






数据结构与算法
一、算法基础理论和复杂度分析:
https://www.bilibili.com/video/BV1nJ411V7bd——前几节
二、数组和字符串-2022.10.3-晚
(一)一维数组简介
集合定义:由一个或多个确定的元素所构成的整体。
列表定义:一种数据项构成的有限序列,即按照一定的线性顺序,排列而成的数据项的集合。(常见列表有数组、链表,较特殊的有栈、队列)
宏观上区分列表和数组:
- 数组可利用索引(index)来标识数据位置
- 数组中的元素在内存中是连续存储的,且每个元素占用相同大小的内存
1、寻找数组的中心下标
(0)前置想法
在思考Leedcode的官方题解并没有Python版本,从此大多寻求网上大佬。😂很多时候其实前面的定义不大看得懂。
(1)算法思路
前缀和等于后缀和,一个循环判断,将前缀和数组优化成一个递增中的数值,使得空间复杂度为O(1),时间复杂度为O(n)。
class Solution:
def pivotIndex(self,nums:List[int]) -> int:
sz=len(nums)
total=sum(nums)
pre_sum=0
for i in range(sz):
pre_sum += nums[i]
if pre_sum-nums[i]==total-pre_sum:
return i
return -1
2、搜索插入位置
(1)思路
题目要求算法复杂度为O(logn),因此打算采用二分法来实现。
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
left, right = 0, len(nums) - 1
while left <= right:
middle = (left + right) // 2
if nums[middle] < target:
left = middle + 1
elif nums[middle] > target:
right = middle - 1
else:
return middle
return right + 1
3、合并区间-2022.10.4早
(1)思路
依次进行区间左端点排序
(2)算法
若 intervals[i][0] < intervals[i-1][0] 即判断是否重复。创建一个新区间 result ,将合并区间的左右边界作为一个新区间放入该数组中,若判断无合并则把原区间加入到result数组中。
class Solution:
def merge(self,intervals:List[List[int]]) ->List[List[i]]:
if len(intervals) == 0: return intervals
# xxx.sort(key=lambda x:x[0])代表着对xxx的区间元素的第一字段值进行升序排序,若此时填入 reserve=True 则可以实现降序排序。
intervals.sort(key=lambda x: x[0])
result = []
result.append(intervals[0])
for i in range(1, len(intervals)):
last = result[-1]
if last[1] >= intervals[i][0]:
result[-1] = [last[0], max(last[1], intervals[i][1])]
else:
result.append(intervals[i])
return result
(二)二维数组简介
1、旋转矩阵
(1)思路
以等距圆周为一单位,二维数据旋转,但彼此间数据关系很难找到。一次查阅后得知位于(i,j)处的元素旋转后位于倒数第i列的第j个位置。
(2)算法
class Solution:
def rotate(self,matrix:List[List[int]]) -> None:
n=len(matrix)
# 初始化一下matrix_new,其中用法可以学一学!
matrix_new=[[0]*n for _ in range(n)]
for i in range(n):
for j in range(n):
matrix_new[j][n-i-1]=matrix[i][j]
# 不额外输出,替换原来的矩阵
matrix[:]=matrix_new
额外提一句,好多报错是由于简单语句的空格问题😅
2、零矩阵
(1)思路
使用标记矩阵,遍历原矩阵并将0元素的行列所对应的标记矩阵位置置为true。
(2)算法
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
# 初始化一下
m, n = len(matrix), len(matrix[0])
row, col = [False] * m, [False] * n
for i in range(m):
for j in range(n):
if matrix[i][j] == 0:
row[i] = col[j] = True
for i in range(m):
for j in range(n):
if row[i] or col[j]:
matrix[i][j] = 0
3、对角线遍历
(1)思路
M×M矩阵的位置i,j相加的区间为(0,2*(m-1)) ,只要判断i+j=k,同一个k就是要输出的数据集。
(2)算法
version1:
class Solution:
def findDiagonalOrder(self, mat: List[List[int]]) -> List[int]:
m=len(mat) # 列数
n=len(mat[0]) # 行数
result=[]
for t in range(m+n-1):
if t % 2 == 1 :
for i in range(m):
for j in range(n):
if i+j == t:result.append(mat[i][j])
else:
for j in range(n):
for i in range(m):
if i+j == t:result.append(mat[i][j])
return result
评:上面这个调了许久,但是明显时间复杂度高了太多😱三个循环直接O(n^3)
leetcode 上面的改进版,秒呀😍
class Solution:
def findDiagonalOrder(self, mat: List[List[int]]) -> List[int]:
# 单行初始化确实简洁
m, n, ans = len(mat), len(mat[0]), []
# ↓大佬就是大佬,思想跟我version1差不多,但是表达起来就差蛮大的
for k in range(m + n - 1):
if not k % 2:
ans += [mat[x][k-x] for x in range(min(m - 1, k), max(-1, k - n),-1)]
else:
ans += [mat[x][k-x] for x in range(max(0, k - n + 1), min(k + 1, m))]
return ans
基于上面的思想,我调整了循环个数和区间,缩了点时间复杂度👍👍👍👍
class Solution:
def findDiagonalOrder(self, mat: List[List[int]]) -> List[int]:
m,n,result=len(mat),len(mat[0]),[]
for t in range(m+n-1):
if t % 2 :
for i in range(min(t+1,m)):
if (t-i)<n : result.append(mat[i][t-i])
else:
for j in range(min(t+1,n)):
if (t-j)<m :result.append(mat[t-j][j])
return result
(三)字符串简介
字符串的操作大多需要以子串为整体,因此逆序或连接并不像数组一样简单。
1、最长公共前缀
(1)思路
依次迭代更新最长公共前缀
(2)算法
第一种是横向扫描:依次遍历每个字符串(不知道为什么leetcode实现不了?)
