl.getAggregation();
}
}


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











