







先占位,这两天传文件
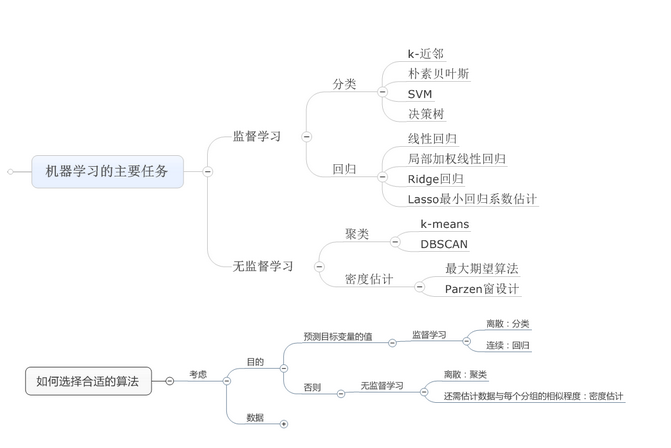
监督学习:
例子1:
假设你有下面这些房价数据,图表上的每个实例都是一次房屋交易,横坐标为交易房屋的占地 面积,纵坐标为房屋的交易价格。
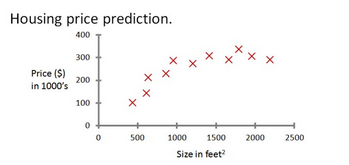
现在,假设你希望能够预测一个 750 平方英尺的房屋的交易价格可能是多少。一种方法是根据 这些数据点的分布,画一条合适的直线,然后根据这条直线来预测。在房价预测这个例子中, 一个二次函数可能更适合已有的数据,我们可能会更希望用这个二次函数的曲线来进行预测。
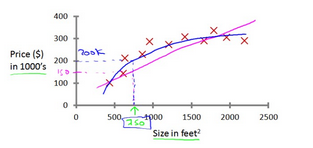
上面这个问题又称为回归问题(Regression),因为我们能预测的结果是连续地值。
例子2:
假使你希望预测一个乳腺癌是否是恶性的,你现在有的数据是不同年龄的病人和她们身上肿瘤 的尺寸以及这些肿瘤是否是恶性的。如果我们将这些信息绘制成一张 2D 图表,以横坐标为肿 瘤的尺寸,以纵坐标为病人的年龄,以 O 代表良性肿瘤,以 X 代表恶性肿瘤。则我们的算法 要学习的问题就变成了如何分割良性肿瘤和恶性肿瘤。
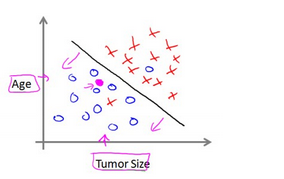
这样的问题是分类问题(Classification),我们希望算法能够学会如何将数据分类到不同的类 里。 上面的例子中我们只适用了两个特征(features)来进行分类,现实中,我们会有非常多的特 征,并且我们希望算法能够处理无限多数量的特征,在课程后面我们会介绍能够处理这样问题 的算法,例如支持向量机(Support Vector Machine)。
在监督学习中,无论是回归问题还是分类问题,我们的数据都具有一个结果(房价问题中的房价,肿瘤问题中的良性与否)。
在监督学习中,无论是回归问题还是分类问题,我们的数据都具有一个结果(房价问题中的房价,肿瘤问题中的良性与否)。
非监督学习:
非监督学中,我们的现有数据中并没有结果,我们有的只是特征,因而非监督学习要解决的问题是发现这些数据是否可以分为不同的组。
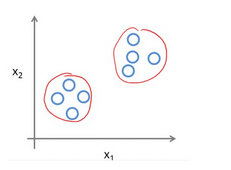
例子1:
聚类问题
例子2:
鸡尾酒会问题(Cocktail Party Problem)
在一个满是人的房间中,人们都在互相对话,我们使用一些麦克风录下房间中的声音,利用非监督学习算法来
识别房间中某一个人所说的话。
在一个满是人的房间中,人们都在互相对话,我们使用一些麦克风录下房间中的声音,利用非监督学习算法来
识别房间中某一个人所说的话。
鸡尾酒会问题的一个简化版本是一个房间中有两个人在同时在讲话,利用两个麦克风来录音。

注:
监督学习:这类算法必须知道要预测是什么,即目标变量的分类信息
非监督学习:这类数据无类别信息,也不会给定没目标值
机器学习基本步骤:
收集数据
准备数据
分析数据
训练数据(无监督学习是不需要的)
测试算法
使用算法















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