class Solution:
def longestCommonPrefix(self,strs:List[str])->str:
if not strs:return ""
# count代表字符串数组中字符的个数
prefix,count=strs[0],len(strs)
# 实现依次迭代,同样发现是空则直接返回为空
for i in range(1,count):
prefix=self.lcp(prefix,strs[i])
if not prefix:
break
return prefix
def lcp(self,str1,str2):
length,index=min(len(str1),len(str2)),0
while index<length and str1[index]==str2[index]:
index +=1
return str1[:index]
第二种是纵向扫描,比较各个字符串相同列上的字符是否相同
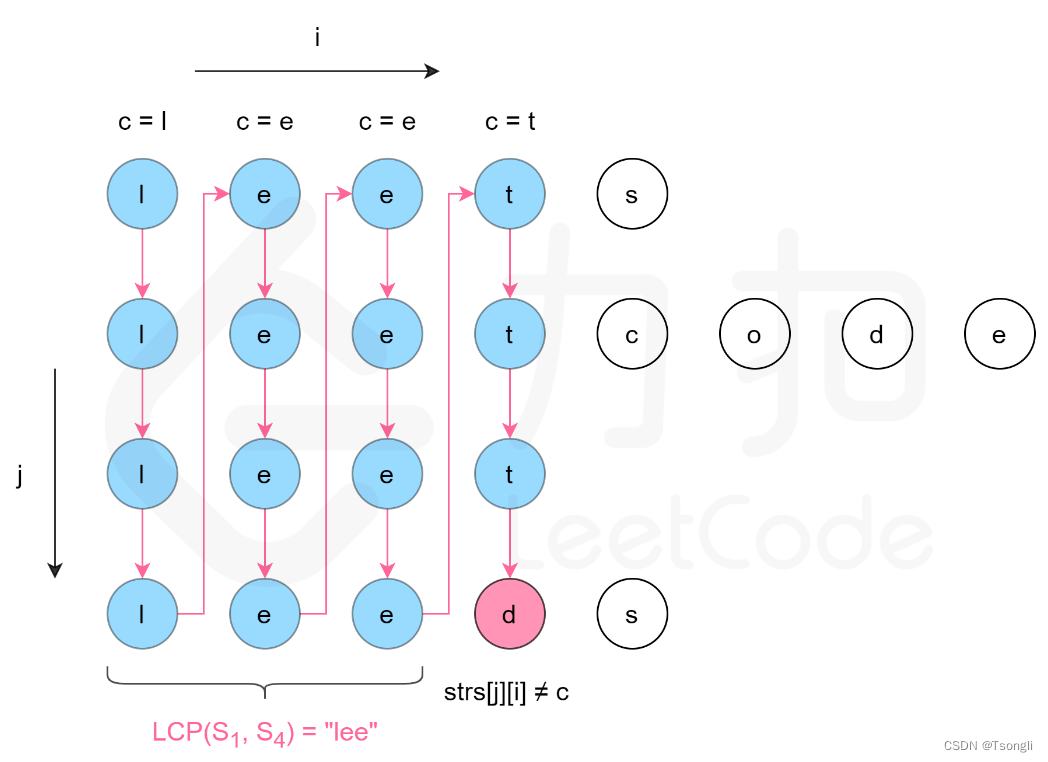
class Solution:
def longestCommonPrefix(self,strs:List[str])->str:
if not strs:
return ""
length, count = len(strs[0]), len(strs)
for i in range(length):
c=strs[0][i]
if any(i == len(strs[j]) or strs[j][i] != c for j in range(1,count)):
return strs[0][:i]
return strs[0]
注:像这种 any(i == len(strs[j]) or strs[j][i] != c for j in range(1,count))这种伴随简短的 for循环更专业
!同样的空格又让我吃大坑😇
三、链表⭐️
(一)单链表
单链表中每个结点不仅包含值,还包含链接到下一个结点的引用字段 。
结点结构
# A single node of a singly linked list
class Node:
def __init__(self,data,next=None):
self.data=data
self.next=next
与数组相比,链表在通过索引访问数据时性更加糟糕,复杂度为O(N)
1、设计链表
(二)双指针技巧
(三)经典问题
(四)双链表-2022.10.11晚
基本结构 = prev 前字段 + val值字段 +next后续字段















 1540
1540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









